利用Python进行数据分析——Pandas(2)
数据分析:Python的Pandas库数据处理 #生活知识# #编程教程#
索引对象pandas的索引对象负责管理轴标签和其他元数据(比如轴名称等)。构建Series或DataFrame时,所用到的任何数组或其他序列的标签都会被转换成一个Index:
obj=Series(range(3),index=['a','b','c']) index=obj.index print(index[:]) #output Index(['a', 'b', 'c'], dtype='object') 123456
Index对象是不可修改的(immutable),因此用户不能对其进行修改:
index[1]='d' 1
报错如下:

不可修改性非常重要,因为这样才能使Index对象在多个数据结构之间安全共享:
In [73]: index = pd.Index(np.arange(3)) In [74]: obj2 = Series([1.5, -2.5, 0], index=index) In [75]: obj2.index is index Out[75]: True 1234
除了长得像数组,Index的功能也类似一个固定大小的集合:
In [76]: frame3 Out[76]: state Nevada Ohio year 2000 NaN 1.5 2001 2.4 1.7 2002 2.9 3.6 In [77]: 'Ohio' in frame3.columns Out[77]: True In [78]: 2003 in frame3.index Out[78]: False 1234567891011
每个索引都有一些方法和属性,它们可用于设置逻辑并回答有关该索引所包含的数据的常见问题。

本节中,我将介绍操作Series和DataFrame中的数据的基本手段。
重新索引pandas对象的一个重要方法是reindex,其作用是创建一个适应新索引的新对象。
In [79]: obj = Series([4.5, 7.2, -5.3, 3.6], index=['d', 'b', 'a', 'c']) In [80]: obj Out[80]: d 4.5 b 7.2 a -5.3 c 3.6 1234567
调用该Series的reindex将会根据新索引进行重排。如果某个索引值当前不存在,就引入缺失值:
In [81]: obj2 = obj.reindex(['a', 'b', 'c', 'd', 'e']) In [82]: obj2 Out[82]: a -5.3 b 7.2 c 3.6 d 4.5 e NaN In [83]: obj.reindex(['a', 'b', 'c', 'd', 'e'], fill_value=0) Out[83]: a -5.3 b 7.2 c 3.6 d 4.5 e 0.0 123456789101112131415
对于时间序列这样的有序数据,重新索引时可能需要做一些插值处理。method选项即可达到此目的,例如,使用ffill可以实现前向值填充:
In [84]: obj3 = Series(['blue', 'purple', 'yellow'], index=[0, 2, 4]) In [85]: obj3.reindex(range(6), method='ffill') Out[85]: 0 blue 1 blue 2 purple 3 purple 4 yellow 5 yellow 123456789

使用columns关键字即可重新索引列:
In [90]: states = ['Texas', 'Utah', 'California'] In [91]: frame.reindex(columns=states) Out[91]: Texas Utah California a 1 NaN 2 c 4 NaN 5 d 7 NaN 8 1234567
也可以同时对行和列进行重新索引,而插值则只能按行应用(即轴0):
In [92]: frame.reindex(index=['a', 'b', 'c', 'd'], method='ffill', .....: columns=states) Out[92]: Texas Utah California a 1 NaN 2 b 1 NaN 2 c 4 NaN 5 1234567
利用ix的标签索引功能,重新索引任务可以变得更简洁:
In [93]: frame.ix[['a', 'b', 'c', 'd'], states] Out[93]: Texas Utah California a 1 NaN 2 b NaN NaN NaN c 4 NaN 5 d 7 NaN 8 1234567 丢弃指定轴上的项
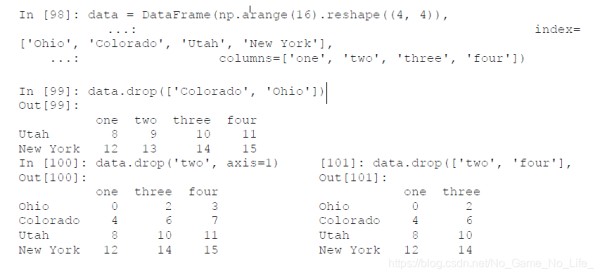
丢弃某条轴上的一个或多个项很简单,只要有一个索引数组或列表即可。由于需要执行一些数据整理和集合逻辑,所以drop方法返回的是一个在指定轴上删除了指定值的新对象:
from pandas import Series import numpy as np obj = Series(np.arange(5.), index=['a', 'b', 'c', 'd', 'e']) new_obj=obj.drop('a') print(new_obj) print(obj) 123456
对于DataFrame,可以删除任意轴上的索引值:
obj = Series(np.arange(4.), index=['a', 'b', 'c', 'd']) print(obj['b']) print(obj[1]) print(obj[2:4]) print(obj['b':'d']) #利用标签的切片运算与普通的Python切片运算不同,其末端是包含的 print(obj[['b','d']]) print(obj[[1,3]]) #output 1.0 1.0 c 2.0 d 3.0 dtype: float64 b 1.0 c 2.0 d 3.0 dtype: float64 b 1.0 d 3.0 dtype: float64 b 1.0 d 3.0 dtype: float64
1234567891011121314151617181920212223242526272829对DataFrame进行索引其实就是获取一个或多个列:

这种索引方式有几个特殊的情况。首先通过切片或布尔型数组选取行:

另一种用法是通过布尔型DataFrame(比如下面这个由标量比较运算得出的)进行索引:
In [118]: data < 5 Out[118]: one two three four Ohio True True True True Colorado True False False False Utah False False False False New York False False False False In [119]: data[data < 5] = 0 In [120]: data Out[120]: one two three four Ohio 0 0 0 0 Colorado 0 5 6 7 Utah 8 9 10 11 New York 12 13 14 15
12345678910111213141516这段代码的目的是使DataFrame在语法上更像ndarray。
算术运算和数据对齐pandas最重要的一个功能是,它可以对不同索引的对象进行算术运算。在将对象相加时,如果存在不同的索引对,则结果的索引就是该索引对的并集。我们来看一个简单的例子:
from pandas import Series s1 = Series([7.3, -2.5, 3.4, 1.5], index=['a', 'c', 'd', 'e']) s2 = Series([-2.1, 3.6, -1.5, 4, 3.1], index=['a', 'c', 'e', 'f', 'g']) print(s1+s2) #output a 5.2 c 1.1 d NaN e 0.0 f NaN g NaN dtype: float64 12345678910111213
自动的数据对齐操作在不重叠的索引处引入了NA值。缺失值会在算术运算过程中传播。对于DataFrame,对齐操作会同时发生在行和列上(不展示代码了)。
在算术方法中填充值前面的内容中,当两个Series或者DataFrame相加会在非重叠位置产生NA。使用add方法即可。
from pandas import Series s1 = Series([7.3, -2.5, 3.4, 1.5], index=['a', 'c', 'd', 'e']) s2 = Series([-2.1, 3.6, -1.5, 4, 3.1], index=['a', 'c', 'e', 'f', 'g']) print(s1+s2) print(s1.add(s2,fill_value=0)) #output a 5.2 c 1.1 d NaN e 0.0 f NaN g NaN dtype: float64 a 5.2 c 1.1 d 3.4 e 0.0 f 4.0 g 3.1 dtype: float64
123456789101112131415161718192021 DataFrame和Series之间的运算跟NumPy数组一样,DataFrame和Series之间算术运算也是有明确规定的。先来看一个具有启发性的例子,计算一个二维数组与其某行之间的差:
In [143]: arr = np.arange(12.).reshape((3, 4)) In [144]: arr Out[144]: array([[ 0., 1., 2., 3.], [ 4., 5., 6., 7.], [ 8., 9., 10., 11.]]) In [145]: arr[0] Out[145]: array([ 0., 1., 2., 3.]) In [146]: arr - arr[0] Out[146]: array([[ 0., 0., 0., 0.], [ 4., 4., 4., 4.], [ 8., 8., 8., 8.]]) 12345678910111213
这就叫做广播(broadcasting),DataFrame和Series之间的运算差不多也是如此:
from pandas import Series,DataFrame import numpy as np frame = DataFrame(np.arange(12.).reshape((4, 3)), columns=['b','c','d'],index=['Utah', 'Ohio', 'Texas', 'Oregon']) series=frame.ix[0] print(frame-series) #output b c d Utah 0.0 0.0 0.0 Ohio 3.0 3.0 3.0 Texas 6.0 6.0 6.0 Oregon 9.0 9.0 9.0 12345678910111213
如果某个索引值在DataFrame的列或Series的索引中找不到,则参与运算的两个对象就会被重新索引以形成并集:
series2 = Series(range(3), index=['b', 'c', 'f']) print(frame+series2) #output b c d f Utah 0.0 2.0 NaN NaN Ohio 3.0 5.0 NaN NaN Texas 6.0 8.0 NaN NaN Oregon 9.0 11.0 NaN NaN 123456789
如果你希望匹配行且在列上广播,则必须使用算术运算方法。
series3=frame['b'] print(frame.sub(series3,axis=0)) #output b c d Utah 0.0 1.0 2.0 Ohio 0.0 1.0 2.0 Texas 0.0 1.0 2.0 Oregon 0.0 1.0 2.0 12345678
传入的轴号就是希望匹配的轴。在本例中,我们的目的是匹配DataFrame的行索引并进行广播。
网址:利用Python进行数据分析——Pandas(2) https://www.yuejiaxmz.com/news/view/162358
相关内容
python数据分析初入python,尝试获得A股交易数据(5)——利用tushare获取A股数据并尝试存入mysql(续)
巨细!一文告诉你数据分析不得不知的秘密!
【Python】Python连接Hadoop数据中遇到的各种坑(汇总)
python excel数据分析师职业技能
大数据清洗随手记(一)
学了python究竟有什么用,实际应用场景有哪些?我整理了8个应用领域
大数据为智能家居提供智能家电管理解决方案
python如何改变日常生活
Python制作生活工具
随便看看
最新动态分享
- 哲思 | 一个家越过越好的两个迹象
- 200㎡大房子如何实现整洁无杂物,养育两个孩子的理想家园
- 收藏好书是一件“过瘾”的事——于铁军教授从书房走向更大的世界
- 200㎡大宅收拾无杂物,AI助力家庭整洁新典范
- 有娃的家可以干净整洁,杂物不乱堆吗?
- 浙江一90后夫妻放弃阳台,改成窗景色书房,那叫一个高级,真羡慕
- 书房 || 品味艺术生活
- 你住的房子,决定了你的境界
- 喜报丨城市书房市西馆荣获滨州市十佳“公共文化空间”
- 古人的书房有哪些讲究?看完也想给自己来一间,彰显品位与生活
热点动态分享
- 2788
- 2667
- 2447
- 2317
- 2174
- 1818
- 1647
- 1494
- 1369
- 1308

