基于pytest设计自动化测试框架实战
使用单元测试确保质量:->测试框架和编写测试 #生活技巧# #学习技巧# #编程学习指南#
简介基于pytest实现测试用例收集方案、自定义参数化方案、页面元素定位数据存储方案、测试用例数据存储和维护方案,这样可直接进入到设计编写测试用例业务代码阶段,避免重复设计这些方案以及方案不统一导致维护复杂、困难的烦恼。实现了可设置用例执行顺序,且不会与pytest-depends插件的依赖排序冲突,这样配合pytest-depends就可以很好的实现测试用例间的依赖设置。修改定制并汉化了html测试报告,使报告显示我们关心的数据,并更加简洁、美观、易读。采用test object设计模式,以及引入链式编程,语义清晰。对selenium、appium、minium(微信小程序自动化测试库)以及WinAppDriver(微软官方提供的一款用于做Window桌面应用程序的界面(UI)自动化测试工具)做了封装集成,更好的支持桌面端web界面、移动端app界面、微信小程序界面以及Window桌面应用程序的界面(UI)的自动化测试。
用例收集方案
相比于pytest默认的命名匹配收集测试用例方案,我更倾向testng使用@Test注解标记测试用例的方案,于是,参考了testng,形成了自己的一套测试收集方案:
测试用例业务代码需要放在包sevenautotest的子包testcases下,执行测试时自动去该包下查找出所有测试用例来执行测试用例类需要继承抽象用例类(BaseTestCase)使用@pytest.mark.testcase标记测试用例方法,使用位置参数设置用例名,关键字参数author设置用例编 写者和editor设置最后修改者测试方法需要接收一个参数,参数化时从测试数据文件取出的该方法测试数据作为字典传给该测试方法这种方案没有用例名称上的限制,如何实现我们的自定义收集方案,这就涉及到pytest以下几个钩子函数:
pytest_configure(config)pytest_pycollect_makeitem(collector, name, obj)pytest_collection_modifyitems(session, config, items)实现代码如下:
def pytest_configure(config):
config.addinivalue_line("markers", "%s(name): Only used to set test case name to test method" % settings.TESTCASE_MARKER_NAME)
config.addinivalue_line("testpaths", settings.TESTCASES_DIR)
config.addinivalue_line("python_files", "*.py")
config.addinivalue_line("filterwarnings", "ignore::UserWarning")
opts = ["JAVA_HOME", "Packages", "Platform", "Plugins", "Python"]
for opt in opts:
config._metadata.pop(opt, None)
def pytest_pycollect_makeitem(collector, name, obj):
"""
@see PyCollector._genfunctions
@see _pytest.python
"""
if safe_isclass(obj):
if collector.istestclass(obj, name) or (issubclass(obj, AbstractTestCase) and obj != AbstractTestCase):
if hasattr(pytest.Class, "from_parent"):
return pytest.Class.from_parent(collector, name=name)
else:
return pytest.Class(name, parent=collector)
else:
obj = getattr(obj, "__func__", obj)
if (inspect.isfunction(obj) or inspect.isfunction(get_real_func(obj))) and getattr(obj, "__test__", True) and isinstance(collector, pytest.Instance) and hasattr(obj, "pytestmark"):
if not is_generator(obj):
return list(collector._genfunctions(name, obj))
else:
return []
else:
return []
def enable_of_testcase_marker(testcase_markers):
key = "enable"
enable = False
for m in testcase_markers:
enable = m.kwargs.get(key, None)
if enable is not None:
break
if enable is None:
enable = True
return enable
def get_group_name_from_nodeid(nodeid):
sep = "::"
parts = nodeid.split(sep)
group_name = sep.join(parts[0:len(parts) - 1])
return group_name
def priority_of_testcase_marker(testcase):
key = "priority"
markers = list(testcase.iter_markers(settings.TESTCASE_MARKER_NAME))
priority = None
for m in markers:
priority = m.kwargs.get(key, None)
if priority is not None:
break
return priority
def sorted_by_priority(testcases):
"""根据priority(优先级)对用例进行排序,如果没有设置priority,则不会对该用例进行排序,它的执行顺序不变"""
groupnames = []
for testcase in testcases:
gname = get_group_name_from_nodeid(testcase.nodeid)
if gname not in groupnames:
groupnames.append(gname)
groups = {}
for gn in groupnames:
group = []
for i, tc in enumerate(testcases):
if gn == get_group_name_from_nodeid(tc.nodeid) and priority_of_testcase_marker(tc) is not None:
group.append((i, tc))
group.sort(key=lambda x: x[0])
new_group = sorted(group, key=lambda x: priority_of_testcase_marker(x[1]))
itemlist = []
for index, item in enumerate(new_group):
new_index = group[index][0]
old_index = item[0]
current_testcase = item[1]
itemlist.append((new_index, old_index, current_testcase))
groups[gn] = itemlist
for items in groups.values():
for item in items:
new_index = item[0]
thiscase = item[2]
testcases[new_index] = thiscase
@pytest.hookimpl(tryfirst=True)
def pytest_collection_modifyitems(session, config, items):
new_items = []
for item in items:
markers = list(item.iter_markers(settings.TESTCASE_MARKER_NAME))
if len(markers) and enable_of_testcase_marker(markers):
new_items.append(item)
sorted_by_priority(new_items)
items[:] = new_items
用例数据存储格式测试用例数据存放excel文件中,文件名需以测试类名作为名称,文件只存放该类下的测试用例方法数据,统一放在主目录下的testdata目录下。数据在文件中以用例数据块的方式存储,数据块定义如下:
所有行中的第一列是标记列,第一行第一列是数据块开始标记第一行: 用例名称信息(标记列的下一列是用例方法名称列,之后是用例名称列)第二行: 用例数据标题第三行 开始 每一行都是一组完整的测试数据直至遇见空行或者下一个数据块
接下来,我们需要对excel文件进行解析,读取出所有的测试数据出来,实现代码如下:
"""
数据文件读取器
"""
import sys
import xlrd
from sevenautotest.utils import helper
from sevenautotest.utils.marker import ConstAttributeMarker
from sevenautotest.utils.AttributeManager import AttributeManager
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
__version__ = "1.0"
__author__ = "si wen wei"
class TestCaseBlock(AttributeManager):
"""
测试用例块
块中每行数据定义如下:
所有行中的第一列是标记列
第一行: 用例名称信息(标记列的下一列是用例名称列,之后是用例别名列)
第二行: 用例数据标题
第三行 开始 每一行都是一组完整的测试数据直至遇见空行或者下一个数据块
"""
UTF_8 = ConstAttributeMarker("UTF-8", "UTF-8字符编码")
EMPTY_STRING = ConstAttributeMarker("", "空字符串")
XL_CELL_EMPTY = ConstAttributeMarker(0, "Python value:empty string ''")
XL_CELL_TEXT = ConstAttributeMarker(1, "Python value:a Unicode string")
XL_CELL_NUMBER = ConstAttributeMarker(2, "Python value:float")
XL_CELL_DATE = ConstAttributeMarker(3, "Python value:float")
XL_CELL_BOOLEAN = ConstAttributeMarker(4, "Python value:int; 1 means TRUE, 0 means FALSE")
XL_CELL_ERROR = ConstAttributeMarker(5, "Python value:int representing internal Excel codes; for a text representation, refer to the supplied dictionary error_text_from_code")
XL_CELL_BLANK = ConstAttributeMarker(6, "Python value:empty string ''. Note: this type will appear only when open_workbook(..., formatting_info=True) is used.")
NAME_ROW_INDEX = ConstAttributeMarker(0, "例块中名称行索引")
TITLE_ROW_INDEX = ConstAttributeMarker(1, "用例块中数据标题索引")
MIN_NUMBER_OF_ROWS = ConstAttributeMarker(3, "用例区域至少需要的行数")
def __init__(self, flag_column_index=0):
"""
@param flag_column_index 用例区块内分隔符列索引
"""
self._rows = []
self._flag_column_index = flag_column_index
@property
def rows(self):
return self._rows
def is_valid(self):
"""校验用例数据块是否符合要求(行数最少包含3行 用例名称 行 , 用例数据标题 行 , 用例数据标题 行[可以有多行])"""
return False if len(self.rows) < self.MIN_NUMBER_OF_ROWS else True
def is_integer(self, number):
return number % 1 == 0.0 or number % 1 == 0
def add_block_rows(self, *block_rows):
for block_row in block_rows:
self._rows.append(block_row)
def get_name_row(self):
return self.rows[self.NAME_ROW_INDEX][1]
def _get_name_row_values(self):
values = []
for cell in self.get_name_row():
ctype = cell.ctype
value = cell.value
if ctype == self.XL_CELL_TEXT and value.strip() != self.EMPTY_STRING:
values.append(value)
elif ctype == self.XL_CELL_NUMBER:
if self.is_integer(value):
values.append(str(int(value)))
else:
values.append(str(value))
else:
pass
return values
@property
def name_column_index(self):
return self._flag_column_index + 1
@property
def alias_column_index(self):
return self.name_column_index + 1
@property
def testcase_name(self):
cell_values = self._get_name_row_values()
return cell_values[self.name_column_index]
@property
def testcase_alias(self):
cell_values = self._get_name_row_values()
return cell_values[self.alias_column_index]
def is_empty_string(self, value):
return value.strip() == self.EMPTY_STRING
def _do_nothing(self, *objs):
return objs
def get_data_titles(self):
titles = []
for index, cell in enumerate((self.rows[self.TITLE_ROW_INDEX][1])):
if index == self._flag_column_index:
continue
if cell.ctype == self.XL_CELL_TEXT and not self.is_empty_string(cell.value):
titles.append((index, cell.value))
else:
val = cell.value.decode(self.UTF_8) if isinstance(cell.value, bytes) else cell.value
self._do_nothing(val)
break
return titles
def get_testdata(self):
all_row_data = []
for row_index, item in enumerate(self.rows):
index_in_excel_file, row = item
if row_index + 1 >= self.MIN_NUMBER_OF_ROWS:
one_row_data = []
for title_cell_index, title in self.get_data_titles():
value_cell = row[title_cell_index]
if value_cell.ctype == self.XL_CELL_TEXT:
value = value_cell.value
elif value_cell.ctype == self.XL_CELL_EMPTY or value_cell.ctype == self.XL_CELL_BLANK:
value = value_cell.value
else:
raise Warning("用例(%s)数据单元格(%s行%s列)类型必须是文本类型" % (self.testcase_name, index_in_excel_file + 1, title_cell_index + 1))
one_row_data.append({title: value})
all_row_data.append(one_row_data)
return all_row_data
class TestCaseData(object):
def __init__(self, name, alias=""):
self.name = name
self.alias = alias
self.datas = []
class TestCaseExcelFileReader(AttributeManager):
UTF_8 = ConstAttributeMarker("UTF-8", "UTF-8字符编码")
EMPTY_STRING = ConstAttributeMarker("", "空字符串")
XL_CELL_EMPTY = ConstAttributeMarker(0, "Python value:empty string ''")
XL_CELL_TEXT = ConstAttributeMarker(1, "Python value:a Unicode string")
XL_CELL_NUMBER = ConstAttributeMarker(2, "Python value:float")
XL_CELL_DATE = ConstAttributeMarker(3, "Python value:float")
XL_CELL_BOOLEAN = ConstAttributeMarker(4, "Python value:int; 1 means TRUE, 0 means FALSE")
XL_CELL_ERROR = ConstAttributeMarker(5, "Python value:int representing internal Excel codes; for a text representation, refer to the supplied dictionary error_text_from_code")
XL_CELL_BLANK = ConstAttributeMarker(6, "Python value:empty string ''. Note: this type will appear only when open_workbook(..., formatting_info=True) is used.")
DEFAULT_SHEET_INDEX = ConstAttributeMarker(0, "默认取excel的工作表索引")
DEFAULT_TESTCASE_BLOCK_SEPARATORS = ConstAttributeMarker("用例名称", "默认用例分割标记")
def __init__(self, filepath, testcase_block_separators="用例名称", testcase_block_separators_column_index=0, sheet_index_or_name=0):
"""
@param filename – 要打开的电子表格文件的路径。
@param testcase_block_separators - 用例分割标记
@param data_start_column_index - 用例分割标记列索引
"""
self.filepath = filepath
self.testcase_block_separators = testcase_block_separators if (isinstance(testcase_block_separators, str) and testcase_block_separators) else self.DEFAULT_TESTCASE_BLOCK_SEPARATORS
self.testcase_block_separators_column_index = testcase_block_separators_column_index if helper.is_positive_integer(testcase_block_separators_column_index) else 0
self.sheet_index_or_name = sheet_index_or_name if helper.is_positive_integer(sheet_index_or_name) else self.DEFAULT_SHEET_INDEX
self.open()
self.select_sheet(self.sheet_index_or_name)
def open(self):
self.workbook = xlrd.open_workbook(self.filepath)
@property
def sheet(self):
attr_name = "_sheet"
if not hasattr(self, attr_name):
raise AttributeError('{} has no attributes: {}'.format(self, attr_name))
return self._sheet
def debug(self):
testcases = self.load_testcase_data()
print(len(testcases))
tc = testcases[0]
for row in tc.datas:
line = []
for cell in row:
for key in cell:
line.append(key + " " + str(cell[key]))
print(" | ".join(line))
r1 = tc.datas[0]
print(r1[0].get("路径"))
def row_len(self, row_index):
return self._sheet.row_len(row_index)
def select_sheet(self, sheet_index_or_name):
if isinstance(sheet_index_or_name, str):
self.sheet_index_or_name = sheet_index_or_name
self._sheet = self.workbook.sheet_by_name(sheet_index_or_name)
elif isinstance(sheet_index_or_name, int):
self.sheet_index_or_name = sheet_index_or_name
self._sheet = self.workbook.sheet_by_index(sheet_index_or_name)
else:
raise Warning("传入的工作表名称必须是字符串类型,索引必须是整形数值")
return self.sheet
def is_blank_cell(self, cell):
return cell.ctype == self.XL_CELL_EMPTY or cell.ctype == self.XL_CELL_BLANK
def is_blank_row(self, row_or_index):
is_blank = True
if isinstance(row_or_index, int):
cells = self._sheet.row(row_or_index)
else:
cells = row_or_index
for cell in cells:
if not self.is_blank_cell(cell):
is_blank = False
break
return is_blank
def get_row_indexes(self):
return range(self._sheet.nrows)
def get_last_row_index(self):
return max(self.get_row_indexes())
def get_testcase_blocks(self):
"""解析并获取用例文件中的用例块区域"""
zero = 0
block_start_row_index_list = []
testcase_block_list = []
for row_index in self.get_row_indexes():
if (self.row_len(row_index) == zero):
continue
first_cell = self._sheet.cell(row_index, self.testcase_block_separators_column_index)
if first_cell.ctype == self.XL_CELL_TEXT and first_cell.value == self.testcase_block_separators:
block_start_row_index_list.append(row_index)
count = len(block_start_row_index_list)
for i in range(count):
testcase_block = TestCaseBlock(self.testcase_block_separators_column_index)
start_row_index = block_start_row_index_list[i]
next = i + 1
if next >= count:
end_row_index = self.get_last_row_index()
else:
block_other_row_indexs = []
for r_index in self.get_row_indexes():
if r_index >= start_row_index and r_index < block_start_row_index_list[next]:
block_other_row_indexs.append(r_index)
end_row_index = max(block_other_row_indexs)
for this_row_index in self.get_row_indexes():
if this_row_index >= start_row_index and this_row_index <= end_row_index:
one_row = self._sheet.row(this_row_index)
if not self.is_blank_row(one_row):
testcase_block.add_block_rows((this_row_index, one_row))
testcase_block_list.append(testcase_block)
return testcase_block_list
def load_testcase_data(self):
testcases = []
for testcase_block in self.get_testcase_blocks():
testcase = TestCaseData(testcase_block.testcase_name, testcase_block.testcase_alias)
testcase.datas = testcase_block.get_testdata()
if testcase.name.strip() != self.EMPTY_STRING:
testcases.append(testcase)
return testcases
if __name__ == "__main__":
pass
用例参数化方案pytest自定义参数化方案需要用到pytest_generate_tests(metafunc)钩子函数,根据测试类名称到testdata目录下查找测试数据excel文件,再根据测试方法名称取出属于该测试方法的测试数据作为字典传给测试方法,实现代码如下:
def pytest_generate_tests(metafunc):
for marker in metafunc.definition.iter_markers():
if marker.name == settings.TESTCASE_MARKER_NAME:
metafunc.function.__doc__ = "".join(marker.args)
break
test_class_name = metafunc.cls.__name__
test_method_name = metafunc.function.__name__
testdata_file_path = os.path.join(settings.TEST_DATA_EXCEL_DIR, test_class_name + ".xlsx")
this_case_datas = []
testcases = TestCaseExcelFileReader(testdata_file_path).load_testcase_data()
for testcase in testcases:
if testcase.name == test_method_name:
for row in testcase.datas:
line = {}
for cell in row:
for title, value in cell.items():
if title in line.keys():
continue
else:
line[title] = value
this_case_datas.append(line)
break
argnames = metafunc.definition._fixtureinfo.argnames
if len(argnames) < 1:
argname = ""
this_case_datas = []
elif len(argnames) < 2:
argname = argnames[0]
else:
emf = "{funcname}() can only be at most one parameter, but multiple parameters are actually defined{args}"
raise TypeError(emf.format(funcname = test_method_name, args = ", ".join(argnames)))
metafunc.parametrize(argname, this_case_datas)
' 配置信息(settings.py)"""
配置文件
"""
__version__ = "1.0"
__author__ = "si wen wei"
import os
APP_USER_ACCOUNT = "cs"
APP_USER_PASSWORD = "hy"
APPIUM_SERVER = "http://127.0.0.1:4723/wd/hub"
APP_DESIRED_CAPS = {
'platformName': 'Android',
'platformVersion': '10.0',
'deviceName': 'P10 Plus',
'appPackage': 'com.zgdygf.zygfpfapp',
'appActivity': 'io.dcloud.PandoraEntry',
}
MINI_CONFIG_JSON_FILE = None
MINI_CONFIG = {
"platform": "ide",
"debug_mode": "info",
"close_ide": False,
"no_assert_capture": False,
"auto_relaunch": False,
"device_desire": {},
"report_usage": True,
"remote_connect_timeout": 180,
"use_push": True
}
URLS = {
'雨燕管理后台': 'http://10.201.15.46:90',
'首页': '/pages/index/index',
'影院列表': '/pages/cinema/cinema',
'我的广告素材': '/pages/ad-material/ad-material',
}
USERS = {
"雨燕管理后台": ("admin", "admin"),
}
API_INFO = [("10.201.15.229", 10021), ("http://music.163.com", )]
POS_TYPE = {
"火烈鸟": "huolieniao",
"火凤凰": "huofenghuang",
}
LAN_MAPS = {"普通话": "普", "俄语": "俄", "英语": "英"}
AD_NAME_PREFIX = 'S'
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
PROJECT_DIR = os.path.dirname(BASE_DIR)
DRIVERS_DIR = os.path.join(PROJECT_DIR, "drivers")
CHROME_DRIVER_PATH = os.path.join(DRIVERS_DIR, "chrome", "chromedriver.exe")
REPORT_DIR = os.path.join(PROJECT_DIR, "report")
LOG_DIR_PATH = os.path.join(PROJECT_DIR, "logs")
INI_FILE_DIR_PATH = os.path.join(PROJECT_DIR, 'iniconfig')
INI_FILE_NAME = "sevenautotest.ini"
TEST_DATA_EXCEL_DIR = os.path.join(PROJECT_DIR, "testdata")
TESTCASES_DIR = os.path.join(BASE_DIR, "testcases")
SCREENSHOTS_DIR = os.path.join(PROJECT_DIR, "screenshots")
API_DATA_ROOT_DIR = os.path.join(PROJECT_DIR, "apidata")
PAGE_ELEMENTS_LOCATORS_ROOT_DIR = os.path.join(PROJECT_DIR, "locators")
HTML_REPORT_NAME = "yuyan_autotest_report.html"
HTML_REPORT_FILE_PATH = os.path.join(REPORT_DIR, HTML_REPORT_NAME)
PY_INIT_FILE_NAME = "__init__.py"
TESTCASE_MARKER_NAME = "testcase"
ATTACH_SCREENSHOT_TO_HTML_REPORT = True
TEST_FILE1 = os.path.join(TESTCASES_DIR, 'BackstageAdlistTest.py::BackstageAdlistTest::test_search_with_parttext_ad_name')
TEST_FILE2 = os.path.join(TESTCASES_DIR, 'YuyanTest.py::YuyanTest::test_order_to_be_paid_is_displayed_correctly')
TEST_FILE3 = os.path.join(TESTCASES_DIR, 'BackstageUserlistTest.py::BackstageUserlistTest::test_search_with_shanghu_after_change_geren_to_shanghu')
TESTCASES = [TEST_FILE3]
PYTEST_COMMANDS = ["-s", '--html=%s' % HTML_REPORT_FILE_PATH, '--self-contained-html'] + TESTCASES
' 页面封装web页面和app页面封装应继承自根基础页面类BasePage,放到包sevenautotest下的子包testobjects下,可以在这个包下再做细分,比如在这个包下再建pages和apis两个子包,分别用于放置封装的页面对象和接口对象。封装的页面需要有两个内部类Elements(元素类)和Actions(动作类),分别用于封装页面的元素和页面动作。AbstractBasePage(抽象根页面)是BasePage(根页面)的父类,它会自动实例化Elements(元素类)和Actions(动作类),分别赋给页面属性elements和actions。AbstractBasePage对selenium进行了二次封装,提供了相应的打开关闭浏览器和查找元素的方法。页面属性DRIVER_MANAGER指向驱动管理器。
元素定位数据元素定位数据也使用excel来存储,格式定义如下:
A、 元素方法定位器区域的第一行,第一列是区域分隔符(使用 页面元素定位器 进行分隔),第二列是元素方法名 称,第三列是元素名称
B、 元素方法定位器区域的第二行是数据标题
C、 元素方法定位器区域的第三行是数据

需要继承自根页面元素类(BasePage.Elements),如果使用装饰器(PageElementLocators)装饰元素方法,则方法需要接受一个参数,装饰器(PageElementLocators)从元素定 位数据excel文件里读出数据会作为字典传给参数。装饰器(PageElementLocators)有两个参数file_name、file_dir_path。file_name元素定位器文件名,未指定则以页面类名作为文件名。file_dir_path元素定位器文件所在的目录路径,未指定则以settings.py配置文件的PAGE_ELEMENTS_LOCATORS_ROOT_DIR作为默认查找目录
页面动作类(Actions)需要继承自根页面元素类(BasePage.Actions),当前动作方法不需要返回数据处理时,可以考虑返回动作实例本身(self),在编写用例业务的时候就可以使用链式编程
web页面封装示例 1
"""
登录页面示例
"""
from sevenautotest.basepage import BasePage
from sevenautotest.basepage import PageElementLocators as page_element_locators
class LoginEmailPage(BasePage):
class Elements(BasePage.Elements):
@property
@page_element_locators()
def login_frame(self, locators):
xpath = locators.get("login_frame")
return self.page.find_element_by_xpath(xpath)
@property
@page_element_locators()
def username(self, locators):
"""用户名输入框"""
xpath = locators.get("用户名")
return self.page.find_element_by_xpath(xpath)
@property
@page_element_locators()
def password(self, locators):
"""密码输入框"""
xpath = locators.get("密码")
return self.page.find_element_by_xpath(xpath)
@property
@page_element_locators()
def auto_login(self, locators):
"""下次自动登录复选框"""
xpath = locators.get("下次自动登录")
return self.page.find_element_by_xpath(xpath)
@property
@page_element_locators()
def login(self, locators):
"""登录按钮"""
xpath = locators.get("登录")
return self.page.find_element_by_xpath(xpath)
class Actions(BasePage.Actions):
def select_login_frame(self):
"""进入frame"""
self.page.select_frame(self.page.elements.login_frame)
return self
def move_to_login_btn(self):
self.page.action_chains.move_to_element(self.page.elements.login).perform()
return self
def username(self, name):
"""输入用户名"""
self.page.elements.username.clear()
self.page.elements.username.send_keys(name)
return self
def password(self, pwd):
"""输入密码"""
self.page.elements.password.clear()
self.page.elements.password.send_keys(pwd)
return self
def login(self):
"""点击登录按钮"""
self.page.elements.login.click()
return self
web页面封装示例 2
from sevenautotest.basepage import BasePage
__author__ = "si wen wei"
class AuditTaskListPage(BasePage):
"""雨燕管理后台审核任务列表页面"""
class Elements(BasePage.Elements):
def tab(self, name):
"""标签"""
xpath = '//div[@id="app"]//div[contains(@class,"ant-layout-content")]/div/div[contains(@class,"main")]//div[contains(@class,"ant-card-body")]//div[contains(@class,"ant-tabs-nav-scroll")]//div[@role="tab" and contains(text(),"{name}")]'.format(
name=name)
return self.page.find_element_by_xpath(xpath)
@property
def all_audit_tasks(self):
"""全部审核任务标签"""
name = '全部审核任务'
return self.tab(name)
@property
def to_be_audit(self):
"""待审核标签"""
name = '待审核'
return self.tab(name)
@property
def audit_pass(self):
"""审核通过标签"""
name = '审核通过'
return self.tab(name)
@property
def audit_fail(self):
"""审核未通过标签"""
name = '审核未通过'
return self.tab(name)
@property
def film_limit(self):
"""影片限制标签"""
name = '影片限制'
return self.tab(name)
@property
def unaudit_expire(self):
"""过期未审核标签"""
name = '过期未审核'
return self.tab(name)
def _search_form_input(self, label):
xpath = '//div[@id="app"]//div[contains(@class,"ant-layout-content")]/div/div[contains(@class,"main")]//div[contains(@class,"ant-card-body")]//div[contains(@class,"table-page-search-wrapper")]/form//div[contains(@class,"ant-form-item-label")]/label[normalize-space()="{label}"]/parent::*/following-sibling::div//input'.format(
label=label)
return self.page.find_element_by_xpath(xpath)
@property
def audit_tasknumber(self):
"""审核任务编号输入框"""
label = '审核任务编号'
return self._search_form_input(label)
@property
def ad_number(self):
"""广告编号输入框"""
label = '广告编号'
return self._search_form_input(label)
@property
def time_to_first_run(self):
"""距首次执行时间 选择框"""
label = '距首次执行时间'
xpath = '//div[@id="app"]//div[contains(@class,"ant-layout-content")]/div/div[contains(@class,"main")]//div[contains(@class,"ant-card-body")]//div[contains(@class,"table-page-search-wrapper")]/form//div[contains(@class,"ant-form-item-label")]/label[normalize-space()="{label}"]/parent::*/following-sibling::div//div[@role="combobox"]'.format(
label=label)
return self.page.find_element_by_xpath(xpath)
def dropdown_selectlist(self, opt):
"""下拉列表选择框"""
xpath = '//div[@id="app"]/following-sibling::div//div[contains(@class,"ant-select-dropdown")]/div[@id]/ul/li[@role="option" and normalize-space()="{opt}"]'.format(opt=opt)
return self.page.find_element_by_xpath(xpath)
def _search_form_button(self, name):
xpath = '//div[@id="app"]//div[contains(@class,"ant-layout-content")]/div/div[contains(@class,"main")]//div[contains(@class,"ant-card-body")]//div[contains(@class,"table-page-search-wrapper")]/form//span[contains(@class,"table-page-search-submitButtons")]//button/span[normalize-space()="{name}"]/parent::*'.format(
name=name)
return self.page.find_element_by_xpath(xpath)
@property
def search_btn(self):
"""查询按钮"""
return self._search_form_button('查 询')
@property
def reset_btn(self):
"""重置按钮"""
return self._search_form_button('重 置')
def table_row_checkbox(self, rowinfo, match_more=False):
""" 根据条件 查找指定行,返回行的复选框元素
Args:
rowinfo: 表格中行的列信息,键定义如下
taskno: 审核任务编号
adno: 广告编号
orderno: 订单数量
filmno: 影片数量
status: 审核状态
match_more: 是否返回匹配的多个的复选框 False --- 只返回匹配的第一个
"""
checkbox_index = 1
taskno_index = 2
adno_index = 3
orderno_index = 4
filmno_index = 5
status_index = 9
xpath_header = '//div[@id="app"]//div[contains(@class,"ant-layout-content")]/div/div[contains(@class,"main")]//div[contains(@class,"ant-card-body")]//div[contains(@class,"ant-table-body")]/table/tbody/tr/'
checkbox_col = 'td[{index}]/span'.format(index=checkbox_index)
taskno_col = 'td[position()={index} and normalize-space()="{taskno}"]'
adno_col = 'td[position()={index}]/div/a[normalize-space()="{adno}"]/parent::div/parent::td'
orderno_col = 'td[position()={index} and normalize-space()="{orderno}"]'
filmno_col = 'td[position()={index} and normalize-space()="{filmno}"]'
status_col = 'td[position()={index}]/div/span[normalize-space()="{status}"]/parent::div/parent::td'
taskno_k = 'taskno'
adno_k = 'adno'
orderno_k = 'orderno'
filmno_k = 'filmno'
status_k = 'status'
valid_keys = [taskno_k, adno_k, orderno_k, filmno_k, status_k]
has_vaild_key = False
for k in valid_keys:
if k in rowinfo.keys():
has_vaild_key = True
break
if not has_vaild_key:
raise KeyError('没有以下任意键:' + ", ".join(valid_keys))
cols = []
if taskno_k in rowinfo:
cxpath = taskno_col.format(index=taskno_index, taskno=rowinfo[taskno_k])
cols.append(cxpath)
if adno_k in rowinfo:
cxpath = adno_col.format(index=adno_index, adno=rowinfo[adno_k])
cols.append(cxpath)
if orderno_k in rowinfo:
cxpath = orderno_col.format(index=orderno_index, orderno=rowinfo[orderno_k])
cols.append(cxpath)
if filmno_k in rowinfo:
cxpath = filmno_col.format(index=filmno_index, filmno=rowinfo[filmno_k])
cols.append(cxpath)
if status_k in rowinfo:
cxpath = status_col.format(index=status_index, status=rowinfo[status_k])
cols.append(cxpath)
cols.append(checkbox_col)
xpath_body = "/parent::tr/".join(cols)
full_xpath = xpath_header + xpath_body
if match_more:
return self.page.find_elements_by_xpath(full_xpath)
else:
return self.page.find_element_by_xpath(full_xpath)
def _table_row_button(self, name, rowinfo):
""" 根据条件 查找指定行内的按钮,并返回
Args:
name: 按钮名称
rowinfo: 表格中行的列信息,键定义如下
taskno: 审核任务编号
adno: 广告编号
orderno: 订单数量
filmno: 影片数量
status: 审核状态
"""
taskno_index = 2
adno_index = 3
orderno_index = 4
filmno_index = 5
status_index = 9
xpath_header = '//div[@id="app"]//div[contains(@class,"ant-layout-content")]/div/div[contains(@class,"main")]//div[contains(@class,"ant-card-body")]//div[contains(@class,"ant-table-body")]/table/tbody/tr/'
btn_col = 'td/div/button/span[normalize-space()="{name}"]'.format(name=name)
taskno_col = 'td[position()={index} and normalize-space()="{taskno}"]'
adno_col = 'td[position()={index}]/div/a[normalize-space()="{adno}"]/parent::div/parent::td'
orderno_col = 'td[position()={index} and normalize-space()="{orderno}"]'
filmno_col = 'td[position()={index} and normalize-space()="{filmno}"]'
status_col = 'td[position()={index}]/div/span[normalize-space()="{status}"]/parent::div/parent::td'
taskno_k = 'taskno'
adno_k = 'adno'
orderno_k = 'orderno'
filmno_k = 'filmno'
status_k = 'status'
valid_keys = [taskno_k, adno_k, orderno_k, filmno_k, status_k]
has_vaild_key = False
for k in valid_keys:
if k in rowinfo.keys():
has_vaild_key = True
break
if not has_vaild_key:
raise KeyError('没有以下任意键:' + ", ".join(valid_keys))
cols = []
if taskno_k in rowinfo:
cxpath = taskno_col.format(index=taskno_index, taskno=rowinfo[taskno_k])
cols.append(cxpath)
if adno_k in rowinfo:
cxpath = adno_col.format(index=adno_index, adno=rowinfo[adno_k])
cols.append(cxpath)
if orderno_k in rowinfo:
cxpath = orderno_col.format(index=orderno_index, orderno=rowinfo[orderno_k])
cols.append(cxpath)
if filmno_k in rowinfo:
cxpath = filmno_col.format(index=filmno_index, filmno=rowinfo[filmno_k])
cols.append(cxpath)
if status_k in rowinfo:
cxpath = status_col.format(index=status_index, status=rowinfo[status_k])
cols.append(cxpath)
cols.append(btn_col)
xpath_body = "/parent::tr/".join(cols)
full_xpath = xpath_header + xpath_body
return self.page.find_element_by_xpath(full_xpath)
def audit_btn(self, rowinfo):
"""审核按钮"""
name = "审 核"
return self._table_row_button(name, rowinfo)
def audit_record_btn(self, rowinfo):
"""审核记录按钮"""
name = "审核记录"
return self._table_row_button(name, rowinfo)
class Actions(BasePage.Actions):
def all_audit_tasks(self):
"""点击 全部审核任务标签"""
self.page.elements.all_audit_tasks.click()
return self
def to_be_audit(self):
"""点击 待审核标签"""
self.page.elements.to_be_audit.click()
return self
def audit_pass(self):
"""点击 审核通过标签"""
self.page.elements.audit_pass.click()
return self
def audit_fail(self):
"""点击 审核未通过标签"""
self.page.elements.audit_fail.click()
return self
def film_limit(self):
"""点击 影片限制标签"""
self.page.elements.film_limit.click()
return self
def unaudit_expire(self):
"""点击 过期未审核标签"""
self.page.elements.unaudit_expire.click()
return self
def audit_tasknumber(self, taskno):
"""输入任务编号"""
self.page.elements.audit_tasknumber.clear()
self.page.elements.audit_tasknumber.send_keys(taskno)
return self
def ad_number(self, adno):
"""输入广告编号"""
self.page.elements.ad_number.clear()
self.page.elements.ad_number.send_keys(adno)
return self
def select_time(self, time):
"""选择 距首次执行时间"""
self.page.elements.time_to_first_run.click()
self.sleep(2)
self.page.elements.dropdown_selectlist(time).click()
return self
def search(self):
"""点击 查询按钮"""
self.page.elements.search_btn.click()
return self
def reset(self):
"""点击 重置按钮"""
self.page.elements.reset_btn.click()
return self
def click_row(self, rowinfo, match_more=False):
"""根据条件 点击表格中的行的复选框
Args:
rowinfo: 表格中行的列信息,键定义如下
taskno: 审核任务编号
adno: 广告编号
orderno: 订单数量
filmno: 影片数量
status: 审核状态
match_more: see self.page.elements.table_row_checkbox
"""
cbs = self.page.elements.table_row_checkbox(rowinfo, match_more=match_more)
if match_more:
for cb in cbs:
cb.click()
else:
cbs.click()
return self
def audit(self, rowinfo):
"""点击 审核按钮"""
self.page.elements.audit_btn(rowinfo).click()
return self
def audit_record(self, rowinfo):
"""点击 审核记录按钮"""
self.page.elements.audit_record_btn(rowinfo).click()
return self
app页面封装 1
from selenium.common.exceptions import NoSuchElementException
from appium.webdriver.extensions.android.nativekey import AndroidKey
from sevenautotest.utils import helper
from sevenautotest.utils import TestAssert as ta
from sevenautotest.basepage import BasePage
from sevenautotest.basepage import PageElementLocators as page_element_locators
__author__ = "si wen wei"
class SettlementFilmDetailPage(BasePage):
"""
中影发行结算->影片信息页面
"""
class Elements(BasePage.Elements):
@property
@page_element_locators()
def film_info_view(self, locators):
"""影片信息区域
"""
uia_string = locators.get("影片信息view")
return self.page.find_element_by_android_uiautomator(uia_string)
@property
@page_element_locators()
def film_name_view(self, locators):
"""影片名称区域"""
xpath = locators.get("影片名称view")
timeout = locators.get("查找元素超时时间(秒)", "7")
return self.page.find_element_by_xpath(xpath, timeout=float(timeout))
@property
@page_element_locators()
def show_time_view(self, locators):
"""上映时间区域"""
xpath = locators.get("上映时间view")
timeout = locators.get("查找元素超时时间(秒)", "7")
return self.page.find_element_by_xpath(xpath, timeout=float(timeout))
@property
@page_element_locators()
def settlement_box_office_view(self, locators):
xpath = locators.get("结算票房view")
timeout = locators.get("查找元素超时时间(秒)", "7")
return self.page.find_element_by_xpath(xpath, timeout=float(timeout))
@property
@page_element_locators()
def zhongying_pf_view(self, locators):
"""中影票房view"""
xpath = locators.get("中影票房view")
return self.page.find_element_by_android_uiautomator(xpath)
@property
@page_element_locators()
def shouri_pf_view(self, locators):
"""首日票房view"""
xpath = locators.get("首日票房view")
return self.page.find_element_by_xpath(xpath)
@property
@page_element_locators()
def shouzhoumo__pf_view(self, locators):
"""首周末票房view"""
xpath = locators.get("首周末票房view")
return self.page.find_element_by_xpath(xpath)
@property
@page_element_locators()
def qian7tian_pf_view(self, locators):
"""前7天票房view"""
xpath = locators.get("前7天票房view")
return self.page.find_element_by_xpath(xpath)
@property
@page_element_locators()
def danrizuigao_pf_view(self, locators):
"""单日最高票房view"""
xpath = locators.get("单日最高票房view")
return self.page.find_element_by_xpath(xpath)
@property
@page_element_locators()
def see_more_view(self, locators):
"""查看更多view"""
xpath = locators.get("查看更多view")
return self.page.find_element_by_xpath(xpath)
@page_element_locators()
def datetime_fx_view(self, locators, film_name):
"""发行有效日期view"""
xpath = locators.get("发行有效日期view")
xpath = xpath % film_name
return self.page.find_element_by_xpath(xpath, parent=self.search_result_area)
@page_element_locators()
def film_type_fx_view(self, locators, film_name):
"""发行版本view"""
xpath = locators.get("发行版本view")
xpath = xpath % film_name
return self.page.find_element_by_xpath(xpath, parent=self.search_result_area)
@property
@page_element_locators()
def fx_detail_btn(self, locators):
"""进入发行信息详情页按钮"""
xpath = locators.get("进入按钮")
return self.page.find_element_by_xpath(xpath)
class Actions(BasePage.Actions):
def swipe_to_select_year(self, year, direction="down", distance=70, limit_times=20, current_count=1):
"""选择年
@param year 目标年份
@param direction 首次滑动方向 down --- 向下 up --- 向上
@param distance 每次滑动距离
@param limit_times 递归次数
@param current_count 当前递归计数
"""
selector = self.page.elements.year_selector
text_before_swipe = selector.get_attribute("text")
if year == text_before_swipe:
return self
if current_count > limit_times:
msg = "找不到: %s, 请检查" % year
raise NoSuchElementException(msg)
def _swipe_year_area(times=1):
selector.click()
view = self.sleep(2).page.elements.year_select_area
x = view.location['x']
y = view.location['y']
height = view.size['height']
width = view.size['width']
start_x = x + width / 2
start_y = y + height / 2
end_x = start_x
if direction.upper() == "down".upper():
end_y = start_y + distance
else:
end_y = start_y - distance
for n in range(times):
self.page.driver.swipe(start_x, start_y, end_x, end_y)
self.click_confirm_btn()
self.page.sleep(3)
_swipe_year_area(1)
text_after_swipe = selector.get_attribute("text")
if year == text_after_swipe:
return self
if text_before_swipe == text_after_swipe:
if direction.upper() == "down".upper():
direction = "up"
else:
direction = "down"
else:
target_year = helper.cutout_prefix_digital(year)
year_before_swipe = helper.cutout_prefix_digital(text_before_swipe)
year_after_swipe = helper.cutout_prefix_digital(text_after_swipe)
if target_year and year_before_swipe and year_after_swipe:
t = int(target_year)
a = int(year_after_swipe)
b = int(year_before_swipe)
if a > b:
if t < a:
direction = "up" if direction.upper() == "down".upper() else "down"
else:
if t > a:
direction = "up" if direction.upper() == "down".upper() else "down"
_swipe_year_area(abs(t - a))
self.page.sleep(1)
self.swipe_to_select_year(year, direction, distance, limit_times=limit_times, current_count=current_count + 1)
return self
def zhongying_pf_equals(self, box_office):
"""中影票房是否正确"""
expected = box_office
actual = self.page.elements.zhongying_pf_view.get_attribute("text")
ta.assert_equals(actual, expected)
return self
def shouri_pf_equals(self, box_office):
"""首日票房是否正确"""
expected = box_office
actual = self.page.elements.shouri_pf_view.get_attribute("text")
ta.assert_equals(actual, expected)
return self
def shouzhoumo_pf_equals(self, box_office):
"""首周末票房是否正确"""
expected = box_office
actual = self.page.elements.shouzhoumo__pf_view.get_attribute("text")
ta.assert_equals(actual, expected)
return self
def qian7tian_pf_equals(self, box_office):
"""前7天票房是否正确"""
expected = box_office
actual = self.page.elements.qian7tian_pf_view.get_attribute("text")
ta.assert_equals(actual, expected)
return self
def danrizuigao_pf_equals(self, box_office):
"""单日最高票房是否正确"""
expected = box_office
actual = self.page.elements.danrizuigao_pf_view.get_attribute("text")
ta.assert_equals(actual, expected)
return self
def input_film_name(self, film_name):
"""输入影片名称"""
self.page.elements.film_name_inputbox.clear()
self.page.elements.film_name_inputbox.send_keys(film_name)
return self
def click_confirm_btn(self):
"""点击确定按钮"""
self.page.elements.confirm_btn.click()
return self
def click_cancel_btn(self):
"""点击取消按钮"""
self.page.elements.cancel_btn.click()
return self
def click_search(self):
self.page.press_keycode(AndroidKey.ENTER)
return self
def click_film_item(self, film_name):
"""点击结算影片项"""
self.page.elements.film_in_search_result_area(film_name).click()
return self
微信小程序页面封装示例 1
from sevenautotest.basepage.base_minium_page import BaseMiniumPage
class ADBasketPage(BaseMiniumPage):
""" 广告篮页面 """
class Elements(BaseMiniumPage.Elements):
@property
def do_ad_btn(self):
"""去投放广告"""
selector = '#cart'
inner_text = '去投放广告'
return self.page.get_element(selector).get_element('view').get_element('view').get_element('button', inner_text=inner_text)
@property
def tabbar(self):
"""首页下方tab工具栏"""
selector = '.mp-tabbar'
return self.page.get_element(selector)
@property
def home_tab(self):
"""首页 标签"""
selector = '.weui-tabbar__label'
inner_text = "首页"
return self.tabbar.get_element(selector, inner_text=inner_text)
@property
def ad_tab(self):
"""广告篮 标签"""
selector = '.weui-tabbar__label'
inner_text = "广告篮"
return self.tabbar.get_element(selector, inner_text=inner_text)
@property
def order_tab(self):
"""订单 标签"""
selector = '.weui-tabbar__label'
inner_text = "订单"
return self.tabbar.get_element(selector, inner_text=inner_text)
class Actions(BaseMiniumPage.Actions):
def click_do_ad_btn(self):
"""点击去投放广告按钮"""
self.page.elements.do_ad_btn.click()
return self
def click_tabbar(self):
"""点击下方标签工具栏"""
self.page.elements.tabbar.click()
return self
def click_home_tab(self):
"""点击下方首页标签"""
self.page.elements.home_tab.click()
return self
def click_ad_tab(self):
"""点击下方广告篮标签"""
self.page.elements.ad_tab.click()
return self
def click_order_tab(self):
"""点击下方订单标签"""
self.page.elements.order_tab.click()
return self
用例编写 测试用例类需要继承测试基类 BaseTestCase测试方法需要接收一个参数,参数化时框架会自动从测试数据文件取出的该方法测试数据作为字典传给该测试方法测试方法需要使用标记pytest.mark.testcase进行标记,才会被当作测试用例进行收集,使用位置参数设置用例名,关键字参数说明如下: enable控制是否执行该用例,布尔值,如果没有该关键字参数则默认为Truepriority设置用例执行优先级,控制用例的执行顺序,整型数值,如果没有该参数则不会调整该用例的执行顺序author自动化用例代码编写人editor自动化用例代码修改人
示例如下:
web页面测试用例示例
import pytest
from sevenautotest.basetestcase import BaseTestCase
from sevenautotest.testobjects.pages.samples.qqemail.LoginEmailPage import LoginEmailPage
class LoginEmailPageTest(BaseTestCase):
"""
登录页面测试示例
"""
def setup_class(self):
pass
def setup_method(self):
pass
@pytest.mark.testcase("成功登陆测试", author="siwenwei", editor="")
def test_successfully_login(self, testdata):
name = testdata.get("用户名")
pwd = testdata.get("密码")
url = testdata.get("登录页面URL")
page = LoginEmailPage()
page.chrome().maximize_window().open_url(url).actions.select_login_frame().sleep(1).username(name).password(pwd).sleep(2).move_to_login_btn().sleep(10).login().sleep(3)
page.screenshot("successfully login.png")
page.sleep(3)
def teardown_method(self):
pass
def teardown_class(self):
self.DRIVER_MANAGER.close_all_drivers()
if __name__ == "__main__":
pass
app页面测试用例示例
import pytest
from sevenautotest import settings
from sevenautotest.basetestcase import BaseTestCase
from sevenautotest.testobjects.pages.apppages.fxjs.LoginPage import LoginPage
from sevenautotest.testobjects.pages.apppages.fxjs.HomePage import HomePage
from sevenautotest.testobjects.pages.apppages.fxjs.SettlementMainPage import SettlementMainPage
class LoginPageTest(BaseTestCase):
"""中影发行结算登录页面测试"""
def setup_class(self):
self.desired_caps = settings.APP_DESIRED_CAPS
self.server_url = settings.APPIUM_SERVER
def setup_method(self):
pass
@pytest.mark.testcase("根据影片名查询指定年份的票房测试", author="siwenwei", editor="")
def test_film_box_office(self, testdata):
film = testdata.get("影片名称")
year = testdata.get("年份")
page = LoginPage()
page.open_app(self.server_url, desired_capabilities=self.desired_caps, implicit_wait_timeout=10)
page.actions.click_continue_btn().sleep(2).click_confirm_btn().sleep(2).username(settings.APP_USER_ACCOUNT).password(settings.APP_USER_PASSWORD).login().sleep(2).reminder().sleep(7)
HomePage().actions.sleep(2).click_settlement_tab()
sp = SettlementMainPage()
sp.actions.sleep(7).swipe_to_select_year(year).sleep(7).input_film_name(film).click_search().sleep(3)
page.hide_keyboard()
sp.actions.click_film_item("单行道")
def teardown_method(self):
pass
def teardown_class(self):
self.DRIVER_MANAGER.close_all_drivers()
if __name__ == "__main__":
pass
微信小程序页面测试用例示例
import pytest
from sevenautotest import settings
from sevenautotest.utils import helper
from sevenautotest.basetestcase import BaseTestCase
from sevenautotest.testobjects.pages.apppages.yy.indexpage import IndexPage
from sevenautotest.testobjects.pages.apppages.yy.cinema_list_page import CinemaListPage
from sevenautotest.testobjects.pages.apppages.yy.my_adlist_page import MyAdListPage
class YuyanTest(BaseTestCase):
"""雨燕测试"""
def setup_class(self):
self.WECHAT_MANAGER.init_minium()
def setup_method(self):
pass
@pytest.mark.testcase('广告投放界面->广告视频显示的正确性 - 影院列表>去上传广告片', author="siwenwei", editor="")
def test_jump_page_of_click_upload_ad(self, testdata):
fn_name = helper.get_caller_name()
ipage = IndexPage(settings.URLS['首页'])
ipage.actions.click_tabbar().sleep(1).click_home_tab().sleep(1).click_cinema_ad_btn()
clpage = CinemaListPage()
clpage.actions.sleep(1).screenshot('{}_影院列表_'.format(fn_name)).is_page_self(settings.URLS['影院列表']).upload_ad().sleep(2)
p = MyAdListPage()
p.actions.screenshot('{}_我的广告素材_'.format(fn_name)).is_page_self()
@pytest.mark.testcase('广告投放界面->广告视频显示的正确性 - 影院列表>广告片显示>更换广告片', author="siwenwei", editor="")
def test_change_ad_to_another_in_cinemalist(self, testdata):
oad_name = testdata.get('广告名(原)')
nad_name = testdata.get('广告名(新)')
ipage = IndexPage(settings.URLS['首页'])
ipage.actions.click_tabbar().sleep(1).click_home_tab().sleep(1).click_cinema_ad_btn()
clpage = CinemaListPage()
clpage.actions.sleep(1).is_page_self(settings.URLS['影院列表']).upload_ad().sleep(2)
p = MyAdListPage()
p.actions.is_page_self().click_ad_checkbox(oad_name).sleep(1).to_launch().sleep(2)
clpage.actions.change().sleep(1)
p.actions.click_ad_checkbox(nad_name).sleep(1).to_launch().sleep(2)
clpage.actions.find_ad_name(nad_name)
def teardown_method(self):
pass
def teardown_class(self):
self.WECHAT_MANAGER.release_minium()
if __name__ == "__main__":
pass
测试执行直接运行主目录下的TestRunner.py,也可以在命令行使用pytest命令执行
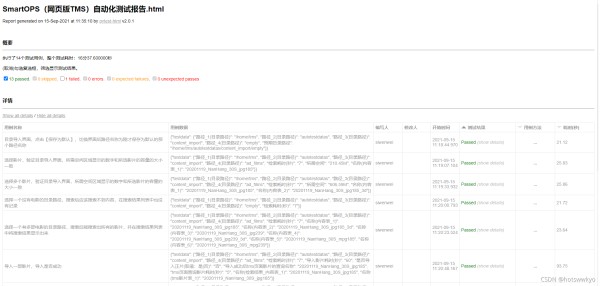
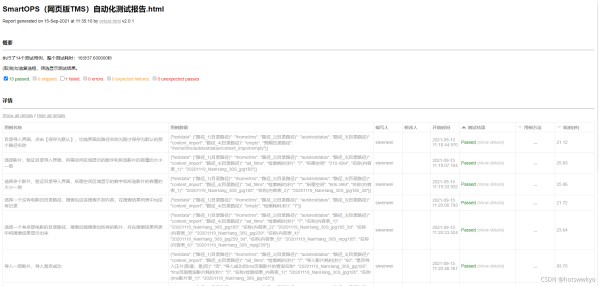
用例失败自动截图和定制HTML测试报告默认生成的HTML测试报告信息太简单,我们需要增加用例中文名称、测试数据、用例编写人等关键信息列,附加失败截图到HTML报告,实现代码如下:
@pytest.mark.optionalhook
def pytest_html_results_table_header(cells):
cells.insert(0, html.th('用例名称', style="width:30%;"))
cells.insert(1, html.th('用例数据', style="width:36%;"))
cells.insert(2, html.th('编写人', style="width:5%;"))
cells.insert(3, html.th('修改人', style="width:5%;"))
cells.insert(4, html.th("开始时间"))
cells.pop()
change_opts = {
"Test": {
"text": "用例方法",
"style": "width: 7%;"
},
"Duration": {
"text": "耗时(秒)",
"style": "width:9%;"
},
"Result": {
"text": "测试结果",
"style": "width:10%;"
},
}
for cell in cells:
value = cell[0] if cell else ""
if value in change_opts:
details = change_opts[value]
cell[0] = details["text"]
skey = "style"
if skey in details:
add_style = details.get(skey, "")
style = cell.attr.__dict__.get("style", "")
if style:
cell.attr.__dict__.update(dict(style="{};{}".format(style.rstrip(";"), add_style)))
else:
cell.attr.__dict__.update(dict(style=add_style))
@pytest.mark.optionalhook
def pytest_html_results_summary(prefix, summary, postfix):
style_css = 'table tr:hover {background-color: #f0f8ff;};'
js = """
function append(targentElement, newElement) {
var parent = targentElement.parentNode;
if (parent.lastChild == targentElement) {
parent.appendChild(newElement);
} else {
parent.insertBefore(newElement, targentElement.nextSibling);
}
}
function prettify_h2(){
var h2list = document.getElementsByTagName("h2");
var cnmaps = [['Environment', '环境'], ['Summary', '概要'], ['Results', '详情']];
var env = cnmaps[0][0];
var is_del_env_area = true;
var env_indexs = [];
for(var i=0;i<h2list.length;i++){
var h2 = h2list[i];
if(env == h2.innerText){
env_indexs.push(i);
if(!is_del_env_area){
append(h2, document.createElement('hr'));
}
}else{
for(var s=0;s<cnmaps.length;s++){
var onemap = cnmaps[s];
if(h2.innerText == onemap[0]){
append(h2, document.createElement('hr'));
break;
}
}
}
h2.style.marginTop = "50px";
for(var j=0;j<cnmaps.length;j++){
var one = cnmaps[j];
if(h2.innerText == one[0]){
h2.innerText = one[1];
break;
}
}
}
if(!is_del_env_area){
return;
}
for(var k=0;k<env_indexs.length;k++){
var index = env_indexs[k];
var h2 = h2list[index];
var el_env = document.getElementById('environment');
h2.parentNode.removeChild(h2);
if(el_env){
el_env.parentNode.removeChild(el_env);
}
}
}
var event_func = document.body.onload;
document.body.onload = function(){return false;};
if (window.attachEvent) {
window.attachEvent("onload", event_func);
window.attachEvent("onload", prettify_h2);
} else if (window.addEventListener) {
window.addEventListener("load", event_func, false);
window.addEventListener("load",prettify_h2, false);
}
"""
prefix.extend([html.style(raw(style_css))])
prefix.extend([html.script(raw(js))])
for item in summary:
if not item:
continue
text = item[0]
if text == "(Un)check the boxes to filter the results.":
item[0] = "(取消)勾选复选框,筛选显示测试结果。"
elif 'tests ran in' in text:
parts = text.split(" ")
try:
total = parts[0]
seconds = parts[-3]
except IndexError:
pass
else:
try:
seconds = helper.SevenTimeDelta(seconds=float(seconds)).human_readable()
except Exception:
pass
item[0] = "执行了{}个测试用例,整个测试耗时:{}".format(total, seconds)
@pytest.mark.optionalhook
def pytest_html_results_table_row(report, cells):
cells.insert(0, html.td(getattr(report, "description", "")))
cells.insert(1, html.td(getattr(report, "testdata", "")))
cells.insert(2, html.td(getattr(report, "author", "")))
cells.insert(3, html.td(getattr(report, "editor", "")))
cells.insert(4, html.td(getattr(report, "testcase_exec_start_time", "")))
cells.pop()
method_names = [report.nodeid]
whenlist = ['setup', 'call', 'teardown']
for when in whenlist:
suffix = "::" + when
if not report.nodeid.endswith(suffix):
method_names.append(report.nodeid + suffix)
copy_to_clipboard = "var transfer = document.createElement('input');this.appendChild(transfer);transfer.value = this.title;transfer.focus();transfer.select();if (document.execCommand('copy')) {document.execCommand('copy');};transfer.blur();this.removeChild(transfer);"
for cell in cells:
value = cell[0] if cell else ""
if value in method_names:
cell[0] = "..."
cell.attr.__dict__.update(dict(title=value, style="text-align: center;font-weight: bold;", onclick=copy_to_clipboard))
@pytest.mark.hookwrapper
def pytest_runtest_makereport(item, call):
pytest_html = item.config.pluginmanager.getplugin('html')
outcome = yield
report = outcome.get_result()
report.description = item.function.__doc__ if item.function.__doc__ else item.function.__name__
extra = getattr(report, 'extra', [])
args = {}
for argname in item._fixtureinfo.argnames:
args[argname] = item.funcargs[argname]
setattr(report, "testdata", json.dumps(args, ensure_ascii=False))
if report.when == "call":
xfail = hasattr(report, "wasxfail")
if (report.skipped and xfail) or (report.failed and not xfail):
try:
mm = item.cls.WECHAT_MANAGER
if mm.native:
fp = mm.screenshot(report.description)
any([fp])
except Exception as e:
print(str(e))
try:
driver = item.cls.DRIVER_MANAGER.driver
except NoOpenBrowser:
driver = None
capturer = ScreenshotCapturer(driver)
img_base64 = capturer.screenshot_as_base64()
if settings.ATTACH_SCREENSHOT_TO_HTML_REPORT:
template = """<div><img src="https://img-blog.csdnimg.cn/2022010614464462956.png" alt="%s" style="width:600px;height:300px;" onclick="window.open(this.src)" align="right"/></div>"""
html = template % (img_base64 if img_base64 else """<div>截图失败</div>""", "screenshot of test failure")
extra.append(pytest_html.extras.html(html))
report.extra = extra
report.nodeid = report.nodeid.encode("utf-8").decode("unicode_escape")
for marker in item.iter_markers(settings.TESTCASE_MARKER_NAME):
for k, v in marker.kwargs.items():
setattr(report, k, v)
report.testcase_exec_start_time = getattr(item, "testcase_exec_start_time", "")
效果如下图:
源码
源码在本人github上,可自行下载!
网址:基于pytest设计自动化测试框架实战 https://www.yuejiaxmz.com/news/view/538361
相关内容
【书单】自动化测试书籍推荐?自动化测试书籍哪个好?笔者亲自看过后推荐!Nico,从零开始干掉 Appium,移动端自动化测试框架实现(一) · 测试之家
推荐一款新的自动化测试框架:DrissionPage
pytest做压力测试
自动化测试流程(超详细总结)
Web自动化测试工具Selenium
自动化测试流程(超详细整理)
自动化测试优势、劣势、工具和框架选择全剖析!
自动化测试框架工具pytest教程
自动化测试框架应该怎么选?Selenium、Playwright和Cypress详细对比
随便看看
最新动态分享
- 《厨艺+料理的常识2册套装 下厨准备基本功和家常美食技法图谱 新手学做菜的书 厨具食材处理烹饪方式菜谱图鉴 速发》 【简介
- 【正版】大厨教你花小钱做大菜 新手学下厨家常菜谱书图文详解实用家庭菜谱 生活烹饪食谱大全书籍做菜书籍生活烹饪食谱大全书籍
- 《抖音同款餐桌上的中药学些吃饭的智慧 家庭生活备百病食疗饮食医学书籍营养养生餐健康美食菜谱早餐烹饪家常菜教程大全》 【简介
- 《小学生能做好的100道菜 小学生做饭 做菜 五步之内完成让孩子快速掌握烹饪技巧锻炼孩子的生活实践能力菜谱书籍全新书籍》 【简介
- 《烹饪原料学》生活科普丛书
- 厨艺学习之路的做法
- SpringBoot+Vue 美食烹饪互动平台平台完整项目源码+SQL脚本+接口文档【Java Web毕设】
- 如何用小程序学习厨艺?浩发科技带你玩转厨房
- 烹饪工艺与营养专业大学生该如何度过大学生活 免费文案+PPT模板下载
- 我为群众办实事 | 关爱一群人 温暖一座城
热点动态分享
- 137381
- 40748
- 36456
- 25139
- 24738
- 23842
- 21562
- 16261
- 15045
- 15023

