
在自己的行业待久了之后,就想着看看别的行业是怎么玩大数据的。
行业的不同,落实到数据模型和技术手段就会有不一样。
本着探索的精神,我每隔一段时间就想着搜罗一下不同的应用。
互联网总有一些喜欢分享的朋友,我最喜欢去找灵感和案例的地方,是在infoQ.
当然国内的极客邦,CSDN也不错,甚至有些应用已经属于前端黑科技。
总有看不完的新鲜应用,所以一个一个的去淘吧,有感觉就满足了。
今天看到 InfoQ 上一个利用大数据监测物联网的应用,翻译和笔记如下:
出处:
Traffic Data Monitoring Using IoT, Kafka and Spark Streaming
URL:https://www.infoq.com/articles/traffic-data-monitoring-iot-kafka-and-spark-streaming
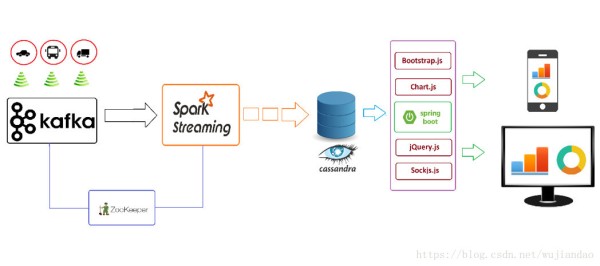
本文的结构思路异常清晰:
IoT Data Producer: 数据源头,是各类互联的设备,比如家用电器,电子产品,文章讨论的是各类交通工具的互联。中国2017年的汽车市场大约是 2800 万辆,也就是说,一秒钟的时间,可能就有 2800 万条数据,从各类汽车传输到互联网上,对比2017年淘宝双11,峰值达到 32万每秒的交易,可谓是又一个大数据落地的领域。就算是 1%的汽车联网(实际上肯定不止),那数据量也是接近双11 这峰值。利用嵌入的 Kafka 向 Spark Streaming 进程发送数据,完成主动监测的第一步。
IoT Data Processor: 真正完成大数据计算的正是这一步,Sparking Streaming 接收到前端 Kafka 传进来的数据,解析,转换,并最终完成计算统计值的计算。经过刚才第一步的描述,中国国内的汽车市场是个非常庞大的数字,要实时完成这些汽车总量的监测指标统计,计算吞吐量势必要跟得上。而 Sparking Streaming 的处理,本质上还停留在像《Design Data-Intensive Applications》中描述的,是通过微批次处理(即极短时间内连续的批次)来对数据做转换的一种方式。所以网友对此类场景应用 Spark Streaming 还是略有担心,是否该换 Flink 上场。那两者的对比,我们可以换个主题来讨论,现在暂时拉回到本文中来,继续讨论 Spark Streaming 能完成的这类统计任务,到底可以有哪些,而这些分门别类的统计任务,就是大数据产品的落地。
互联的车辆总量 ;
互联的车辆,各品牌占比 ;
互联的车辆,总体的碳排放量 ;
每条路上,各个时段的拥堵程度;
计算结果的存储是放在 Casssandra database. 至于它与其他数据库的不同以及为什么要在这里用它,暂不讨论。当然你说放 Hive 可不可以,那也是没问题的。甚至愿意放 SQL Server, MySQL, Oracle 都没有问题,因为 Spark Streaming 支持的语言有 Python, Scala, Java 都有对应的数据库接口。
Iot Data Dashboard: 数据可视化是最终呈现项目成果的一环。对于监测机构来说,可以适配多屏,考验着技术实现。对于车主来说,在手机,车内导航上实时显示路况,车耗等也同样需要小屏的信息呈现。在本文中,作者使用了 Spring Boot 来获取 Cassandra database 中存储的信息,并发送给多屏控制主机做呈现。这是一种主动推送的机制,数据能够在短时间内实现刷新。Dashboard 采用表和图的展现方式,以 bootstrap.js 作为交互接口。
文章的最后还有实现代码,这就不能贴上来了,一来是排版不好看,二来鼓励大家看原版。

