机器学习
学习数据挖掘和机器学习的基础 #生活技巧# #工作学习技巧# #数字技能学习#
机器学习-GDP与人名生活满意度的关系 一、本案例数据来源数据集来源(一)数据集来源(二) 二、数据下载及数据处理三、GDP与人民生活满意度的关系-模型拟合模型选择线性模型训练比较数据缺失造成的预测差异过拟合使用高阶函数模型拟合(多项式) 对比其它模型:K近邻算法 总结一、本案例数据来源
数据集来源(一)
其中oecd_bli_2015.csv为反应居民生活满意度指标的数据
数据集来源于:https://stats.oecd.org/
数据集来源(二)
gdp_per_capita国家GDP数据:https://www.imf.org/
二、数据下载及数据处理
① 导入包
import sklearn import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np import pandas as pd import sklearn.linear_model mpl.rc('axes',labelsize=14) mpl.rc('xtick',labelsize=12) mpl.rc('ytick',labelsize=12) 12345678910
② 下载数据
#下载数据 import os import urllib.request datapath = os.path.join("datasets", "lifesat", "") DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/" os.makedirs(datapath, exist_ok=True) for filename in ("oecd_bli_2015.csv", "gdp_per_capita.csv"): print("Downloading", filename) url = DOWNLOAD_ROOT + "datasets/lifesat/" + filename urllib.request.urlretrieve(url, datapath + filename) 12345678910
③ 读取数据
oecd_bli=pd.read_csv("./datasets/lifesat/oecd_bli_2015.csv",thousands=',') gdp_per_capita=pd.read_csv("./datasets/lifesat/gdp_per_capita.csv",thousands=',', delimiter='\t',encoding='latin1',na_values="n/a") 123
④ 查看数据,前五行
oecd_bli.head() 1

⑤ 查看数据基本信息
oecd_bli.info() 1

⑥ 数据筛选,选所有人,所有人对应TOT
oecd_bli = oecd_bli[oecd_bli["INEQUALITY"]=="TOT"]#将oecd_bli中为TOT的数据保留下来 1 为了正常查看数据,需要重新设置行名(index)和列名(columns)
我们将行索引设为国家名,列索引为Indicator代表各项指标
这样可以使每个国家对应几种指标
oecd_bli=oecd_bli.pivot(index='Country',columns='Indicator',values='Value') #pivot函数用来重塑数据,官方定义如下所示pivot(index=None, columns=None, values=None) # index: 可选参数。设置新dataframe的行索引,如果未指明,就用当前已存在的行索引。 #columns:必选参数。用来设置作为新dataframe的列索引。 1234
⑦ 处理gdp_per_capita数据集
gdp_per_capita.rename(columns={'2015':'GDP per capita'},inplace=True)#将列名为2015在原来表内改为GDP per capita #列重命名:df.rename(columns={‘old_name’:‘new_name’}, inplace = True) inplace=True是在原df上直接修改 #gdp_per_capita.rename(src,dst)参数 src -- 要修改的目录名,dst -- 修改后的目录名 123
⑧ 将两个表根据国家名合并,左边放oecd_bli,右边放gdp_per_capita
full_country_stats=pd.merge(left=oecd_bli,right=gdp_per_capita, left_index=True,right_index=True) 12
⑨ 将数据按照GDP per capita里的值用.sort_values从低到高排序
full_country_stats.sort_values(by='GDP per capita',inplace=True) full_country_stats.head() 12
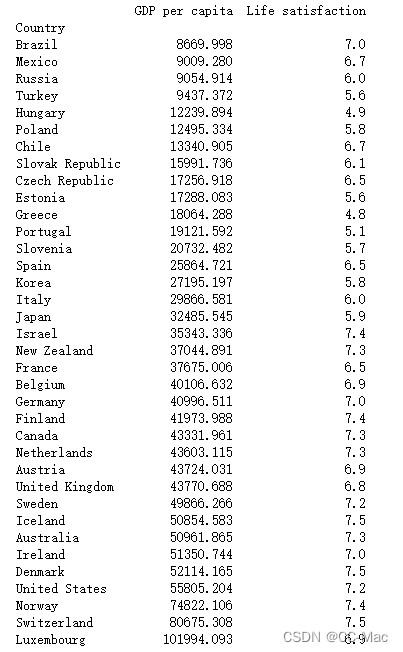
⑩ 抽取GDP per capita和Life satisfaction两列数据作为最终使用数据
country_stats=full_country_stats[['GDP per capita','Life satisfaction']] print(country_stats) 12
⑪ 画散点图
country_stats.plot(kind='scatter',x='GDP per capita',y='Life satisfaction',figsize=(9,6))#plot画图,kind代表图的类型 plt.show() 12

⑫ 保存数据
country_stats.to_csv('country_stats.csv')#.to_csv保存数据 1
最后会在根目录下找到country_stats.csv这个文件
三、GDP与人民生活满意度的关系-模型拟合
前一部分是对数据进行清洗,现在我们来拟合数据
读入处理后的数据集
full_country_stats=pd.read_csv("./country_stats.csv") full_country_stats.count() 12
删除异常值
remove_indices=[0,1,6,8,33,34,35] keep_indices=list(set(range(36)) - set(remove_indices))#将0-36中0 1 6 8 33 34 35删除 sample_data=full_country_stats[["Country","GDP per capita","Life satisfaction"]].iloc[keep_indices]#我们需要使用的数据 missing_data=full_country_stats[["Country","GDP per capita","Life satisfaction"]].iloc[remove_indices]#被删除的数据 1234
设置Country为index
sample_data.set_index("Country",inplace=True) missing_data.set_index("Country",inplace=True). 12
画图
fix,ax=plt.subplots(figsize=(9,6)) ax.scatter(sample_data['GDP per capita'],sample_data['Life satisfaction'],s=50,c='b',marker='o') ax.scatter(missing_data['GDP per capita'],missing_data['Life satisfaction'],s=50,c='r',marker='o') plt.show() 1234
查看数据集,红点为被删掉的异常值

将其置于两张图中查看
full_country_stats.plot(kind='scatter',x='GDP per capita',y='Life satisfaction',figsize=(5,3),c='b') sample_data.plot(kind='scatter',x='GDP per capita',y='Life satisfaction',figsize=(5,3),c='b') #将删除的值用红色点显示到一张图上 pos_data_x=missing_data['GDP per capita'] pos_data_y=missing_data['Life satisfaction'] plt.plot(pos_data_x,pos_data_y,"ro") plt.xlabel("GDP per capita(USD)") plt.show() 12345678
模型选择
观察删除异常值之后的数据分布,总的上为线性分布
#选取几个国家进行说明 position_text={ "Hungary":(5000,1), "Korea":(18000,1.7), "France":(29000,2.4), "Australia":(4000,3.0), "United States":(52000,3.8) } 12345678
先画出散点图
sample_data.plot(kind='scatter',x='GDP per capita',y='Life satisfaction',figsize=(9,6),c='b') plt.axis([0,60000,0,10]) #用红点对这几个国家标记 for country,pos_text in position_text.items():#从position_text遍历坐标 pos_data_x,pos_data_y=sample_data.loc[country] country="U.S."if country =="United States" else country plt.annotate(country,xy=(pos_data_x,pos_data_y),xytext=pos_text, arrowprops=dict(facecolor='black',width=0.5,shrink=0.1,headwidth=5)) plt.plot(pos_data_x,pos_data_y,"ro") plt.xlabel("GDP per capita(USD)") plt.show() 1234567891011

总体上讲,数据呈线性,我们试着随意画出一些线进行观测
#画线拟合模型示意 sample_data.plot(kind='scatter',x='GDP per capita',y='Life satisfaction',figsize=(9,7),c='b') plt.xlabel("GDP per capita(USD)") plt.axis([0,60000,0,10]) X=np.linspace(0,60000,1000)#0-60000共1000个点 plt.plot(X,2*X/100000,"r")#除以10000为了统一单位 plt.text(40000,2.7,r"$\theta_0=0$",fontsize=14,color="r")#\是只读的意思,$ $两个中间夹的表示数学符号 plt.text(40000,1.8,r"$\theta_1=2\times 10^{-5}$",fontsize=14,color="r")#斜率 plt.plot(X,8-5*X/100000,"g") plt.text(5000,9.1,r"$\theta_0=8$",fontsize=14,color="g") plt.text(5000,8.2,r"$\theta_1=-5\times 10^{-5}$",fontsize=14,color="g") plt.plot(X,4+5*X/100000,"b") plt.text(5000,3.5,r"$\theta_0=4$",fontsize=14,color="g") plt.text(5000,2.6,r"$\theta_1=5\times 10^{-5}$",fontsize=14,color="g") plt.show() 123456789101112131415
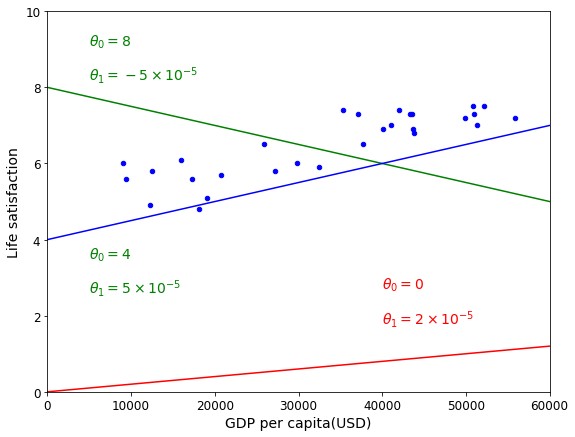
线性模型训练
**数据准备** X=np.c_[sample_data["GDP per capita"]] y=np.c_[sample_data["Life satisfaction"]] 123
选择一个线性模型
model=sklearn.linear_model.LinearRegression() model.fit(X,y) 12
训练模型
model.fit(X,y) 1
获得最优拟合直线的截距与斜率
t0 , t1 = model.intercept_[0],model.coef_[0][0] t0,t1 12
做预测,如我们输入塞浦路斯的人均GDP,预测该国幸福指数
X_new = [[22587]] print(model.predict(X_new))#幸福指数 12
画出预测点的位置
#画出散点图做基 sample_data.plot(kind='scatter',x='GDP per capita',y='Life satisfaction',figsize=(9,7),c='b') #画出最优化拟合直线y=t0+t1*x X=np.linspace(0,60000,1000) plt.plot(X,t0+t1*X,"g") #写出文字,标记t0,t1 plt.text(35000,5.1,r"$\theta_0=4.85$",fontsize=14,color="y") plt.text(35000,4.2,r"$\theta_1=4.91\times 10^{-5}$",fontsize=14,color="y") #画塞浦路斯预测点 plt.plot(X_new,model.predict(X_new),"ro") plt.xlabel('GDP per capita(USD)') plt.axis([0,60000,0,10]) plt.show() 12345678910111213

比较数据缺失造成的预测差异
如果最开始没有删除异常值我们预测到的直线会是怎么样的?我们删除异常值的操作是合理的嘛?
下面我们来对比一下:
full_country_stat是没有删除过的值的数据
在完整数据集中取两列
X_full=np.c_[full_country_stats["GDP per capita"]] y_full=np.c_[full_country_stats["Life satisfaction"]] 12
进行训练并得到最优拟合直线的截距和斜率
lin_reg_full=sklearn.linear_model.LinearRegression() lin_reg_full.fit(X_full,y_full) t0_full,t1_full=lin_reg_full.intercept_[0],lin_reg_full.coef_[0][0] 123
确实值的点
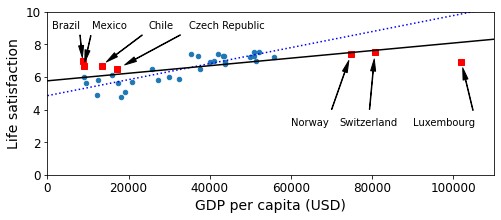
position_text2 = { "Brazil": (1000, 9.0), "Mexico": (11000, 9.0), "Chile": (25000, 9.0), "Czech Republic": (35000, 9.0), "Norway": (60000, 3), "Switzerland": (72000, 3.0), "Luxembourg": (90000, 3.0), } 123456789
画图
#画出散点图做基 sample_data.plot(kind='scatter', x="GDP per capita", y='Life satisfaction', figsize=(8,3)) #设置X轴和y轴取值范围 plt.axis([0, 110000, 0, 10]) #画出missing_data里面的点,并给出标注 for country, pos_text in position_text2.items(): pos_data_x, pos_data_y = missing_data.loc[country] plt.annotate(country, xy=(pos_data_x, pos_data_y), xytext=pos_text, arrowprops=dict(facecolor='black', width=0.5, shrink=0.1, headwidth=5)) plt.plot(pos_data_x, pos_data_y, "rs") #画出使用smaple_data拟合的直线 X=np.linspace(0, 110000, 1000) plt.plot(X, t0 + t1*X, "b:") #画出使用full_country_stats拟合的直线 lin_reg_full = sklearn.linear_model.LinearRegression() X_full = np.c_[full_country_stats["GDP per capita"]] y_full = np.c_[full_country_stats["Life satisfaction"]] lin_reg_full.fit(X_full, y_full) t0full, t1full = lin_reg_full.intercept_[0], lin_reg_full.coef_[0][0] X = np.linspace(0, 110000, 1000) plt.plot(X, t0full + t1full * X, "k") plt.xlabel("GDP per capita (USD)") plt.savefig('representative_training_data_scatterplot.jpg') plt.show() 12345678910111213141516171819202122232425262728
过拟合
使用高阶函数模型拟合(多项式)使用sklearn.preprocessing.PolynomialFeatures来进行特征构造
使用多项式的方法来进行映射产生更多的特征
PolynomialFeatures参数:
degree:多项式的量
interaction_only:默认为False,如果为True,那么就不会有特征自己和自己结合的项,如x2,x3等
include_bias:默认为True
pipeline.Pipeline详解
full_country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction', figsize=(8,3)) plt.axis([0, 110000, 0, 10]) from sklearn import preprocessing from sklearn import pipeline poly = preprocessing.PolynomialFeatures(degree=30, include_bias=False) scaler = preprocessing.StandardScaler() lin_reg2 = sklearn.linear_model.LinearRegression() #下面一行:流水线----先多项式---->标准化---->线性回归 pipeline_reg = pipeline.Pipeline([('poly', poly), ('scal', scaler), ('lin', lin_reg2)]) pipeline_reg.fit(X_full, y_full) curve = pipeline_reg.predict(X[:, np.newaxis]) plt.plot(X, curve) plt.xlabel("GDP per capita (USD)") #plt.savefig('overfitting_model_plot') plt.show() 123456789101112131415161718

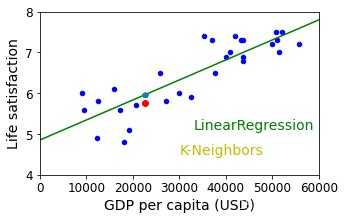
对比其它模型:K近邻算法
不同的模型会产生不同的预测
import sklearn.neighbors model_K = sklearn.neighbors.KNeighborsRegressor(n_neighbors=3) #加载数据 X=np.c_[sample_data["GDP per capita"]] y=np.c_[sample_data["Life satisfaction"]] #模型训练 # sklearn.neighbors.KNeighborsRegressor(n_neighbors=3).fit(X,y) model_K.fit(X,y) X_new_k=np.array([[22587.0]]) print(model_K.predict(X_new_k)) #画出散点图做基 sample_data.plot(kind='scatter',x='GDP per capita',y='Life satisfaction',figsize=(5,3),c='b') #画出最优化拟合直线y=t0+t1*x X=np.linspace(0,60000,1000) plt.plot(X,t0+t1*X,"g") #写出文字,标记t0,t1 plt.text(33000,5.1,"LinearRegression",fontsize=14,color="g") plt.text(30000,4.5,"K-Neighbors",fontsize=14,color="y") #画塞浦路斯预测点 plt.plot(X_new,model.predict(X_new),"p") plt.plot(X_new,model_K.predict(X_new_k),"ro") plt.xlabel("GDP per capita (USD)") plt.axis([0,60000,4,8]) plt.show() 12345678910111213141516171819202122232425
总结
期待大家和我交流,留言或者私信,一起学习,一起进步!
网址:机器学习 https://www.yuejiaxmz.com/news/view/202812
相关内容
机器学习day01——笔记博弈论+机器学习=?
机器学习(七):提升(boosting)方法
一文读懂!人工智能、机器学习、深度学习的区别与联系!
机器学习之数据预处理(Python 实现)
一文看懂机器学习「3 种学习方法 + 7 个实操步骤 + 15 种常见算法」
基于机器学习的服装搭配问题分析
机器学习降维:删除低方差特征与相关系数
语音识别与语音助手:机器学习的生活实践
五大学习利器!打造高效学习生活的好帮手
随便看看
最新动态分享
- 堪培拉大学动画专业留学生活
- 伦敦时装学院纯艺术专业留学生活
- 威斯敏斯特大学服装设计专业留学生活
- 提赛德大学影视制作专业留学生活
- 提供在线答疑功能,区域版教育局网上阅卷系统,方便教师与学生沟通
- phone2qq:基于TEA加密的手机号
- 五一漫画教育主题
- 十五分钟生活圈规划方案
- 贵州2026年学历提升申报的报名条件和要求有哪些?
- 地产数字化营销方案
热点动态分享
- 136568
- 39375
- 36313
- 23792
- 23622
- 23175
- 21418
- 15408
- 14972
- 14938

