隐私保护的数据挖掘综述
如何进行文献综述:系统性和深度挖掘 #生活技巧# #学习技巧# #学术研究指南#
前言
对于人嘛,总是将事情想象的多么美好,这不。到自己真正的接触了学术研究,才发现那无尽的代码才能带来真正快乐源泉(虽然没有深层次的技术含量)。但是,为了自己选择的路,即使作为一名科研狗也得走下去。
综述论文素材
前辈们都会谦虚的说,做学问论文不是过程,而是结果。自然在接下来长达三年的日子里我知道了我将与论文接下不解之缘。我仰慕它、研读它,最终将它融会于心。
据说新手刚接触研究论文,可以多看看综述。这是笔者找的。
待掌握知识
概念数据挖掘隐私保护(Privacy Preserving Data Mining,简称 PPDM)
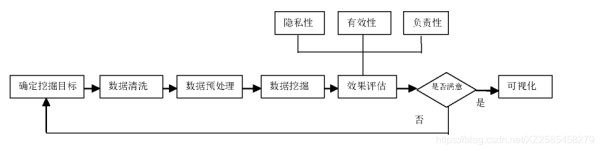
隐私保护数据挖掘流程隐私保护数据挖掘的流程主要包括以下几步:
( 1 ) 明确数据挖掘目标 。
( 2 ) 数据清洗 。即剔除或者隐藏 原始数据中的敏感数据。
( 3 ) 数据预处理 。 即对清洗后的数据进行转换和加密 。
( 4 ) 数据挖掘。 选择合适的数据挖掘算法进行数据挖掘 。
( 5 ) 效果评估 。度量指标主要包括 : 隐私性 , 即非法识别隐私信的可能性大小 ; 有效性 , 即数据挖掘得到的最终结果的准确性 ; 复杂性 , 即算法的时间复杂性和空间复杂性 。
( 6 ) 可视化表示 。用可视化工具对挖掘结果进行知识表示 。
如下图所示:
当然对于总多科研大佬提出的各个分支下面的算法未表明,原因很简单,这只是初步概况。后期嘿嘿嘿
扰动算法包括随机化扰动算法(随机添加噪声、数据转换矩阵、k-means和多重随机哈)和乘法扰动算法(旋转扰动算法和投影扰动算法)。k匿名算法
k匿名的两种主要算法是泛化和抑制化。关联规则隐藏算法
常见的关联规则隐藏算法包括启发式算法、基于边界的算法和精准式算法。 通用评价指标
( 1 ) 数据质量 , 在进行有隐私保护的数据挖掘中 , 通常要对数据进行 一些处理 , 而这些处理对于数据可能是有损的 , 故而进一步对挖掘前后的数据集造成偏差 。但是不会对数据挖掘的的结果造成影响或者影响很小 。通常就精准度 、一致性和完整性等来度量数据质量的好坏。
( 2 ) 性能代价 , 归根结底隐私保护数据挖掘依然是数据挖掘 , 性能仍然是对于挖掘方法的重要考量 。通过对于时间复杂度以及空间负责度的评估来度量性能的好坏 。
( 3 ) 伸缩性 , 通常指的是对目标数据集进行相关的放大以及缩小的操作时 , 如何有效的保护数据集的属性 , 并 具有 良好的性能指标 。
( 4 ) 隐私 程度 , 这是最核心 的指标 , 也是最难衡量 的指标 。 基于信息嫡的研究有大量的成果 , 也是比较被接受的方法 。Agrawal 和Agarwal最早提出刚信息嫡的方法 , Berino等进行了有效的扩展。
后记
无论如何路是自己选的,是进还是退。亦或者在学术的过程中去追寻那想要的一切,这一切都待继续努力才行。
网址:隐私保护的数据挖掘综述 https://www.yuejiaxmz.com/news/view/733432
相关内容
数据挖掘中的隐私保护数据隐私,数据隐私保护:如何保护个人数据安全?
数据隐私与安全保护指南.pptx
智能家居知识图谱的数据挖掘技术
生活中的数据挖掘模式,生活中数据挖掘的例子
如何保护自己的隐私数据
大数据时代的隐私保护
数据安全与隐私保护:大数据时代的挑战与机遇
数据隐私保护:保护用户隐私的最佳实践
数据安全 隐私,数据时代隐私安全
随便看看
最新动态分享
- 家庭消毒不用愁!5大物理消毒法守护健康生活
- カビをアルコール退治|消毒用エタノールでの除菌方法やNG使用法も
- 消毒产品目录
- 基于STM32的智能鞋柜控制系统设计与实现
- 【解決】家具に生えたカビの取り方、予防法、原因を紹介
- 抗菌实验不同操作方法及细节对试验结果的影响
- 多部门推动物联网创新发展 到2028年这些技术要突破
- 生活区节水节电节能管控措施.docx
- 家庭节约用电有哪些具体方法?
- 北京市出台碳普惠管理办法 市民低碳行为将能“变现”
热点动态分享
- 145108
- 52300
- 45116
- 42485
- 40924
- 30910
- 25681
- 25535
- 21916
- 18621

