GPTVoiceTasker: 智能手机中LLM赋能的虚拟助理
虚拟助手(如Siri、Alexa)是人工智能在日常生活中的常见应用 #生活知识# #科技生活# #人工智能应用#
24年1月主要来自澳大利亚几所大学的论文“GPTVoiceTasker: LLM-Powered Virtual Assistant for Smartphone"。
虚拟助理有可能在帮助用户完成不同任务方面发挥重要作用。然而,这些系统在现实世界中的可用性面临挑战,其特点是效率低下,难以把握用户意图。利用大语言模型(LLM)的最新进展,推出GptVoiceTasker,一款虚拟助手,旨在增强移动设备上的用户体验和任务效率。GptVoiceTasker擅长智能破译用户命令和执行相关设备交互,简化任务完成。该系统不断从历史用户命令中学习,自动化后续使用,进一步提高执行效率。实验证实了GptVoiceTasker卓越的命令解释能力及其任务自动化模块的准确性。
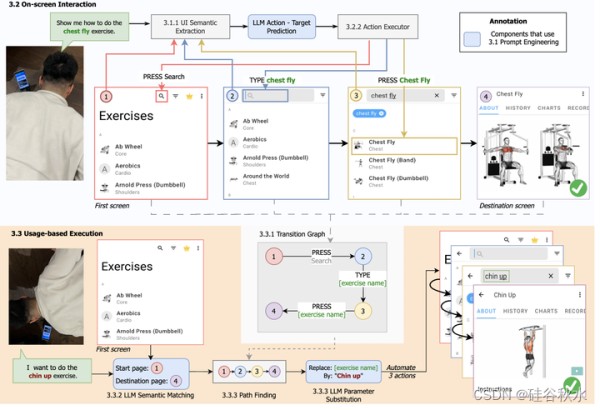
如图所示家庭训练应用程序中的一个示例用例,当用户由于身体繁忙而需要免提与智能手机交互时。在执行屏幕交互时,GptVoiceTasker反复提示LLM使用当前UI信息预测屏幕上的动作,并执行响应以实现用户任务。然后保存执行信息以简化后续类似任务的执行。
近年来,自然语言理解(NLU)的进步推动了语音助手跨各种平台的发展,包括无所不在(ubiquitous)系统[7,32]和家用电器[52]。在个人智能手机上,已经提出了许多语音助手,利用智能NLU模型来理解用户语音输入并将其映射到用户界面动作。智能手机语音控制界面的早期里程碑是JustSpike,它利用谷歌的自动语音识别(ASR)来记录用户命令,并引入了创新的话语(utterance)解析技术[71]。随后,智能语音助手扩展了JustSpike的功能,使用户能够通过语音命令管理呼叫和短信[11]。类似的努力,Weber在2016年的“VoiceNavigator”应用程序,专注于增强移动语音用户界面应用程序的可见性和可学习性[18]。然而,这些最初的方法虽然是基础性的,但由于严格的语言解析启发式和有限的用例而遇到了可用性问题,这激发了进一步开发智能手机虚拟助理的需求。
近年来,通过深度学习模型,语言解析能力取得了重大进步。SAVANT利用Dialogflow作为会话智体从话语中提取用户意图[4],而DoThisHere则采用了预构建的Almond语言模型,实现了在Android中检索和设置UI内容的语音控制[69]。谷歌发布了语音访问[1],旨在用语音命令取代手动交互,该命令在Google Play商店上的下载量超过1亿。最近,Vocify[60]引入了VocifyParser,这是一种高级的深度学习方法,用于将用户命令解析为屏幕交互,而AutoVCI[51]则专注于开发用于自动化移动UI任务的语音界面。然而,这些现有方法的交互模式仍然有些不自然,要求用户发出精确的机器式指令,例如“按下保存按钮”。这种限制意味着他们可能很难完全理解高级用户的意图,例如“我想保存这个笔记”。
生成人工智能的出现催生了创新的LLM,如GPT-4[50]和DALL-E[55]。这些LLM彻底改变了人工智能开发的格局,使开发人员能够通过少量的提示来完成复杂的任务,从而消除了对广泛的自定义模型训练的需求。它们非凡的多功能性促使人们在IT和非IT领域进行积极的研究,涉及软件测试[24,43]、高性能计算[15]、金融[65]和健康科学[25]等领域。LLM在增强现有方法的直观性方面尤其出色,如软件测试中所示,它们基于当前UI页面信息生成真实的文本输入,取代了传统的随机文本输入方法[43]。这证明了LLM在推动多个领域的研究和创新方面的变革潜力。
LLM的功能引发了其在辅助技术中的应用激增,革命性地将用户命令转换为跨不同系统的可执行任务。该领域的最新研究见证了人类自然语言命令转化为各种类型的任务,包括可视化任务[62]、操作系统任务[42]和机器人任务[38,57]。LLM使这些系统能够处理超出现有启发式方法范围的更复杂的命令。它们还表现出非凡的能力,能够理解意图相似但表达方式不同的命令变体。在LLM的支持下,这个开创性的框架为一种(半)自动化任务执行范式铺平了道路,消除了传统命令模式和直观命令模式之间的界限。
在移动助理领域,LLM已经成为一股变革力量,取代了先前相关工作中的传统机器学习模型[51,60]。这种范式的转变简化了将用户的自然语音命令转换为移动用户界面(UI)上可行操作的过程。Wang[61]利用LLM允许与移动UI进行类似对话的交互,这表明与传统的机器学习方法相比,LLM在理解屏幕元素方面具有更好的能力[37]。虽然Wang在智能手机虚拟助理开发中的方法值得注意,但其采用的提示策略仍然是基本的,影响了其解析自然用户命令的能力。
GptVoiceTasker,作为一个虚拟助手,它使用户能够使用语音命令在智能手机上高效地执行各种任务。通过应用不同的提示工程技术,GptVoiceTasker利用LLM的力量来执行不同的逻辑任务。在接收到用户命令后,GptVoiceTasker首先尝试使用保存的数据库自动执行任务。如果使用预存在的数据库证明任务不可行,GptVoiceTasker将执行一系列屏幕导航的逐步预测,以完成任务。同时,系统会记录这些交互,以便后续自动执行。
虽然由于响应的准确性和随机性低,为各种任务提示LLM的天真方法可能会产生次优结果[17],但采用不同的提示工程技术,这些技术包括根据特定的规则和组成部分精心制作提示,从LLM中获得最佳响应[41]。作者创建了多个提示模板,这些模板应用于屏幕上交互和基于使用的执行。
收到用户的任务后,GptVoiceTasker将自动执行多个屏幕上的动作,直到任务完成。首先收集运行时UI元素,从用户命令中执行推理任务,并在用户设备上执行操作。GptVoiceTasker继续重复这个迭代过程,以执行每个操作来完成用户任务。
在移动应用程序中,特定应用程序页面上的UI元素是由开发人员在开发应用程序页面时预定义的。因此,屏幕上实现任务的一系列用户交互将在不同时间保持一致。基于此,GptVoiceTasker自动为每个用户命令创建一个保存的路径,允许GptVoiceTasker在接收到来自用户的类似命令时复制交互。与以前依赖手动任务创建过程来支持自动化的方法[35,51]不同,GptVoiceTasker通过屏幕导航自动记录应用程序转换。这种自动化过程不仅允许更广泛地覆盖自动化任务,而且消除了在预定义快捷任务时手动操作的需要。
作者用Java[21]在Android操作系统中使用辅助功能服务将GptVoiceTasker实现为Android应用程序。在Java代码中,GptVoiceTasker订阅typeWindowContentChanged辅助功能事件[21],以便在屏幕上发生UI更改时接收通知。创建了一个动态流水线,从AccessibilityNodeInfo目标[20]中提取层次结构中的UI元素,这些目标用作Android辅助功能服务提供的屏幕UI元素的数据表示。此外,使用Android PackageManager类获取应用程序名称和活动名称。
为了与LLM通信,使用了OpenAI提供的API服务。作者选择了GPT-4模型,OpenAI训练的最新模型[49]。一旦收到LLM的响应,该工具就会利用performAction()方法[20]对相应的元素执行操作。所有与个性化服务相关的数据,如屏幕描述和转换图,都存储在手机存储器中,以备将来使用。
网址:GPTVoiceTasker: 智能手机中LLM赋能的虚拟助理 https://www.yuejiaxmz.com/news/view/508045
相关内容
虚拟助手:AI赋能个人生活的转折点什么是智能虚拟助理(IVA)?智能虚拟助理的优势和用例
中国的人工智能虚拟机器人,中国的人工智能虚拟机器人是谁
摩科智能AI虚拟人交互一体机:以AI赋能金融,打造智慧理财助手!
AI与虚拟助手:智能个人助手的日常应用.docx
《虚拟机器人编程:让智能助手成为你生活中的好帮手》
探索MyVBot:一个智能虚拟助手的开源项目
混合现实中人工智能虚拟助手的发展
虚拟家庭助理的全新智能化
手机虚拟助手
随便看看
最新动态分享
- 节省燃气有妙招,记住10大技巧
- 小蚌埠社区开展“低碳生活从厨房开始 省电省水又健康的烹饪秘籍”活动
- 【燃气安全】燃气器具的节能方法,你做对了吗?
- 开放式厨房灶具选择难题破解:耐亨动态匀热烹饪体系如何重新定义健康烹饪?
- 火星人ET51:科技与生活的完美结合,让烹饪变得轻松愉悦!
- 厨房烹饪节能妙招
- 书房挂画,看别人家咋做3.28
- 书房挂画图片大全
- 书房怎么挂画 手绘字画美丽雅致更多变
- 几款大师手绘书房装饰画 让家更显优雅大气
热点动态分享
- 136547
- 38994
- 36282
- 23785
- 23454
- 22913
- 21397
- 15194
- 14964
- 14928

