背景
接口自动化一直以来都是质量保障的重要一环,在接口自动化日常工作中,我们致力于场景的覆盖与结果校验。随着业务的高速发展,高效保质的迭代自动化用例成了我们的一个研究方向,其中用例结果校验的及时性、完整性、可维护性是我们遇到的一个很大的难题。
痛点
笔者所属团队,日常工作是围绕商品相关业务展开。在平时的自动化脚本编写中,我们发现:
商品模型返回字段多(一个模型一般有几十到上百个字段),逐字段人工断言,成本较高; 商品原自动化工程里有大量重复的校验逻辑,梳理成本较高; 随着业务发展部分非核心字段逐渐也变成了核心字段,例如商品编码,现在已经成为了很多商家ERP系统识别商品数据的关键标识; 部分字段更新如何保证其他字段没有被更新掉,尤其是一些存在默认值的字段,更新的时候极易被默认值覆盖。传统校验方式我们一般只会校验核心字段或者用例相关字段,比如:价格、库存等等。但是基于上述第3、4点原因,我们发现需要去做全字段校验,而全字段校验学习成本高、维护代价大、代码熟悉程度要求高是面临的三大难题,那么如何做到快速、优雅全字段校验成为我们必须去解决的问题。
目标
我们的目标是争取对用例返回字段进行全量校验,同时也要大幅提升用例编写效率。
场景分析
我们对现有的自动化用例场景进行分析,得到以下结论:
待测试的后端接口一般分为操作接口和查询接口两类; 一个操作类接口落库后的数据一般会对应一个或者多个查询类接口; 查询类接口会返回大量业务字段。接下来我们分别针对操作、查询这两类接口进行处理。
实践前的准备
为了让大家更好的理解后续内容,我们先对有赞目前的测试环境进行一个概述:(详细内容可参见:有赞环境解决方案),环境示意图如下:
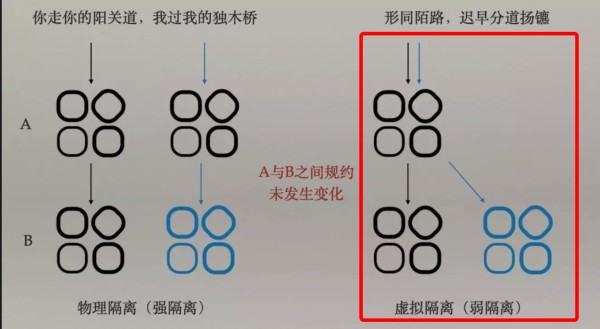
目前有赞测试环境采取的是弱隔离策略,分为基础环境和测试环境。基础环境部署应用的代码分支版本同线上一致,项目环境部署的则是应用特性分支代码,两个环境共用一套存储。当一个业务请求进来时,根据一个标志位(内部简称sc)来判定是否要走到项目环境,如果请求的是项目环境且项目环境有该应用,那么此请求会被路由到项目环境中,否则请求到基础环境里。
实践
下面介绍一下我们整体思路:
读接口校验:分别请求基础环境和项目环境,对比两个环境的返回结果,如果一致说明代码改动对此接口用例没有影响,进而可以判定用例校验通过; 写接口校验:一般写接口落库的数据可以通过一个或者多个读接口拿到,那么同样的写接口分别在基础环境和项目环境进行落库,只要对应环境的读接口返回结果一致,那么校验通过; 不论读写,都有一些随机字段,为了降低接入成本,需要提供计算忽略字段能力。读接口校验思路
读接口校验相对简单,分别请求基础环境和项目环境,根据返回值的异同来判定用例是否通过。 我们可以借鉴AOP的思路,切入点为dubbo请求前后,在切面中分别请求基础环境和sc环境,根据两次返回值来判定用例是否通过。
整体流程如下:
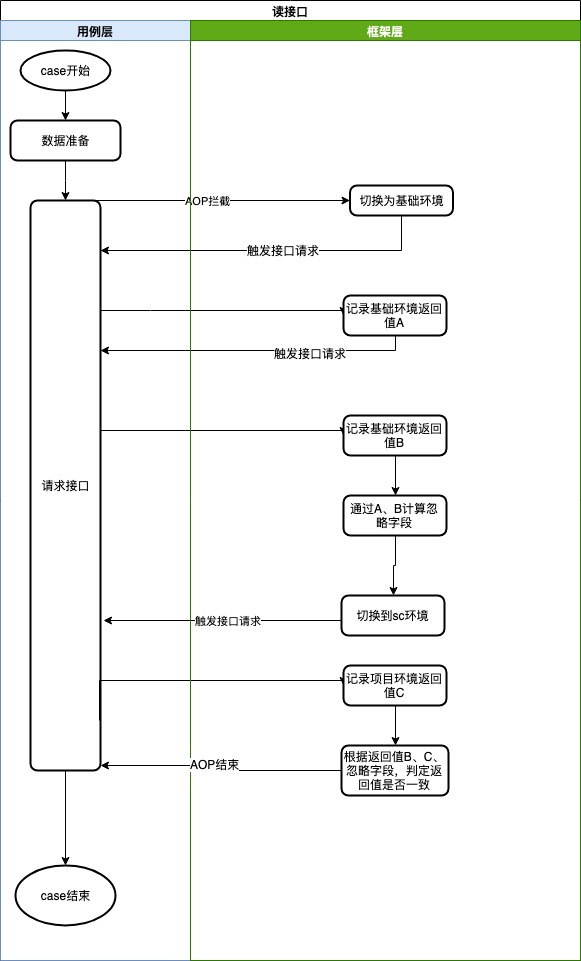 PS:sc环境即为部署了应用特性分支代码的环境
PS:sc环境即为部署了应用特性分支代码的环境
根据上述流程图,可以看到重点在忽略字段生成以及比对逻辑,思路如下:
dubbo接口返回值基本都是一个对象,参考jsonpath思路,通过递归可以获得一个Map(k:路径,v:路径值)。举个例子,返回值的类为public class ItemSavedModel { private Long itemId; private Long shopId; }
1234
假设返回对象itemId为1,shopId为2,那么拆解出Map为{"/itemId":"1","/shopId":"2"},对象的比较转换为Map的比较。 通过两次基础环境返回值的比较,不同的路径值对应的路径,就是下次比较要忽略的路径。
对象拆解成Map核心代码如下:
/** * 获取对象路径 * * @param obj * @return */ public static HashMap<String, Object> getObjectPathMap(Object obj) { HashMap<String, Object> map = new HashMap<>(); getPathMap(obj, "", map); return map; } private static void getPathMap(Object obj, String path, HashMap<String, Object> pathMap) { if (obj == null) { return; } Class<?> clazz = obj.getClass(); //基本类型 if (clazz.isPrimitive()) { pathMap.put(path, obj); return; } //包装类型 if (ReflectUtil.isBasicType(clazz)) { pathMap.put(path, obj); return; } //集合或者map if (ReflectUtil.isCollectionOrMap(clazz)) { //todo:默认key为基础类型 if (Map.class.isAssignableFrom(clazz)) { Map map = (Map) obj; map.forEach((k, v) -> { if (k != null) { getPathMap(v, path + "/" + k.toString(), pathMap); } }); } else { Object[] array = ReflectUtil.convertToArray(obj); for (int i = 0; i < array.length; i++) { getPathMap(array[i], path + "/" + i, pathMap); } } return; } //pojo //获取对象所有的非静态变量字段 List<Field> fields = ReflectUtil.getAllFields(clazz); fields.forEach(field -> getPathMap(ReflectUtil.getField(obj, field), path + "/" + field.getName(), pathMap)); return; }
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354
按照上述代码拆解出项目环境返回值对应的Map(k:路径,v:路径值),根据上一步骤获得的忽略路径和基础环境返回值,即可计算出两次返回值一致与不一致的字段路径。代码不再赘述,感兴趣的读者可以在留言区讨论。写接口校验思路
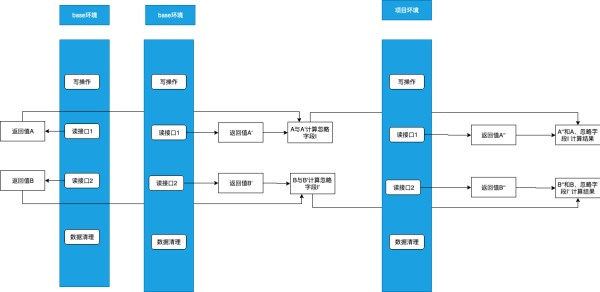
写接口相对读接口会复杂一些,篇幅所限,主要讲解核心逻辑。写接口校验整体逻辑与读接口类似:总共触发三次请求,前两次所有读写接口在基础环境执行,计算出忽略字段以及记录下来基础环境返回值。第三次所有请求都在项目环境,获取接口在项目环境的返回值,接下来排除掉忽略字段,比较基础环境和项目环境接口对应的返回值即可完成校验。
整体流程如下:
//触发三次请求 public class GlobalCoverISuiteListener implements ISuiteListener { public static ConcurrentHashMap<String,Integer> suiteFinishMap=new ConcurrentHashMap<>(); @Override public void onStart(ISuite suite) { if(suiteFinishMap.size()==0 ){ //第一次进来 设置globalCoverFlag为1 后面会new testng两次 System.setProperty("globalCoverFlag", "1"); if(System.getProperty("globalCoverFlag").equals("1")) { suiteFinishMap.put(suite.getXmlSuite().getName(),1); TestNG tng = new TestNG(); tng.setXmlSuites(Arrays.asList(suite.getXmlSuite())); tng.run(); } } } @Override public void onFinish(ISuite suite) { suite.getResults().forEach((suitename, suiteResult)->{ ITestContext context = suiteResult.getTestContext(); if(System.getProperty("globalCoverFlag").equals("1")) { int before = suiteFinishMap.get(suite.getXmlSuite().getName()); //第二次结束 表示计算忽略字段已经结束 可以进行正常的跑case了 if(suiteFinishMap.get(suite.getXmlSuite().getName())==2){ suiteFinishMap.put(suite.getXmlSuite().getName(),++before); System.setProperty("globalCoverFlag", "0"); return; } suiteFinishMap.put(suite.getXmlSuite().getName(),++before); TestNG tng = new TestNG(); tng.setXmlSuites(Arrays.asList(context.getCurrentXmlTest().getSuite())); tng.run(); } }); } }
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647
测试用例中一般都存在着读、写接口两类用例,只有写操作用例需要在三遍suite中均执行,读操作用例只需要在最后一次suite执行即可。综合考虑,前两次的suite希望只执行写操作的case。因此实现testNg监听器方法IMethodInterceptor.intercept,拦截器上只返回此次suite执行的测试用例,从而达到前两次只执行写操作的case。我们采用在写操作用例挂上一个注解,标识为写操作用例,方便拦截器判断用例类型。核心代码如下://case层方法加上注解 @WriteCaseDiffAnnotation @Test public void testAdd(){ //写操作 //读操作 } // IMethodInterceptor.intercept中判断注解,获取写操作用例 @Override public List<IMethodInstance> intercept(List<IMethodInstance> methods, ITestContext context) { List<IMethodInstance> testMethods = new ArrayList<>(); //获取写操作测试用例方法 for (IMethodInstance methodInstance : methods) { if (isQualified(methodInstance.getMethod())) { testMethods.add(methodInstance); } } if (System.getProperty(GlobalOperatorType.GLOBAL_COVER.getStr()). equals(GlobalOperatorType.GLOBAL_COVER.getFlag())) { //前两次suite,只返回写操作测试方法 return testMethods; } else { //最后一次suite,返回所有的测试方法 return methods; } } //判断测试方法是否有WriteCaseDiffAnnotation注解 public boolean isQualified(ITestNGMethod iTestNGMethod) { Method m = iTestNGMethod.getConstructorOrMethod().getMethod(); WriteCaseDiffAnnotation writeAnnotation = m.getAnnotation(WriteCaseDiffAnnotation.class); Test test = m.getAnnotation(Test.class); if (writeAnnotation != null && test != null) { return true; } return false; }
123456789101112131415161718192021222324252627282930313233343536373839
不足
目前仅支持dubbo接口,后期考虑扩展到前端node层接口校验 目前强依赖基础测试环境,为了更好的兼容性,后期考虑引入存储方式来解除基础环境依赖感谢商品测试组乔鹏阳、俞佳宁、阿娇等小伙伴的大力支持,提供了很多技术以及设计思路的支持。 有赞测试组在持续招人中,大量岗位可选,有意向的同学可以发简历到 weishichao@youzan.com
欢迎关注我们的公众号
 无用的设计模式-上篇提到设计模式,有一个非常有意思的现象: 理论学习中,几乎所有的开发人员都认为它非常有用很重要。 工作实践中,绝大部分开发人员在项目中找不到合适的应用场景。 设计模式学了一遍又一遍,却毫无用武之地。大概设计模式最好的归宿,就是存在程序员的深深的脑海里。 难道设计模式真的没有用了吗? 关于本文 本文目的,通过对设计模式的本质进行探讨剖析,建立起更为高效的认知模式。最终可以灵活运用设计模式到日常工作中,产出稳定、高效、灵活的业务实现。…Presto 在有赞的实践之路一、前言 本文主要介绍了 Presto 的简单原理,以及 Presto 在有赞的实践之路。 二、Presto 介绍 Presto 是由 Facebook 开发的开源大数据分布式高性能 SQL 查询引擎。起初,Facebook…
无用的设计模式-上篇提到设计模式,有一个非常有意思的现象: 理论学习中,几乎所有的开发人员都认为它非常有用很重要。 工作实践中,绝大部分开发人员在项目中找不到合适的应用场景。 设计模式学了一遍又一遍,却毫无用武之地。大概设计模式最好的归宿,就是存在程序员的深深的脑海里。 难道设计模式真的没有用了吗? 关于本文 本文目的,通过对设计模式的本质进行探讨剖析,建立起更为高效的认知模式。最终可以灵活运用设计模式到日常工作中,产出稳定、高效、灵活的业务实现。…Presto 在有赞的实践之路一、前言 本文主要介绍了 Presto 的简单原理,以及 Presto 在有赞的实践之路。 二、Presto 介绍 Presto 是由 Facebook 开发的开源大数据分布式高性能 SQL 查询引擎。起初,Facebook…
