基于深度学习的垃圾分类识别系统
科技助力环保,例如垃圾分类的智能识别系统 #生活知识# #生活感悟# #科技生活变迁# #科技与生活深度融合#
目录
摘要
深度学习算法实现
垃圾分类识别系统
结束
摘要随着我国经济的飞速发展,人民生活水平的提高,生活垃圾的产生量也急剧增加。垃圾种类繁多,材质、颜色和外形各异,而且在不同地域和不同场景下的类别划分差异也很大。比如有按干/湿划分类别的,有按可燃/不可燃划分类别的等。人工智能技术的发展使得自动识别垃圾种类成为可能。但是,因为垃圾种类众多,所收集的垃圾数据集存在极大的平衡性。为了解决这一问题,因此,本次博客探索了将焦点损失函数应用于多层卷积神经网络的垃圾识别中。并将训练好的模型加载到web应用中,实现一个简单的垃圾图像的识别与分类系统界面。
深度学习算法实现卷积神经网络:
此次又用了CNN,原因很简单,容易实现。哈哈....
焦点损失函数(Focal Loss):
焦点损失函数 (Focal Loss)在2017年被提出,被应用于密集物体检测任务。在该任务下的背景类别不平衡(Extreme foreground-background class imbalance)是提出该损失函数的一个重要原因。作者通过重塑标准交叉熵损失解决了这一类不平衡问题,从而降低分配给分类示例的损失。该论文提出的焦点损失(Focal Loss)方法将训练集中在一系列难点上,并且防止了大量的负面例子在训练过程中阻碍探测器学习。正是因为Focal Loss可以解决样本的不平衡问题。因此,很多人将此方法应用到不同问题的解决上。其公式如下:

公式可以自行查看原文推导。焦点损失函数旨在通过降低内部加权(简单样本)来解决类别不平衡问题,这样即使简单样本的数量很大,但它们对总损失的贡献却很小。也就是说,该函数侧重于用困难样本稀疏的数据集来训练。focal loss 有两个可调的参数。焦点参数γ(gamma)平滑地调整简单样本被加权的速率。当γ= 0时, focal loss 效果与交叉熵函数相同,并且随着 γ 增加,调制因子的影响同样增加(γ = 2在实验中表现的效果最好)。α(alpha):平衡focal loss ,相对于非 α 平衡形式可以略微提高它的准确度。
因为我们是多分类任务,所以focal loss代码实现为:
def categorical_focal_loss(gamma=2.0, alpha=0.25):
def focal_loss(y_true, y_pred):
# Define epsilon so that the backpropagation will not result in NaN
# for 0 divisor case
epsilon = K.epsilon()
# Add the epsilon to prediction value
# y_pred = y_pred + epsilon
# Clip the prediction value
y_pred = K.clip(y_pred, epsilon, 1.0 - epsilon)
# Calculate cross entropy
cross_entropy = -y_true * K.log(y_pred)
# Calculate weight that consists of modulating factor and weighting factor
weight = alpha * y_true * K.pow((1 - y_pred), gamma)
# Calculate focal loss
loss = weight * cross_entropy
# Sum the losses in mini_batch
loss = K.sum(loss, axis=1)
return loss
return focal_loss
核心代码实现:
def cnn_model(input_shape, num_classes):
# create model
model = Sequential()
model.add(Conv2D(96, kernel_size=11, strides=4, activation='relu', input_shape=input_shape))
model.add(MaxPooling2D(pool_size=3, strides=2))
model.add(Conv2D(256, kernel_size=5, strides=1, activation='relu'))
model.add(MaxPooling2D(pool_size=3, strides=2))
model.add(Conv2D(384, kernel_size=3, strides=1, activation='relu'))
model.add(Conv2D(384, kernel_size=3, strides=1, activation='relu'))
model.add(Conv2D(256, kernel_size=3, strides=1, activation='relu'))
model.add(MaxPooling2D(pool_size=3, strides=2))
model.add(Flatten())
model.add(Dropout(0.5))
model.add(Dense(4096))
model.add(Activation(lambda x: K.relu(x, alpha=1e-3)))
model.add(Dropout(0.5))
model.add(Dense(4096))
model.add(Activation(lambda x: K.relu(x, alpha=1e-3)))
model.add(Dense(num_classes, activation="softmax"))
model.compile(optimizer='adam', loss=focal_loss, metrics=['accuracy'])
return model
垃圾分类识别系统实现环境与依赖库:
python3.6 ,Flask,Keras, Keras-Applications, Keras-Preprocessing, tensorflow等;
app.py代码结构:
app.py代码下加载训练好的模型,实现语句为:
MODEL_PATH = 'cnn_model.h5'
model = load_model(MODEL_PATH,compile = False)#, compile = False
model._make_predict_function() # Necessary
然后对上传的图像进行预处理,并返回输出:
def model_predict(img_path, model):
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
# Be careful how your trained model deals with the input
x = preprocess_input(x, mode='caffe')
preds = model.predict(x)
return preds
最后便是常用的GET和POST方法实现页面的显示。
实现界面测试:
界面显示如下:左下为上传图片并实现预测,右边为垃圾分类相关的科普知识。

点击科普知识,进入百度百科:

点击选择图像,可以进行图像的选择,并输出预测结果:
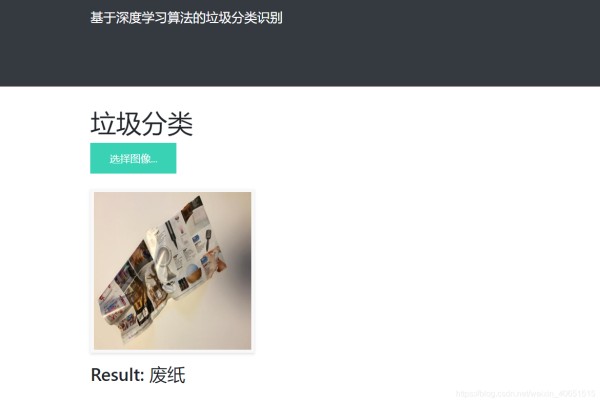
这次只是简单的实现了应用flask加载深度学习模型,并将预测的返回结果输出到显示页面。下一步将尝试更为复杂的系统页面功能,如果大家有相关建议或者对这个实现这个功能有想法可以加Q:525894654。深度学习方法上,尝试实现ResNet50进行更多种类的垃圾分类。
网址:基于深度学习的垃圾分类识别系统 https://www.yuejiaxmz.com/news/view/586567
相关内容
基于深度学习的生活垃圾检测与分类系统(网页版+YOLOv8/v7/v6/v5代码+训练数据集)毕业设计:基于机器学习的生活垃圾智能分类系统
一种基于语音识别技术的垃圾分类系统的制作方法
基于单片机的语音识别智能垃圾桶垃圾分类的设计与实现
46城强制垃圾分类 计划建成生活垃圾分类处理系统
生活垃圾分类处理系统 生活垃圾筛分生产线设备
智能垃圾分类系统的优势
一种基于深度学习的个性化推荐系统
基于水力分选及资源利用的生活垃圾处理系统研究
厦门数据垃圾分类综合系统 欢迎咨询「深圳冠扬环境工程供应」
随便看看
最新动态分享
- 中电建物业西南区域低碳手工活动圆满举办
- 节能环保改造对创建绿色饭店的促进意义
- 2025年内蒙古实施农牧区危房改造5437户
- 巧手改造——绿洲社用创意让“废盒”焕新颜
- 酒店大扫除怎么过原神 《原神》酒店大扫除任务攻略
- 直击现场!商场、酒店、废品站这样开展爱国卫生运动
- 保洁,保洁公司,专业酒店保洁,大型开荒保洁,沙发地毯保养清洗,厂房地面保洁,擦玻璃,地铁站开荒保洁,深度精细铺商场学校医院保洁,别墅厂房店保洁
- 美食烹饪助手软件最新版下载
- 做菜好的APP推荐
- 做饭的工具有哪些APP推荐
热点动态分享
- 136497
- 38098
- 36269
- 23778
- 23364
- 22603
- 21381
- 15027
- 14958
- 14908

