简易语音助手—python
Python是初学者常用的编程语言,语法简洁易懂。 #生活知识# #科技生活# #编程学习#
简易语音助手—python 需求拆分API调用一、语音转文字——百度AI开放平台用FFmpeg转换音频格式 二、聊天接口——图灵机器人三、文字转语音——讯飞开放平台pyaudio录音及播放 模块整合完整项目代码需求拆分
语音助手首先要能得到人的说话的音频,然后根据内容进行回复,再将回复播放出来。这个过程也就是语音转文字,获得回复文字,再将回复转语音。看起来是一个复杂的过程,但是好在这三个过程都有对应的API接口可以用到。
API调用
一、语音转文字——百度AI开放平台
官方文档:http://ai.baidu.com/docs#/ASR-API/top
调用这个接口,我们只需要上传音频文件,就会返回对应的文字。百度服务端会将非pcm格式,转为pcm格式,因此使用wav、amr、m4a会有额外的转换耗时。建议在本地转换,pcm是无压缩的二进制音频文件,因此我们利用FFmpeg将wav转换为pcm。
下载链接:https://github.com/BtbN/FFmpeg-Builds/releases
下载完成后将ffmpeg.exe复制到main.py目录中,或在代码里写出完整路径即可调用。
演示代码
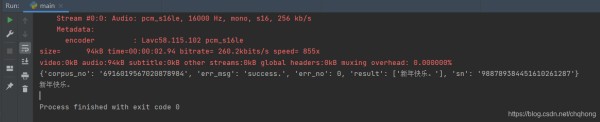
#用ffmpeg将wav转换为pcm格式,并调用接口获得文字。 # -*- coding:utf-8 -*- from ffmpy3 import FFmpeg import os from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = 'xxxxxxxx' API_KEY = 'xxxxxxxxx' SECRET_KEY = 'xxxxxxxxx' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) def get_file_content(filePath): with open(filePath, 'rb') as fp: #读取文件 return fp.read() #语音转文字接口调用 def speechTOstr(): path = '1.pcm' # 文件路径 if os.path.exists(path): # 如果存在1.pcm则删除,此为上一次生成的 os.remove(path) else: print('no such file:%s') # 则返回文件不存在 ff = FFmpeg(executable='C:\\Users\\86158\\Downloads\\ffmpeg-N-100493-gc720286ee3-win64-lgpl-vulkan\\bin\\ffmpeg.exe',inputs={r'1.wav':"-y"}, outputs={r'1.pcm':"-f s16le -ar 16000 -ac 1 -acodec pcm_s16le"}) #音频格式转换ffmpeg.exe用的绝对路径 print(ff.cmd) #输出本地运行的ffmpeg完整命令 ff.run() json=client.asr(get_file_content('1.pcm'), 'pcm', 16000, { 'dev_pid': 1537, }) #调用接口返回json格式 print(json) #输出完整json返回 speechStr=json['result'][0] #提取出文字结果 print(speechStr) return speechStr speechTOstr()
123456789101112131415161718192021222324252627282930313233343536运行结果
二、聊天接口——图灵机器人
这里我用到的是天行数据做中介,一元一万天豆,调用一次接口20天豆。
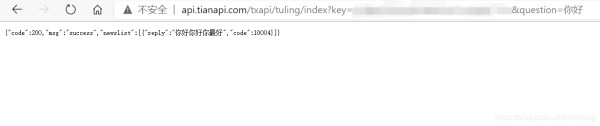
调用也很简单,只有两个参数,申请之后可以得到的key,和你想说的question。
官方链接:https://www.tianapi.com/
演示代码
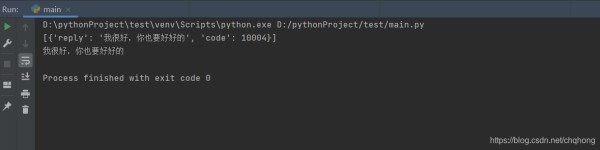
# -*- coding:utf-8 -*- from urllib.request import urlopen,Request from urllib.error import URLError import json from urllib.parse import urlencode #图灵机器人接口参数 class TuringChatMode(object): def __init__(self): # API接口地址 self.turing_url = 'http://api.tianapi.com/txapi/tuling/index?' def get_turing_text(self,text): turing_url_data = dict( key='xxxxxxxxxxx', question=text, ) self.request = Request(self.turing_url + urlencode(turing_url_data)) try: w_data = urlopen(self.request) except URLError: raise IndexError("No internet connection available to transfer txt data") # 如果发生网络错误,断言提示没有可用的网络连接来传输文本信息 except: raise KeyError("Server wouldn't respond (invalid key or quota has been maxed out)") # 其他情况断言提示服务相应次数已经达到上限 response_text = w_data.read().decode('utf-8') json_result = json.loads(response_text) return json_result['newslist'] turing = TuringChatMode() reply=turing.get_turing_text("你好") print(reply) #输出完整json print(reply[0]['reply']) #提取出回复文字
123456789101112131415161718192021222324252627282930313233运行结果
三、文字转语音——讯飞开放平台
官方文档:https://www.xfyun.cn/doc/tts/online_tts/API.html
讯飞文字转语音的音源比较多,但是接口调用稍微有点复杂。

好在官方有示例代码,这个代码会报一个错误但是能正常使用,个人不是很懂websocket,所以就没管了。
代码下载链接:https://xfyun-doc.cn-bj.ufileos.com/1602142890241307/tts_ws_python3_demo.zip
最终得到的还是一个pcm文件,所以还得用FFmpeg转换成wav格式播放,至此接口以及都准备好了,剩下的问题就是如何录音和播放了,需要用到pyaudio。
# -*- coding:utf-8 -*- from ffmpy3 import FFmpeg import pyaudio import wave import os #录制用户音频 def get_audio(): filepath = "1.wav" CHUNK = 256 FORMAT = pyaudio.paInt16 CHANNELS = 1 # 声道数 RATE = 16000 # 采样率 RECORD_SECONDS =3 WAVE_OUTPUT_FILENAME = filepath p = pyaudio.PyAudio() stream = p.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, frames_per_buffer=CHUNK) print("*"*10, "开始录音:请在3秒内输入语音") frames = [] for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)): data = stream.read(CHUNK) frames.append(data) print("*"*10, "录音结束\n") stream.stop_stream() stream.close() p.terminate() wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb') wf.setnchannels(CHANNELS) wf.setsampwidth(p.get_sample_size(FORMAT)) wf.setframerate(RATE) wf.writeframes(b''.join(frames)) wf.close() #播放讯飞文字转语音音频 pcm格式 def play(): path = 'reply.wav' # 文件路径 if os.path.exists(path): # 如果文件存在 # 删除文件,可使用以下两种方法。 os.remove(path) # os.unlink(path) else: print('no such file:%s') # 则返回文件不存在 ff = FFmpeg( executable='C:\\Users\\86158\\Downloads\\ffmpeg-N-100493-gc720286ee3-win64-lgpl-vulkan\\bin\\ffmpeg.exe', inputs={r'1.pcm': "-f s16le -ar 16000 -ac 1"}, outputs={r'reply.wav': ""}) #pcm转wav print(ff.cmd) ff.run() wf = wave.open("reply.wav", 'rb') p = pyaudio.PyAudio() stream = p.open(format=p.get_format_from_width(wf.getsampwidth()), channels=wf.getnchannels(), rate=wf.getframerate(), output=True) data = wf.readframes(1024) while data != b'': stream.write(data) data = wf.readframes(1024) stream.stop_stream() stream.close() p.terminate() get_audio() play()
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667模块整合
将录音模块、语音转文字、图灵机器人、文字转语音、播放音频模块整合起来,就得到了一个简单的语音助手。不过和语音助手比还有很明显的缺陷,第一点是没有唤醒词,第二点是录音的时长固定。
对于唤醒词初步想法是识别语音转文字的结果是否含有关键词,而时长固定的问题准备用FFmpeg合成录音来解决,如果新音频的分贝过小时则停下录音,如果有声音则继续合成。
还有一点,所有的接口并非免费,但是除了第二个,其他的白嫖做测试是没有问题的。
完整项目代码
git链接:https://github.com/cqhong/SpeechRecognition
网址:简易语音助手—python https://www.yuejiaxmz.com/news/view/297742
相关内容
小白如何做一个Python人工智能语音助手Python实现简单的智能助手
语音命令识别与语音助手
语音识别与语音助手:机器学习的生活实践
语音识别与语音助手:技术与实现
Python虚拟助手与自然语言理解
Python实现语音识别
构建智能语音助手应用:语音识别和语音合成的实践
百度语音识别 python
Python实现语音识别:百度baidu
随便看看
最新动态分享
- 有哪些可以明显提高生活品质的APP?
- 中医养生保护眼健康提高生活质量.pptx
- 节约能源,净化环境,低碳生活,提高生活质量。下面是“中国节能产品认证标志”,请用简洁的语言说说其设计理念。
- 好智生活软件下载
- 夏天衣物有异味怎么办?5大科学除味技巧+清洁保养全攻略
- 如何去除衣物上的顽固异味?5大科学除臭技巧+日常保养指南
- 【努比亚Z60参数】努比亚 Z60手机参数
- 抗疲劳防静电桌面 无臭味防静电桌面
- 迷你创意桌面垃圾桶 厨房办公桌家用无盖垃圾桶 杂物收纳清洁桶
- 革新屏幕清洁方案——聚力外抗静电剂引领科技生活新风尚
热点动态分享
- 126333
- 36017
- 34435
- 23393
- 22828
- 21118
- 19580
- 14610
- 14581
- 14480

