
获取电子邮件是个轻松简单的步骤,但获取到的是邮件原始内容,其内容格式通常遵守MIME协议(多用途互联网邮件扩展)
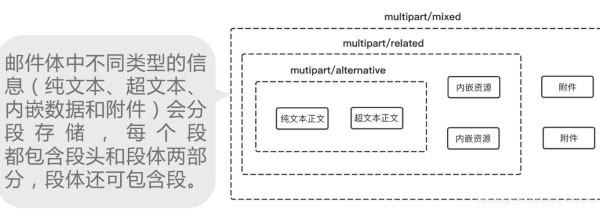
一封邮件通常会分为邮件头与邮件体,邮件头中存在着这份邮件的基本信息,而邮件体则是邮件的具体内容

import poplib
from email.parser import Parser
from email.header import decode_header
#连接邮箱服务器
def connect_email():
user = 'xxx' #邮箱地址
password = 'xxx' #开启服务密码,上一篇博客介绍过
pop3_server = 'pop.126.com'
#开始连接到服务器
server = poplib.POP3(pop3_server)
#打开或关闭调试信息
server.set_debuglevel(1)
#打印POP3服务器的欢迎文字
print(server.getwelcome().decode('utf-8'))
#开始进行身份验证
server.user(user=user)
server.pass_(password)
return server
#获取邮件内容
def get_email_content(server):
email_num, email_size = server.stat()
rsp, msglines, msgsize = server.retr(email_num)
msg_content = b'\r\n'.join(msglines).decode('gbk')
msg = Parser().parsestr(msg_content)
server.close()
return msg
#邮件头解析
def parser_subject(msg):
subject = msg['Subject']
value, charset = decode_header(subject)[0]
if charset:
value = value.decode(charset)
return value
def guess_charset(msg):
charset = msg.get_charset()
if not charset:
content_type = msg.get('Content-Type', '').lower()
pos = content_type.find('charset=')
if pos >= 0:
charset = content_type[pos + 8: ].strip()
return charset
#邮件体解析
def parser_content(msg, indent=0):
if msg.is_multipart():
parts = msg.get_payload()
for n, part in enumerate(parts):
print(f"{' ' * indent * 4} 第{n+1}部分")
print(f"{' ' * indent * 4} {'-'*50}")
parser_content(part, indent+1)
else:
content_type = msg.get_content_type()
if content_type == 'text/plain' or content_type == 'text/html':
content = msg.get_payload(decode=True)
charset = guess_charset(msg)
if charset:
content = content.decode(charset)
print(f"{' ' * indent * 4} 邮件内容:{content}")
else:
print(f"{' ' * indent * 4} 附件内容:{content_type}")
def main():
server = connect_email()
msg = get_email_content(server)
subject = parser_subject(msg)
print(subject)
parser_content(msg)
if __name__ == '__main__':
main()

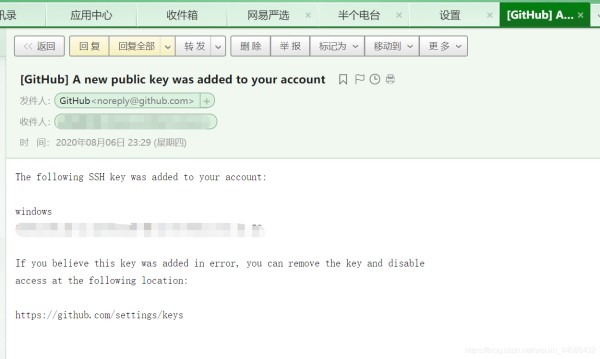 运行结果是这样的:因为这个邮件没有包含多层嵌套,因此没有打印出第{n+1部分}。
运行结果是这样的:因为这个邮件没有包含多层嵌套,因此没有打印出第{n+1部分}。


