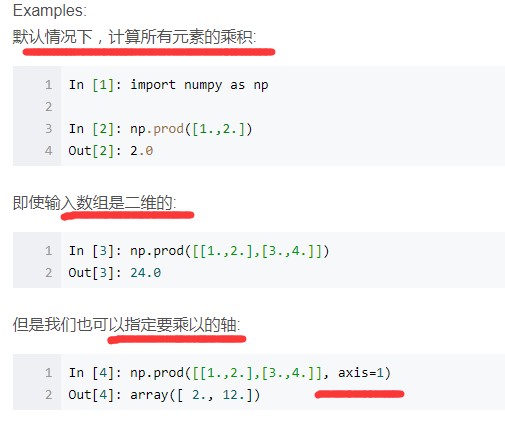
np.prod() 函数计算数组元素乘积等
使用Excel计算平均值,选择数据后点击'公式'选项卡的'平均'函数 #生活知识# #生活经验# #软件#
np.prod()函数用来计算所有元素的乘积,对于有多个维度的数组可以指定轴,如axis=1指定计算每一行的乘积。
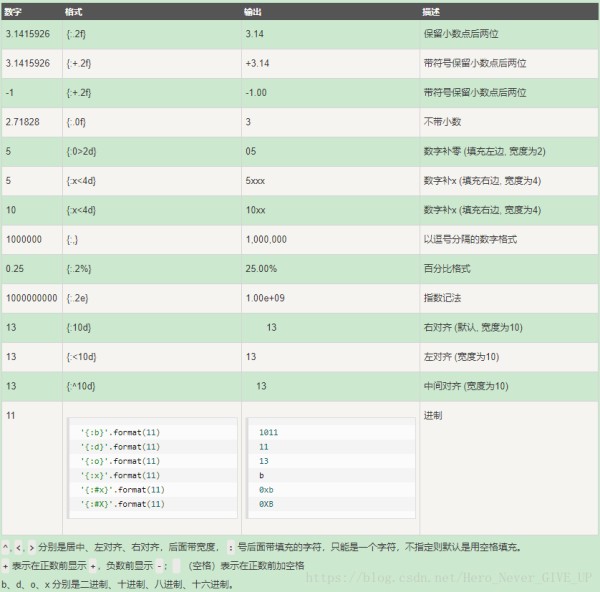
Python format 格式化函数:
例1:
>>>"{} {}".format("hello", "world")
'hello world'
>>> "{0} {1}".format("hello", "world")
'hello world'
>>> "{1} {0} {1}".format("hello", "world")
'world hello world'
例2:
print("网站名:{name}, 地址 {url}".format(name="菜鸟教程", url="www.runoob.com"))
site = {"name": "菜鸟教程", "url": "www.runoob.com"}
print("网站名:{name}, 地址 {url}".format(**site))
my_list = ['菜鸟教程', 'www.runoob.com']
print("网站名:{0[0]}, 地址 {0[1]}".format(my_list))
python进阶发现的资源,后续有实际应用另行更新:
https://github.com/eastlakeside/interpy-zh/blob/master/collections/collections.md 这是GitHub上的项目,这个链接主要讲python “collection” 容器的。 Google搜索“python进阶”。后续有实际应用的时候再补上。 https://eastlakeside.gitbooks.io/interpy-zh/content/decorators/everything_is_object.html 这也是有关python进阶的,“一切皆对象”、生成器,迭代器等;KNN 分类器的K值选取:K值不能过大,也不能过小,K值的选取取决于学习难度与训练样本的规模,通常,K取3~10。一种常见的做法就是设置K等于训练样本数的“平方根”。更好的一种方法是“交叉验证”:设置多个测试样本集,用这些样本集来测试多个K值,根据分类性能选择最合适的K值。
从知乎上看到的数据清洗方面的知识:
数据挖掘中常用的数据清洗方法有哪些?
https://www.zhihu.com/question/22077960
python排序,保留索引值
: 比如对a = [3,4,1,7,2]用a.sort()排序得到a = [1,2,3,4,7],请问如何得到排序后的
: 数组元素的索引系列,是说,在原来数组中的索引。在这个例子里应该是[2,4,0,1,3].
In [1]: a = [3,4,1,7,2]
In [2]: enumerate(a)
Out[2]: <enumerate object at 0x8591f0c>
In [3]: list(enumerate(a))
Out[3]: [(0, 3), (1, 4), (2, 1), (3, 7), (4, 2)]
In [4]: from operator import itemgetter
In [5]: sorted(enumerate(a), key=itemgetter(1))
Out[5]: [(2, 1), (4, 2), (0, 3), (1, 4), (3, 7)]
In [6]: [index for index, value in sorted(enumerate(a), key=itemgetter(1))]
Out[6]: [2, 4, 0, 1, 3]
大杀器:
In [7]: import numpy as np
In [8]: np.argsort([3,4,1,7,2])
Out[8]: array([2, 4, 0, 1, 3])
注意的是,对于 [(索引,值),...,(索引,值)]这种形式的情况我以为对任意的索引值都可以用,但其实不是,例如:
a=[(12,4),(100,3),(1000,1),(9832,2)]
from operator import itemgetter
[index for index,value in sorted(enumerate(a),key=itemgetter(1))]
Output[1]:[0, 1, 2, 3]
Input:a=sorted(a,key=itemgetter(1))
a
Output:[(1000, 1), (9832, 2), (100, 3), (12, 4)]
Input:
indx=[]
a=a[:len(a)/2]
for i in a:
indx.append(i[0])
Output:
indx
[1000, 9832]
其他关于python排序的高级技巧请自行搜索
python面向对象:
现在面向对象的思维用的很多,大到实际生活工作中的问题或小/具体到编程问题,你要时时注意到你讨论的问题的对象是什么,是对什么讨论的这个问题。比如今天下午讨论的图像聚类和图像划分,一个面向的对象是一张张图片,目的是把相似的图片进行聚类;另一个问题的对象是图片中的一个个像素点的值,目的是对一张图片的不同区域进行划分。问题的对象就不一样,要是一下子就能意识到问题的对象变了,就可以流畅的在不同的问题场景中转换。
好了,扯远了,,回来回来,说到python面向对象我本意是想说python面向对象中的类,类中属性是可以直接通过类名进行访问的,而类的方法如果没有加“@classmethod”这样的装饰器的话需要先把类实例化一个具体的类的实例对象,即要通过一个类的实体才能去调用这个方法;对于有些方法不需要传入参数的,可以用装饰器“@property” 把这个方法装饰成类的一个属性,这样就可以通过类名直接调用了,而且不用加方法的“()”,就像调用类的一般属性的方式那样调用就行了。
好,这部分今天就说到这里~
python & tensorflow 设置学习率:先设置一个learning_rate 实例,再传入优化器Optimizer()中。
import tensorflow as tf
from numpy.random import RandomState
if __name__ == "__main__":
batch_size = 8
x = tf.placeholder(tf.float32,shape=(None,1),name="x_input")
y_ = tf.placeholder(tf.float32,shape=(None,1),name="y_output")
w = tf.Variable(50.,trainable=True)
y = x * w
loss = tf.reduce_sum(tf.square(y-y_))
global_step = tf.Variable(0,trainable=False)
learing_rate = tf.train.exponential_decay(0.1,global_step,100,0.96,staircase=False)
learing_step = tf.train.GradientDescentOptimizer(learing_rate).minimize(loss,global_step)
rdm = RandomState(1)
dataset_size = 200
X = rdm.rand(dataset_size,1)
Y = [x1 + rdm.rand()/5.0 - 0.05 for x1 in X]
with tf.Session() as sess:
all_init = tf.initialize_all_variables()
sess.run(all_init)
STEPS = 5000
for i in range(STEPS):
start = (i * batch_size) % batch_size
end = min(start+batch_size,dataset_size)
sess.run(fetches=learing_step,feed_dict={x:X[start:end],y_:Y[start:end]})
if i % 100 == 0:
print("w:%f,learing_rate:%f"%(w.eval(session=sess),learing_rate.eval(session=sess)))
深度学习中的“batch_size”参数:
如果数据集比较小,则可以采用全数据集(即‘Full Batch Learing’),但是对于更大的数据集并不适用。相对于Full Batch Learning的另一个极端就是一个batch只有一个数据,叫“在线学习(Online Learning)”, 线性神经元在均方误差代价函数的错误面是一个抛物面,横截面是椭圆。对于多层神经元、非线性网络,在局部依然是近似抛物面。使用在线学习(online learning)每次修正的方向以各自样本的梯度方向修正,横冲直撞,难以达到收敛。

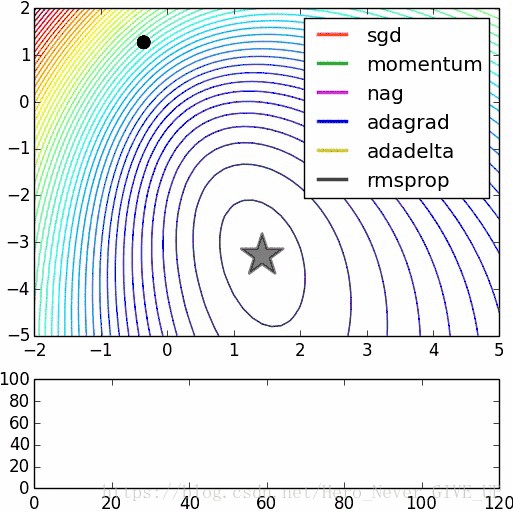
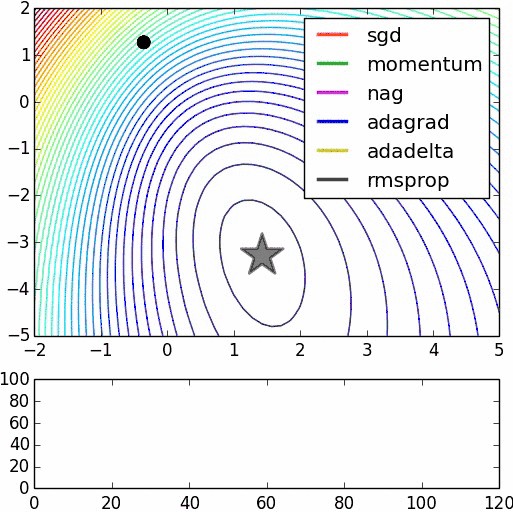 不同随机优化器的比较:
不同随机优化器的比较:
网址:np.prod() 函数计算数组元素乘积等 https://www.yuejiaxmz.com/news/view/276266
相关内容
c语言计算大数阶乘Matlab数据分析与多项式计算
整数乘除法计算法则是什么?(可不是因数*因数=积......哦~? 爱问知识人
(Python)组合数据:Python中的列表、元组、集合
三角函数反三角函数乘 [cos(arcsinx)]^2=1
效率工具:数据分析中常见的Excel函数都在这里了
【数据分析】15组Excel函数,解决数据分析中80%的难题!
Python函数
javascript数组的方法
高三数学一轮复习精品课件2:函数y=Asin(ωx+φ)的图象及三角函数模型的应用.ppt
随便看看
最新动态分享
- 广州增城周边工厂机械设备回收厂家
- 厨房台面置物,有什么好物推荐
- 灶台旁边放什么最旺财
- 灶台边不能放的5样物品,好多人都乱放,看完叮嘱家人,尽早拿走
- 家装灶台下也能储物,这些收纳方法学起来
- 灶台最旺风水摆放什么东西
- 灶台边放什么最旺财
- 如果你家也是小厨房,尽量备上这3样好物,幸福感立马提升
- 无论厨房大小,建议每个家庭:灶台定放上这“妙物”,家家适用
- 灶台旁边别乱放!这6种东西暗藏危险,很多家庭一直都在犯错!
热点动态分享
- 2714
- 2611
- 2256
- 2254
- 2144
- 1759
- 1638
- 1489
- 1319
- 1300

