李宏毅机器学习(六) 神经网络训练技巧(2)
了解机器学习基础,如逻辑回归和神经网络 #生活技巧# #工作学习技巧# #数字技能学习#
神经网络训练技巧(2)#
Loss不降的原因#
问题#
Q:为什么Loss降到一定程度后不再下降,是因为参数到了critical point 或者 saddle point吗?
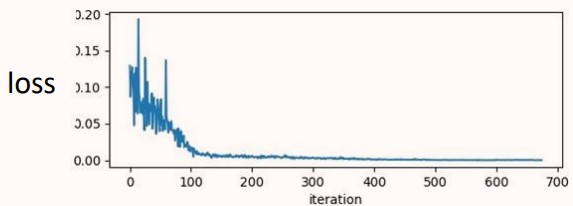
A:不一定是参数参数到了critical point 或者 saddle point,也有可能是梯度发生了震荡。
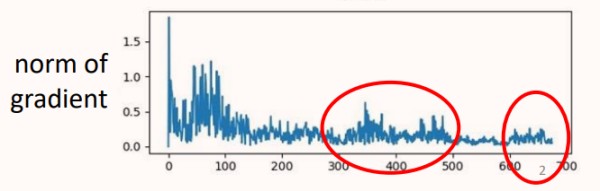
如图所示,300-500轮时,Loss基本无变化,但是梯度会有陡增陡降的情况,这可能是梯度发生了震荡。
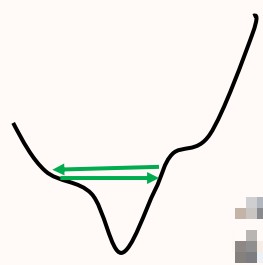
如图所示,参数在error surface上发生了震荡现象,梯度激烈变化,但是loss居高不下,始终无法走到更低的地方。
就算没有遇到critical point,训练也不容易。
实例#
例如下面这个问题,有两个参数 w" role="presentation">w 和 b" role="presentation">b ,w" role="presentation">w 对应的梯度相对陡峭一点, b" role="presentation">b 对应的梯度相对平坦一点,loss最小的地方在黄色X处,直观感受很容易训练,让我们试一试。

将学习率设为10−2" role="presentation">10−2进行训练,收敛过程如下图所示。

发生了震荡现象,Loss无法收敛,直观感受是学习率设置的太大了,那我们设置小一点试试。
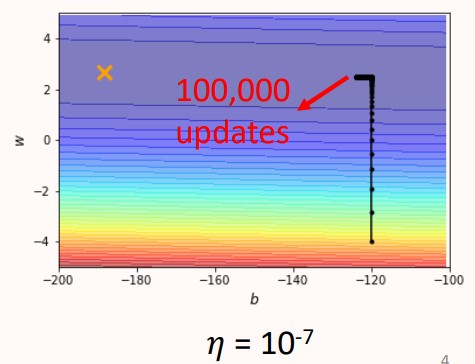
学习率降低为10−7" role="presentation">10−7时,终于不在产生震荡现象,但在经过100000次训练后,前进的距离很小,太小的复杂度导致很难训练。10−7" role="presentation">10−7的学习率适合 w" role="presentation">w ,但不适合 b" role="presentation">b。
分析#
单一的学习率不能应对所有的参数训练,应该对每个参数定制对应的学习率。
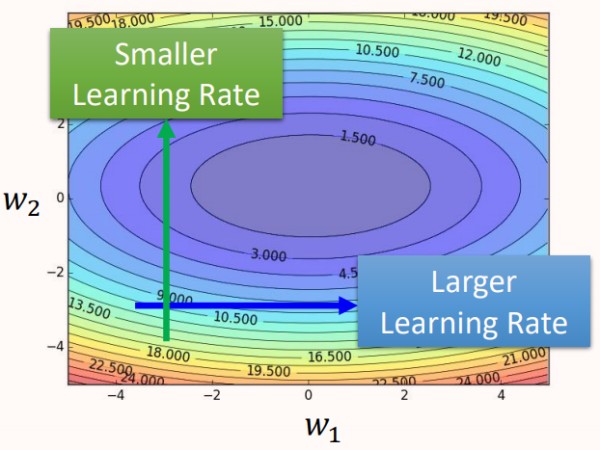
如图所示,不同的参数的error surface的变化情况不同,也就需要不同的学习率,所以要对的每个参数每个时刻都定制一个学习率。
改进思路:对每一个参数的每一轮更新,我们将其学习率都除以一个超参数σit" role="presentation">σit,每一个参数的每一个轮计算所使用的超参数σit" role="presentation">σit都是不一样的。
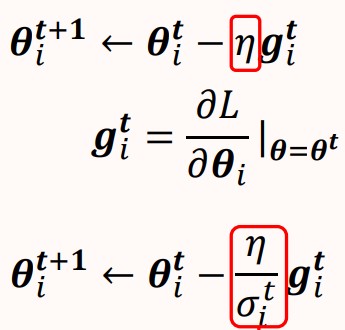
Root Mean Square#
RMS的超参数σit" role="presentation">σit是所有梯度的均方根,计算过程如下。
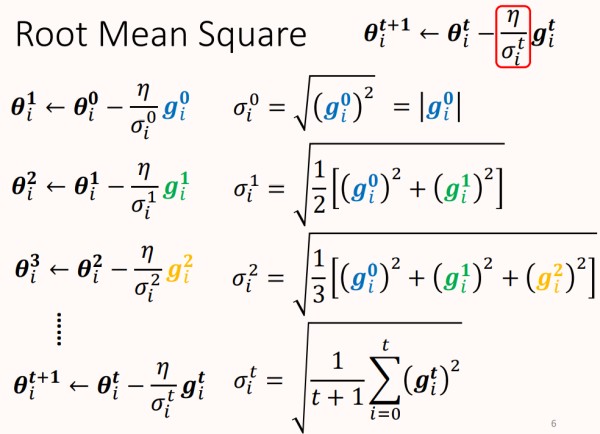
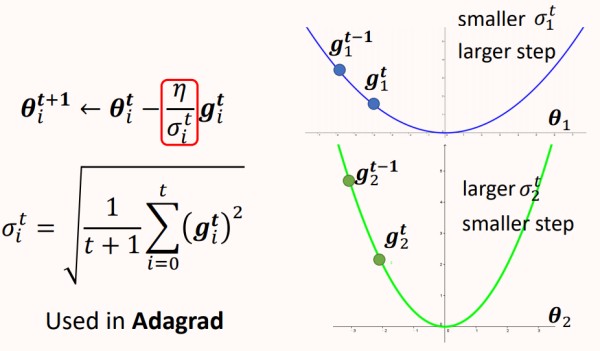
如上图所示,σ" role="presentation">σ能够很好的适应不同的梯度,在error surface平缓的时候,σ" role="presentation">σ很小,使得参数更新的步伐很大。在error surface陡峭的时候,σ" role="presentation">σ很大,使得参数更新的步伐很小,这种策略运用于Adagrad中。
优点:考虑了历史的梯度情况,可以根据当前的梯度情况对学习率做出调整。
缺点:σ" role="presentation">σ来自于历史所有的梯度的均方根,所以梯度变化时,σ" role="presentation">σ不能很快的变化,使得参数更新的学习率不能及时得到调整。
RMSProp#
基于RMS考虑历史梯度的思想,RMSProp在RMS的基础上进行了调整,增加了用于调节历史梯度和当前梯度的权重α" role="presentation">α ,使得RMSProp方法能够根据梯度的变化迅速调整学习率。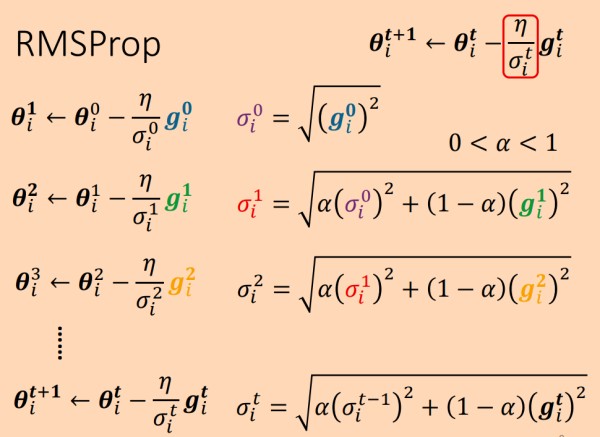
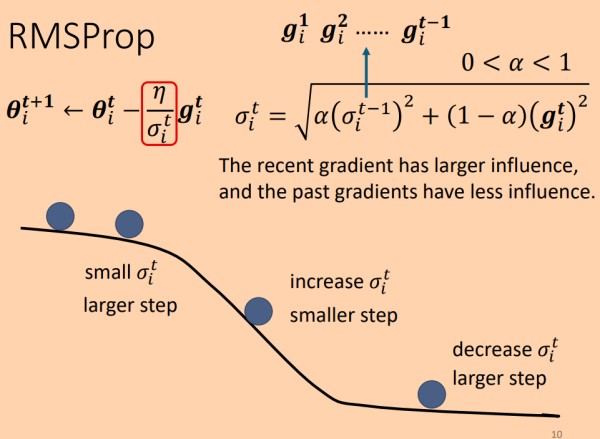
其中σ" role="presentation">σ 来自于历史的 σ2" role="presentation">σ2和当前梯度g" role="presentation">g的加权和的根,α" role="presentation">α 用于调节两者之间的比例,相比与RMS,最近的梯度可以对学习率产生更大的影响。
Adam#
Adam方法结合了RMSProp和Momentum。
RMSProp:主要控制参数的更新速率(学习率)
Momentum:控制参数更新的方向。

Learning Rate Scheduling#
通过使用自适应的学习率后,相比于固定的大的学习率和小的学习率,能顺利完成训练,但是在快要抵达最优点时,蚕食更新方向出现了偏移,这是因为学习率很大,参数w" role="presentation">w方向的梯度出现了累积,累积到一定程度改变了参数的更新方向。
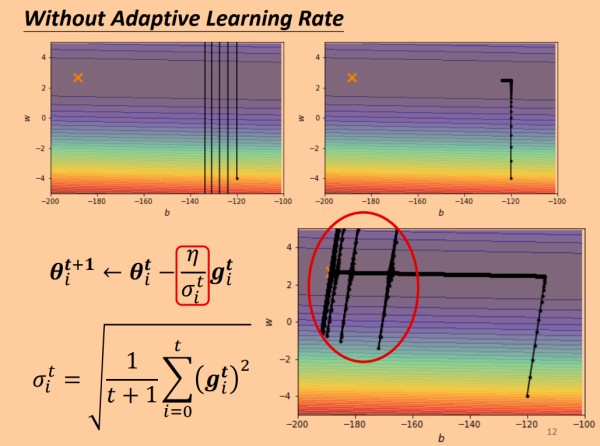
为了避免上述现象,我们需要为学习率指定策略,之前我们的改变方法都是将学习率 η" role="presentation">η 除以一个值,η" role="presentation">η 自身的取值不变,这就避免了上述情况。
直观方法:模型刚开始时,误差很大,所以需要大的学习率,随着时间变化,模型误差逐渐减小,学习率也应逐渐减小。
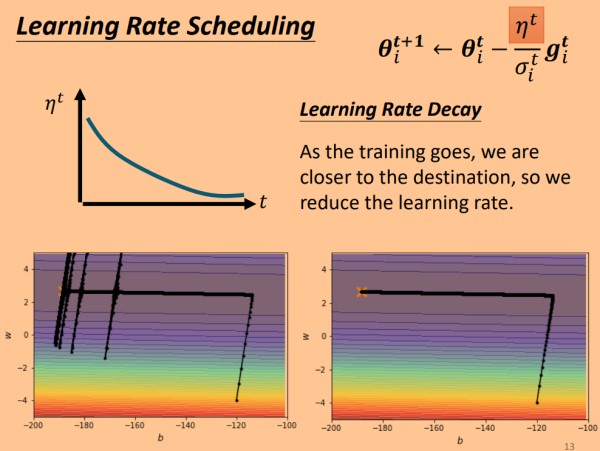
所以使用变化的η" role="presentation">η,最开始选用较大的值,随着时间变化,η" role="presentation">η 越来越小,最终趋近于一个极小值,使用这样的策略,可以避免训练快结束时方向大幅度偏离。
学习率策略一般有两种:Learning Rate Decay 和 Warm Up.
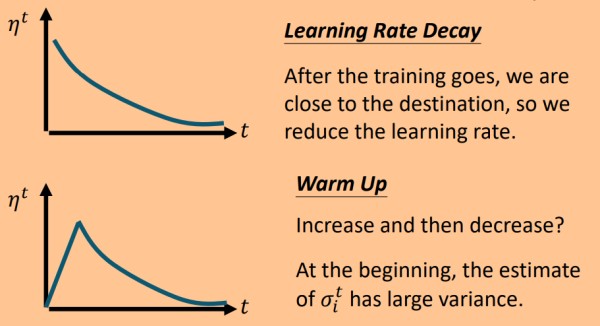
Warm Up: 最开始时,学习率由小到大增长,增长到一定程度便随着时间减小。
Warm Up 直观解释:因用于调节学习率的 σ" role="presentation">σ 由历史梯度得到,最开始时σ" role="presentation">σ 由少量历史梯度计算得到,不够稳定,若给以较大的η" role="presentation">η ,则导致学习过程易产生较大的偏差,所以最开始时慢慢提升学习率。
总结#
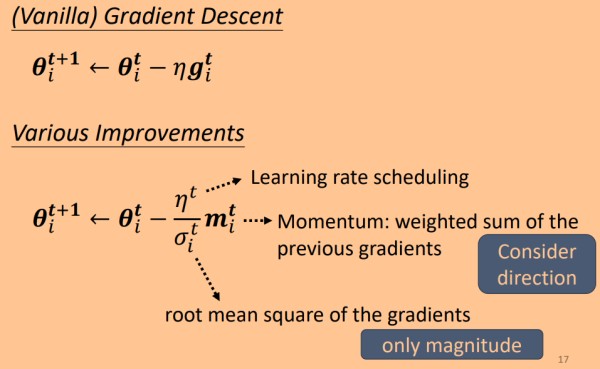
可在传统的梯度更新策略基础上做出如下改变
Learning rate scheduling:设置学习率变化策略。
Momentum:考虑参数更新的方向。
Root Mean Square:考率历史梯度,并对当前参数更新幅度做出调整。
网址:李宏毅机器学习(六) 神经网络训练技巧(2) https://www.yuejiaxmz.com/news/view/374230
相关内容
节省显存新思路,在 PyTorch 里使用 2 bit 激活压缩训练神经网络【机器学习】深度神经网络(DNN):原理、应用与代码实践
训练神经网络的五大算法
GAN的训练技巧:炼丹师养成计划 ——生成式对抗网络训练、调参和改进
关于训练神经网路的诸多技巧Tricks(完全总结版)欢迎访问Oldpan博客,分享人工智能有趣消息,持续酝酿深度学习质量
李弘毅机器学习笔记:回归演示
大规模神经网络最新文献综述:训练高效DNN、节省内存使用、优化器设计
神经网络在教育领域的应用:个性化教学与学习助手
【Matlab学习手记】BP神经网络数据预测
关于神经网络的调参经验技巧和调参顺序
随便看看
最新动态分享
- 二手环保设备,二手污泥脱水设备,二手污水处理设备价格
- 二手消费全球走红,转转:年轻人环保理念提升,消费但不浪费
- 环保共建引领低碳生活
- 【二手环保检测仪】、二手环保检测仪专题
- 丽水二手生活日用
- 废品扫码变现!书院社区智能回收柜引领绿色生活新风尚
- 环保二手·环保二手手机回收平台app
- 永年县诗尼曼全屋定制:环保材质+智能家居=品质生活新选择
- 石家庄二手置物架转让 石家庄二手家居 环保生活
- 唐山沙发电话
热点动态分享
- 140979
- 41726
- 36944
- 31073
- 28445
- 24000
- 21922
- 18366
- 15409
- 15183

