【基础】语音识别技术概述与应用场景
AI语音识别技术应用于语音评测系统 #生活知识# #科技生活# #科技与教育#
目录
1. 语音识别技术概述** 2. 语音识别技术原理与算法 2.1 声学模型 2.1.1 声学特征提取 2.1.2 隐马尔可夫模型(HMM) 2.2 语言模型 2.2.1 N元语法模型 2.2.2 上下文无关语法(CFG) 2.3 识别算法 2.3.1 维特比算法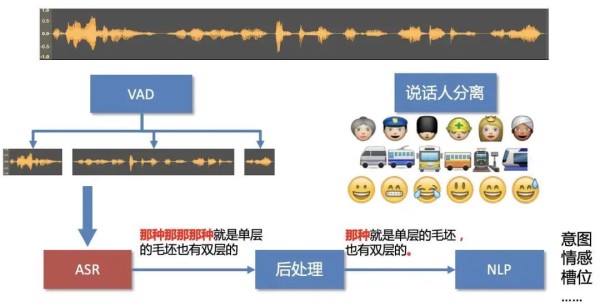
1. 语音识别技术概述**
语音识别技术是一种计算机技术,它允许计算机识别和理解人类语音。它广泛应用于各种领域,例如智能家居、客户服务和医疗保健。语音识别系统通过一系列算法和模型来识别语音,包括声学模型、语言模型和识别算法。
2. 语音识别技术原理与算法
语音识别技术是计算机识别和理解人类语音的能力。其原理和算法涉及声学模型、语言模型和识别算法三个主要方面。
2.1 声学模型
声学模型描述了语音信号与语音单元(如音素或音节)之间的关系。其主要任务是将语音信号转换为一组可供识别算法处理的特征。
2.1.1 声学特征提取声学特征提取是将语音信号转换为一组数字特征的过程,这些特征可以有效地表示语音的声学特性。常用的声学特征包括梅尔频率倒谱系数(MFCC)、线性预测系数(LPC)和共振峰(formant)。
import librosa# 加载语音文件y, sr = librosa.load('speech.wav')# 计算梅尔频率倒谱系数mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)# 打印 MFCC 特征print(mfccs)
代码逻辑分析:
librosa.load() 函数加载语音文件并返回语音信号 y 和采样率 sr。 librosa.feature.mfcc() 函数计算梅尔频率倒谱系数,其中 n_mfcc 参数指定特征的数量。 print() 函数打印计算出的 MFCC 特征。 2.1.2 隐马尔可夫模型(HMM)隐马尔可夫模型(HMM)是一种统计模型,用于表示语音信号的时序特性。HMM 假设语音信号是由一系列隐藏状态(如音素或音节)产生的,这些状态通过可观察的输出(如声学特征)进行观测。
import hmmlearn# 创建一个 3 状态的 HMM 模型model = hmmlearn.hmm.GaussianHMM(n_components=3)# 训练模型model.fit(X=mfccs)# 预测状态序列states = model.predict(X=mfccs)# 打印预测的状态序列print(states)
代码逻辑分析:
hmmlearn.hmm.GaussianHMM() 函数创建一个高斯混合隐马尔可夫模型,其中 n_components 参数指定状态的数量。 fit() 方法训练模型,使用 MFCC 特征作为训练数据。 predict() 方法预测给定特征序列的状态序列。 print() 函数打印预测的状态序列。2.2 语言模型
语言模型描述了语音序列中单词或音素的概率分布。其主要任务是约束识别算法的搜索空间,提高识别的准确性。
2.2.1 N元语法模型N元语法模型是语言模型的一种,它基于前 N 个单词或音素来预测下一个单词或音素的概率。N 元语法模型的阶数越高,其准确性越高,但计算量也越大。
import nltk# 创建一个 3 元语法模型model = nltk.ngrams(corpus, n=3)# 计算 "the" 之后的单词的概率prob = model.prob("the")# 打印概率print(prob)
代码逻辑分析:
nltk.ngrams() 函数创建一个 N 元语法模型,其中 corpus 参数是单词或音素序列,n 参数指定阶数。 prob() 方法计算给定前 N 个单词或音素后下一个单词或音素的概率。 print() 函数打印计算出的概率。 2.2.2 上下文无关语法(CFG)上下文无关语法(CFG)是一种形式语言,它使用规则来描述语言的结构。CFG 规则指定了如何从非终结符(如句子或名词短语)生成终结符(如单词)。
import nltk.grammar# 定义一个 CFG 语法grammar = nltk.grammar.CFG.fromstring("""S -> NP VPNP -> Det NVP -> V NPDet -> 'the'N -> 'dog' | 'cat'V -> 'runs' | 'jumps'""")# 解析句子parser = nltk.ChartParser(grammar)trees = parser.parse("the dog runs")# 打印解析树for tree in trees: print(tree)
代码逻辑分析:
nltk.grammar.CFG.fromstring() 函数从字符串定义一个 CFG 语法。 nltk.ChartParser() 函数创建一个解析器,用于解析给定的句子。 parse() 方法解析句子并返回解析树。 print() 函数打印解析树。2.3 识别算法
识别算法是将声学特征和语言模型结合起来,识别语音信号中单词或音素的过程。常用的识别算法包括维特比算法和前向-后向算法。
2.3.1 维特比算法维特比算法是一种
网址:【基础】语音识别技术概述与应用场景 https://www.yuejiaxmz.com/news/view/174347
相关内容
语音识别技术概述AI语音识别技术在多场景应用中的最新进展与解决方案
人工智能与语音识别:技术进步与应用前景
语音识别技术有哪些应用
深入解析:AI语音识别技术的原理、应用与发展前景详解
AI语音识别技术:涵多场景应用与用户常见问题解析
语音识别技术:在家庭智能设备中的应用
深度学习语音识别方法概述与分析
揭秘语音识别系统:技术与应用
智能语音识别技术的演变与未来应用展望
随便看看
最新动态分享
- #良品力荐# 简洁...
- 【架子】拉网展示架 器材展览架 食品置物架 五金工具架 商店零食货架 生活用品展架 金属定制款架子
- 货架产品对比
- 士力架轻巧装上市
- 士力架?新品穿新装 拥抱更轻巧更可持续的零食时代
- 【烧烤架】烧烤架尺寸及材质 烧烤架制作 烧烤架子怎么做
- 鸭架可以放多久 鸭架隔夜怎么吃
- 十大衣帽架品牌
- 士力架新品穿新装 拥抱更轻巧更可持续的零食时代
- 士力架®新品穿新装 拥抱更轻巧更可持续的零食时代
热点动态分享
- 2906
- 2865
- 2758
- 2432
- 2270
- 1874
- 1660
- 1505
- 1451
- 1320

