[推荐系统]基于个性化推荐系统研究与实现(2)
个性化推荐算法:基于阅读历史和兴趣的推荐系统 #生活乐趣# #阅读乐趣# #电子书推荐#
目 录
四、电影推荐系统编程与实现
4.1 目标描述
4.2 实现思路
4.3 构建用户的偏好信息
4.4 计算用户与每部电影的距离
4.5 数据准备
4.6 模型训练与电影推荐
4.7 效果评估
五、结果与展望
[推荐系统]基于个性化推荐系统研究与实现(1)
四、电影推荐系统编程与实现
借助电影数据库,使用Python Anaconda编写电影推荐系统程序。
4.1 目标描述
利用基于内容的推荐算法编写电影推荐系统,当用户在浏览某部电影时,为其推荐所浏览电影的相似电影。
4.2 实现思路
首先使用训练数据得到用户的偏好信息矩阵和物品Item的特征信息矩阵,然后计算用户对未进行评分电影的偏好分,选取前K个电影推荐给用户。如图1为电影的特征信息矩阵Ia:电影数据集有18种类型,该部电影属于某种类型为1,不属于为0.如toy story(玩具总动员)电影:animation(动漫),children’s(儿童剧), comedy(喜剧)

图1 电影的特征信息矩阵Ia
表4 item_profile.json格式
"1": [0, 0, 0, 0, 1,1, 0, 0, 0, 0,0, 0, 0, 0, 0,0, 1, 0], /18种电影类型一维特征矩阵
"2": [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0],
"3": [0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
4.3 构建用户的偏好信息
构造用户对18类电影的偏好矩阵Ua.举例:张三对电影的评分偏好矩阵为例,产生如下图偏好矩阵JSON文件。
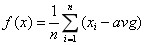
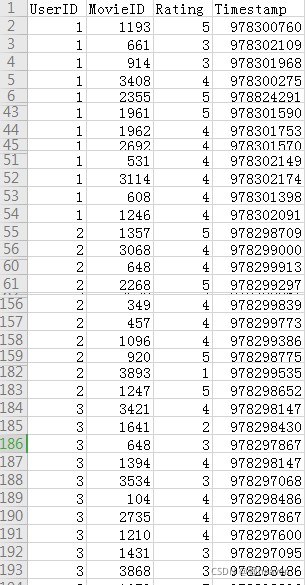
"1": [0.01132075471698073, 0.8113207547169807, -0.045822102425876414, 0.0, -0.18867924528301927, 0.06132075471698073, 0.2398921832884093, 0.09703504043126644, -0.07756813417190817, 0.0, 0.0, 0.0, 0.0, 0.14465408805031407, -0.18867924528301927, -0.5220125786163526, -0.5220125786163526, -0.18867924528301927],
"2": [-0.21317829457364298, 0.020155038759689988, -0.15317829457364332, 0.28682170542635665, 0.02366381068951455, 0.0, 0.18555588264154677, 0.0, 0.0, 0.62015503875969, -0.37984496124031003, -0.7131782945736433, 0.0, -0.12494300045599628, -0.7131782945736433, -0.004844961240310012, -0.22930732683170776, -0.12984496124031],
"3": [0.05456095481670939, 0.0980392156862746, -0.13529411764705898, 0.0, 0.09803921568627459, 0.0980392156862746, 0.0980392156862746, 0.0980392156862746, 0.0980392156862746, 0.7647058823529412, -0.9019607843137254, -1.2352941176470587, 0.0, -0.06862745098039207, 0.5980392156862746, -0.10196078431372539, -0.10196078431372539, 0.0],
"4": [-0.032581453634085426, -0.8571428571428573, 0.0, 0.0, -0.3571428571428574, -0.1904761904761907, -0.02380952380952402, 0.0, 0.0, 0.3095238095238093, 0.0, 0.14285714285714265, 0.0, -0.6349206349206351, 0.3095238095238093, -0.1904761904761907, -0.6904761904761907, 0.8095238095238093]
4.4 计算用户与每部电影的距离
本文采用余弦相似度计算用户与每部电影的距离。将dat文件转换为csv文件,生成电影特征矩阵JSON文件和用户特征矩阵JSON文件。
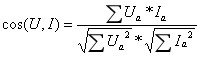
Ua:用户对电影类型a的偏好程度;
Ia:电影是否属于类型a,即“构建电影的特征信息矩阵”中对应类型a的特征信息矩阵。
def cosUI(self,user,item):
Uia=sum(
np.array(self.user_profile[str(user)])
*
np.array(self.item_profile[str(item)])
)
Ua=math.sqrt( sum( [ math.pow(one,2) for one in self.user_profile[str(user)]] ) )
Ia=math.sqrt( sum( [ math.pow(one,2) for one in self.item_profile[str(item)]] ) )
return Uia / (Ua * Ia)
4.5 数据准备
步骤1:数据格式转换,生成Users.csv,ratings.csv,movies.csv文件
步骤2:构建电影的特征信息矩阵,生成item_profile.json文件
步骤3:构建用户的偏好信息矩阵,生成user_profile.json文件
4.6 模型训练与电影推荐
因为是无监督的学习,并不需要去训练。分如下分5步完成。
步骤1:加载预处理的数据
def __init__(self,K):
# 给用户推荐的item个数
self.K = K
self.item_profile=json.load(open("data/item_profile.json","r"))
self.user_profile=json.load(open("data/user_profile.json","r"))
步骤2:获取用户未进行评分的item列表
def get_none_score_item(self,user):
items=pd.read_csv("data/movies.csv")["MovieID"].values
data = pd.read_csv("data/ratings.csv")
have_score_items=data[data["UserID"]==user]["MovieID"].values
none_score_items=set(items)-set(have_score_items)
return none_score_items
步骤3:获取用户对item的喜好程度
def cosUI(self,user,item):
Uia=sum(
np.array(self.user_profile[str(user)])*np.array(self.item_profile[str(item)])
)
Ua=math.sqrt( sum( [ math.pow(one,2) for one in self.user_profile[str(user)]] ) )
Ia=math.sqrt( sum( [ math.pow(one,2) for one in self.item_profile[str(item)]] ) )
return Uia / (Ua * Ia)
步骤4:为用户进行电影推荐
def recommend(self,user):
user_result={}
item_list=self.get_none_score_item(user)
for item in item_list:
user_result[item]=self.cosUI(user,item)
if self.K is None:
result = sorted(
user_result.items(), key= lambda k:k[1], reverse=True
)
else:
result = sorted(
user_result.items(), key= lambda k:k[1], reverse=True
)[:self.K]
print(result)
if __name__=="__main__":
cb=CBRecommend(K=10)
cb.recommend(1)
步骤5:输出结果
(1)为编号为1的用户电影推荐(cb.recommend(1)):
[(210, 0.6832725491451497), (383, 0.6832725491451497), (416, 0.6832725491451497), (553, 0.6832725491451497), (599, 0.6832725491451497), (714, 0.6832725491451497), (964, 0.6832725491451497), (967, 0.6832725491451497), (1008, 0.6832725491451497), (1209, 0.6832725491451497)]
(2)为编号为2的用户电影推荐(cb.recommend(2)):
[(682, 0.47567658605409524), (1050, 0.47567658605409524), (1149, 0.47567658605409524), (2627, 0.47567658605409524), (37, 0.45997147302634817), (77, 0.45997147302634817), (99, 0.45997147302634817), (108, 0.45997147302634817), (116, 0.45997147302634817), (128, 0.45997147302634817)]
4.7 效果评估
随机选取20个用户进行算法评估。
# 推荐系统效果评估
def evaluate(self):
evas=[]
data = pd.read_csv("data/ratings.csv")
# 随机选取20个用户进行效果评估
for user in random.sample([one for one in range(1,6040)], 20):
have_score_items=data[data["UserID"] == user]["MovieID"].values
items=pd.read_csv("data/movies.csv")["MovieID"].values
user_result={}
for item in items:
user_result[item]=self.cosUI(user,item)
results = sorted(
user_result.items(), key=lambda k: k[1], reverse=True
)[:len(have_score_items)]
rec_items=[]
for one in results:
rec_items.append(one[0])
eva = len(set(rec_items) & set(have_score_items)) / len(have_score_items)
evas.append( eva )
return sum(evas) / len(evas)
输出结果:
用户1:0.049802830254472616
用户2:0.052045136809590845
五、结果与展望
由程序运行结果看,推荐系统的准确率是非常低,这与原始数据、数据的预处理和选取的用户都有很大关系,本程序不最求算法的准确率,重点在于过程实现。除了基于用户行为特征(内容)推荐算法的电影推荐系统外,还有基于近邻的推荐算法(协同过滤算法,Collaborative Filtering),分为基于用户的协同过滤(User-CF-Based)算法和基于物品的协同过滤(Item-CF-Based)算法和基于隐语义模型(LFM,机器学习算法)的推荐算法,这三种算法统称为基于用户行为特征的推荐。
User-CF-Based算法,基于被推荐用户的相似用户喜好,为被推荐用户推荐电影,简单说就是给用于推荐“和他兴趣相投的其他用户”喜欢的物品;Item-CF-Based算法,根据当用户浏览电影时,向用户推荐和该部电影相似的电影,简单说就是给用户推荐他之前喜欢物品的相似物品。所以,当用户数量远多于物品数量时,可以考虑使用ItemCF;当物品数量远超于用户数量时可以考虑使用UserCF。
基于内容(CB)的推荐算法和基于物品(IB)的协同推荐算法十分相似,两种算法都是基于Item的基础进行相似度计算。但是两者基于的Item特征不一样:
基于内容的推荐算法中,计算用户相似度用的是Item本事的特征;基于物品的协同过滤算法中,则用“用户对Item的行为”来构造Item的特征。基于隐语义模型(LFM)的推荐算法思想是,找到用户的偏好特征,将该类偏好特征对应的Item推荐给用户。网址:[推荐系统]基于个性化推荐系统研究与实现(2) https://www.yuejiaxmz.com/news/view/335674
相关内容
Python推荐系统实战:构建个性化推荐系统基于Java的个性化推荐系统:UserCF与ItemCF算法实现
推荐系统与个性化服务
基于大数据的个性化推荐系统
推荐系统:个性化推荐的算法与实践
推荐系统详解——个性化推荐与非个性化推荐
个性化推荐系统,必须关注的五大研究热点
推荐系统的新趋势:个性化推荐与多样性平衡
个性化推荐系统中协同过滤方法的研究
个性化推荐系统通用12篇
随便看看
最新动态分享
- 【空调过滤器清洗】怎样清洗空调过滤网 空调过滤器的清洗方法
- 空调的滤网怎么清洗(分享空调滤网怎么拿出来)
- 空调过滤器怎么拆洗,轻松拆洗空调过滤器,让你清凉一夏!
- 谁知道家用空调滤网如何清洗?简单操作易懂的。
- 空调滤芯该如何清洗
- 空调过滤网要怎么清洗?
- 空调滤网清洗小妙招
- 如何拆洗空调过滤网
- 如何清洗空调过滤网丨无锡中央空调
- 华凌空调滤网深度清洁教程,轻松拆卸与清洗,享受清新空气体验
热点动态分享
- 2798
- 2674
- 2492
- 2329
- 2186
- 1824
- 1649
- 1495
- 1379
- 1309

