读取CSV文件,格式化显示文件内容
附件处理要注明,如'附件:XX文件',确保附件与正文内容对应。 #生活技巧# #职场生存技巧# #公文格式规范#
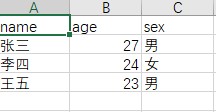
CSV文件内容
输出格式1
输出结果: L: [{'name': '张三', 'age': '27', 'sex': '男'}] 1
附上代码:
with open('CSV.csv','r') as f: keys = f.readline().strip().split(',')#代表了第一行数据(表头) L = [] # d=f.readlines() for x in f.readlines(): dict_ = {} line = x.strip().split(',') for i in range(len(keys)): dict_[keys[i]] = line[i] L.append(dict_) print(L) 1234567891011
代码分析:
1.keys是通过读取csv文件第一行获取表头数据(readline()一次只读取一行数据,strip()作用于字符串,在此处可以去除空格,split()可以按规定的分隔符进行分隔字符串,使其变成列表)
2.d是通过readlines()将剩余的CSV文件一次性全部读入,每一行数据作为列表的元素
3.通过对d的遍历,获取每一行的数据,然后通过line变量(列表类型),获取每一行的每一个数据
4.通过想要达到的效果,我们知道,一行数据是单独占领一个dict_的,每行数据在加入dict_后(循环结束后),应该要将其append到L列表中
注意点:
1.如果你在程序中插入读的相关操作,那么你会影响文件指针的指向,影响下面程序读取文件数据
输出格式2
输出结果: dict_={'name': ['张三', '王五'], 'age': ['27', '23'], 'sex': ['男', '男']} 1
附上代码:
with open('CSV.csv','r') as f: keys = f.readline().strip().split(',') L = [] dict_ = {} for x in f.readlines(): #循环1 line = x.strip().split(',') for i in range(len(keys)):#循环2 L.append (line[i])#截取到各行的数据 for i in range(len(keys)):#循环3 dict_[keys[i]] = L[i::len(keys)] print(dict_) 1234567891011
代码分析:
1.整个程序的思路很清晰,将每行的数据(3个子数据)全部都放在L中,然后使用切片做成我们想要的效果(真的很巧妙!)
2. L在整个程序运行完后的结果:[‘张三’, ‘27’, ‘男’, ‘李四’, ‘24’, ‘女’, ‘王五’, ‘23’, ‘男’]
3.循环1读取除表头外的每行数据
4.循环2中的L每次都将每行的数据append进来
5.循环3就是利用切片将L中的姓名,年龄,性别分别切出来,对应地放在dict_中相应的键中(keys[i])中
# solution 2: 第二种打印形式 def operate_file(filepath): with open(filepath, 'r', encoding='UTF-8') as f: keys = f.readline().strip().split(',') # keys 是其中的表中的字段,用strip来去除每行末尾的换行符 dic, n = {}, 0 # dic用来存放最终数据,n控制读取表字段的累加器 """ 1. 利用双重循环达到1×3(1个name键下有3个名字)的匹配结果 2. 散列表是无序的,不能保证按顺序读入表中字段(好像不影响) 3. 做了很多无用功,每次values循环只能填写字典中的一个键的所有取值,然后重新定位到第二行 4. 刚开始的错误, 遍历keys时,因为它是最外层循环,so 必须等里头的循环执行完毕才能遍历下一个key,导致dic[key] 在values 和n都改变的情况下,key还是不变 5. 因为values 遍历一遍后f就指向文件末尾,需要重新定位到第二行,不然遍历f始终为空 """ for key in keys: dic[key] = [] for values in f: # 每次的values 都是一行数据,也就是说a 是每一行列表数据的第n个元素 a = values.strip().split(',')[n] dic[key].append(a) # 其中的key 正好对应 元素a n += 1 # 因为要读取每一行的不同下标的元素,so此处n需要加1 f.seek(13, 0) # 文件定位到第二行的第一个元素,以提供给最近一层的for循环遍历f # 第一个参数:偏移量,第二个参数:指针位置 return dic
123456789101112131415161718192021222324网址:读取CSV文件,格式化显示文件内容 https://www.yuejiaxmz.com/news/view/415594
相关内容
python3读取文件和异常处理(七)服装文件有多少种格式的(不同类型的服装文件有多少种格式?)
使用python处理csv数据的常规做法
Linux频繁存取文件,导致可用内存逐渐减少
PCRT:自动化检测修复损坏PNG文件取证工具
读文献必备工具软件大合集!
DropIt 懒人的文件分类整理神器
推荐这三款自动化爬虫软件,非常实用!
(GitHub) [Windows] 内存优化工具 WinMemoryCleaner v2.7 单文件版
doc文件用什么打开
随便看看
最新动态分享
- 健康准妈妈的膳食指南(孕期营养).pptx
- 孕产妇营养健康教育核心信息及释义(九) | 健康生活方式
- 【孕妇营养饮食表
- 孕妇饮食与胎儿健康:科学甜食摄入指南及备孕营养建议
- 我随身携带的避难所
- AI智能手机版修图软件下载安装免费(探索人工智能在手机摄影中的应用与便捷性)
- #联想AIPC我的AICP# @联想YOGA 联想AIPC,我的AICP 联想AIPC·我超级期待最近我疯狂的想要入手电脑,因为人工智能应用到电脑之上,让我感受到了如今电脑超强的性能和智能化。➡️比如说联想新品所蕴含
- “桂林智造”亮相全球AI盛会
- 松下电饭煲推荐:5款智能高效的厨房好帮手,轻松烹饪美味!
- 格子达系统与论文降重工具全解析:Z世代的学术好帮手
热点动态分享
- 133271
- 36106
- 35700
- 23632
- 22971
- 21258
- 20652
- 14805
- 14724
- 14652

