一种基于深度学习的数据清洗方法与流程
理解大数据处理的基本流程 #生活技巧# #工作学习技巧# #数字技能学习#
1.本发明涉及图像处理领域,尤其涉及一种基于深度学习的数据清洗方法。
背景技术:
2.在深度学习研究中,往往需要大量的带标签的样本数据进行模型训练,再通过训练好的模型来对无标签的数据进行预测。例如图像分类,顾名思义,是指输入一张图像,输出一个已知的混合类别中的一个标签,基于深度学习算法的图像分类模型,往往会输出多个标签的类别概率,也就是预测分数,然后取其中分数最大的那一类标签为最终预测类别。这样训练样本的数量和质量直接决定了模型预测的准确度。
3.然而大规模、高质量的图像数据往往很难从现实生活中去获取,很多时候只能借助于互联网去获取原始数据,再对获取到的数据进行清洗和处理。但是网络上的数据参差不齐,质量无法保证,有可能存在图像类别标记错误,或者图像主题不突出,水印文字噪声过多等问题,不适合直接作为样本数据来对深度学习模型进行训练和测试,故需要对原始数据进行清洗,过滤掉其中的“脏”数据,提升训练和测试数据的质量。
4.目前已有的图像数据清洗方法中,主要包括统计法、人工检测、关联聚合等操作,对数据集中类别数过少、模糊、重复、或带有大量噪声的图像类数据直接进行删除。人工检测是最普遍的图像筛选方法,其优势在于精度高,不易误删除,缺点在于需要消耗大量的人力成本,速度较慢,当面对海量的图像数据时,图像清洗的效率比较低。另外,也有通过算法来自动化的对低质量的图像数据进行筛选,例如计算图像的相似度,将相似度较高的图像筛选出来,过滤掉重复的数据,或者利用已经预训练好的模型来对原始图像进行分类预测,对分类精度较低的图像直接进行剔除,以达到数据清洗的目的。但是这些基于算法的清洗方法也存在一定的问题,当算法或者模型的稳定性或鲁棒性不够高的时候,容易将正常样本的类别预测成错误的类别,或者类别预测正确但是预测的分数较低,会将原始数据直接给删除掉,造成有效数据的误删,或者由于模型误分类导致无效数据被保留,最终导致数据清洗效果不理想。
技术实现要素:
5.发明目的:本发明针对上述不足,提出了一种基于深度学习的数据清洗方法,基于深度学习图像分类算法进行迭代式模型训练、预测,并利用预测类别分数的标准差作为图像初次筛选的依据,重复多次,最终剔除掉标准差超过一定阈值,并且对图像分类模型准确率提升没有帮助的样本数据,以此来达到数据清洗的目的。
6.技术方案:
7.一种基于深度学习的数据清洗方法,包括步骤:
8.(1)获取不同类别的原始图像数据形成原始图像数据集,等分成若干子集,并分别以各个子集构建相应的图像分类模型;
9.(2)采用步骤(1)得到的各个图像分类模型对原始图像数据集中每个图像进行类
别预测,分别得到相应类别及其分数,并计算得到相应图像分类模型的类别预测分数的标准差,并将其与设定阈值比对,若小于设定阈值,则该图像分类模型所对应的子集定义为正常图像数据集,否则定义为异常图像数据集;其中相应类别的分数表示图像分类模型对某一图像的类别预测为该类别的概率;
10.(3)以步骤(2)得到的正常图像数据集作为基准图像数据集,并按照简单随机抽样的方式生成训练集和检验集,基于深度学习的图像分类算法通过训练集训练得到相应的图像分类模型作为基准模型,并通过检验集计算该基准图像分类模型的分类准确率作为基准分类准确率;
11.(4)将步骤(2)得到的异常图像数据集等分成n份图像数据集,将其中一份放入正常图像数据集中形成新的图像数据集,依照步骤(3)的方法构建相应的图像分类模型,并计算图像分类模型的分类准确率与基准分类准确率比对,若低于基准分类准确率,则将该份图像数据集删掉;若高于基准准确率,则保留该份图像数据集并作为正常图像数据集,重复本步骤直至所有图像数据集处理完毕;
12.(5)将所有的正常图像数据集的图像汇总,得到有效图像集合。
13.所述步骤(1)中,利用网络爬虫技术或者通过人工网络搜索搜集得到不同类别的原始图像数据形成原始图像数据集。
14.所述步骤(1)中,对所述原始图像数据集的每个图像定义标签,并依据该标签及图像的相应类别构建索引。
15.所述步骤(1)、(3)、(4)中,构建相应的图像分类模型具体为:
16.(11)对图像数据集采用简单随机抽样的方式,以8:2的比例生成训练集和检验集,得到相应的图像样本数据;
17.(12)基于深度学习的图像分类算法根据图像类别在相应的训练集训练得到相应的图像分类模型,并通过对应的检验集进行检验以优化图像分类模型。
18.所述步骤(12)中,图像分类算法采用resnet、vgg
‑
16或googlenet。
19.所述步骤(2)中,设定阈值为0.1~0.3。
20.所述步骤(3)中,所述分类准确率accuracy的计算公式为:
21.accuracy=n
acc
/n
total
22.其中,n
acc
为检验集中预测类别和真实类别一致的样本数量,n
total
为样本总量。
23.有益效果:本发明相对于人工方法,数据清洗效率有一定的提高,数据清洗的质量也有一定的保证,同时也丰富了现有的图像自动化清洗方法。
附图说明
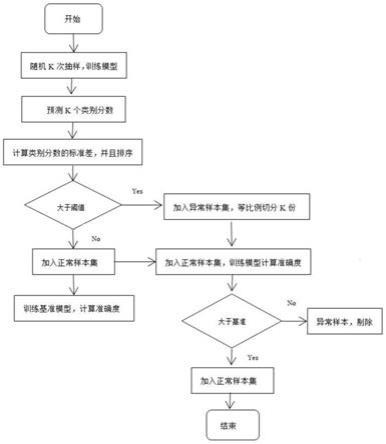
24.图1为本发明的数据清洗方法的流程图。
具体实施方式
25.下面结合附图和具体实施例,进一步阐明本发明。
26.低质量或无效的图像数据包含大量的噪声信息,如图像模糊不清或者有大量水映文字等干扰信息,或者是图像信息和标签不一致等,这部分数据对模型训练以及预测具有一定的干扰性,导致最终训练出来的模型对那些分类特征不明显的图像数据预测不稳定,
多次预测差异较大。
27.图1为本发明的数据清洗方法的流程图。如图1所示,本发明的具体实施步骤如下:
28.(1)搜集包括不同类别的原始图像数据集并构建索引;
29.(11)利用网络爬虫技术或者通过人工网络搜索搜集得到一批不同类别的原始图像数据形成原始图像数据集;
30.(12)对该原始图像数据集的每个图像定义标签,并依据该标签及图像的类别构建索引;每个索引可一一对应原始图像集中的每张图像以及该图像对应的类别,即构成一个样本,方便后续对原始图像集中的每个样本进行区分和快速查找;
31.(2)对原始图像数据集进行等比例划分,生成k个子集(5≤k≤10),每个子集包含相同数量的图像数据,然后对每个子集采用简单随机抽样的方式,以8:2的比例生成训练集和检验集,这样基于原始数据集总共生成了k对训练集和验证集的图像样本数据。
32.(3)选择一个深度学习领域中的常用的图像分类算法,依次根据图像类别在k对训练集和检验集上进行训练和检验。在每一轮模型训练时,模型首先会在训练集上进行训练,然后在对应的检验集上对模型性能进行检验,以此来优化模型;最终会生成k个不同的图像分类模型。图像分类算法包括但不限于:resnet、vgg
‑
16、googlenet等。
33.(4)采用步骤(3)训练好的k个图像分类模型依次对原始图像数据集中的每张图像进行类别预测,根据所有预测类别分数中最大时所属的类别可预测得到每个图像的类别,并得到对应类别的分数,这样每个图像就得到k组类别及其分数的组合。本发明中,对应类别的分数指:图像分类模型对某一图像的类别预测为该类别的概率。
34.例如:假设图像分类模型对一张图像的类别预测输出为:{“dog”:0.95,“cat”:0.04,“panda”:0.01},即图像分类模型对这张图像的类别预测为dog的概率为0.95,预测为cat的概率为0.04,预测为panda的概率为0.01,取其中概率最大的类别为最终的预测的类别,即为dog,对应的分数为0.95。
35.(5)基于步骤(4)得到的原始图像集中每个图像预测出的k组类别及其分数的组合,计算对应图像分类模型的类别预测分数的标准差,进而得到k组类别预测分数的标准差;标准差用来衡量不同模型对单个图像数据预测的稳定性,类别分数的标准差越大,说明模型对图像的预测波动性较大,以此可以推断该图像包含的分类特征不明显,或者该图像数据存在较多的噪声或者图像标签与真实的类别可能存在不一致性,对模型的正确预测带来一定的干扰;
36.(6)将步骤(5)中得到的原始图像数据集中k组类别预测分数的标准差从高到低进行排序,然后基于经验值设定一个阀值,将超过该阀值的对应图像样本数据视为异常图像数据集,而低于该阈值的所对应的图像样本数据集定义为正常图像数据集;
37.本发明中,可将阈值设为0.1~0.3,即对类别预测分数标准差排序后的图像数据集中,前10%~30%的图像数据视为异常图像数据集,余下的图像数据即被视为正常的图像数据集。
38.(7)将步骤(6)中筛选出来的正常图像数据集作为基准图像数据集,同样按照简单随机抽样的方式以8:2的比例生成训练集和检验集,然后训练一个基准模型,并计算该模型在检验集上的分类准确率,将其作为基准分类准确率。
39.其中分类准确率accuracy的计算公式为:
40.accuracy=n
acc
/n
total
41.其中,n
acc
为检验集中中预测类别和真实类别一致的样本数量,n
total
为检验集中的样本总量;
42.(8)将步骤(6)中筛选出来的异常图像数据集按等比例分成n份,每次拿出其中一份数据放入正常图像数据集,形成一份新的图像数据集,再对这份新的图像数据集按照一定的比例抽样(如8比2),生成训练集和测试集后重新用之前的分类算法在新的训练集上进行模型训练,并计算该模型在测试集上的分类准确率。若训练后的模型的分类准确率低于基准的分类准确率,则将该部分异常图像数据集删除掉,后续不再参与训练,若高于基准准确率,则保留该部分图像数据集,并视为正常图像数据集,继续下一次迭代,直到完成n次迭代。
43.(9)将正常图像数据集的图像汇总,即可视为算法自动清洗后的有效图像集合,可用于后续的深度学习算法研究。
44.本发明通过深度学习中的图像分类算法对原始数据集进行多轮模型迭代训练,再基于每次训练的模型来对原始图像进行类别预测,基于预测类别分数的标准差作为图像有效性的评估指标进行初步筛选,再对筛选出来的无效数据进行准确度评估,低于基准准确度的无效数据即被清洗掉,而高于基准准确度的无效数据则转为有效数据集被保留下来。
45.以上详细描述了本发明的优选实施方式,但是本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种等同变换(如数量、形状、位置等),这些等同变换均属于本发明的保护范围。
网址:一种基于深度学习的数据清洗方法与流程 https://www.yuejiaxmz.com/news/view/378369
相关内容
基于深度学习的玻璃清洁度的检测方法及装置与流程一种基于深度学习的个性化推荐系统
一种基于互联网技术的生活优化方法与流程
基于深度学习的生活垃圾检测与分类系统(网页版+YOLOv8/v7/v6/v5代码+训练数据集)
一种光学玻璃表面超净清洁方法与流程
基于深度学习的盲人行路辅助软件设计
一种玻璃清洗剂及其制备方法与流程
一种基于数字权益产品的供应链优化方法及系统与流程
一种基于元宇宙的健康数据管理系统技术方案
深度学习语音识别方法概述与分析
随便看看
最新动态分享
- 从职场到课堂:30岁后的重返校园,动力何在?
- 了解了安万的人生经历之后会不由自主地联想到莎士比亚的人生历程
- 生活艺术与个人成长
- 文学教育与个人成长的关系试题及答案.docx
- 2019年个人成长与技术提升计划
- 王佳怡的黑暗往事:从富家女到艺术家的蜕变
- 馨月老师《创造丰盈》个人成长:找到爱的源头
- 走进画学:用画笔记录成长的美好瞬间
- 丁真学川剧:传统文化的新传承之路
- 直接发育型:生命的奇迹与成长的艺术
热点动态分享
- 3043
- 2895
- 2835
- 2552
- 2359
- 1920
- 1675
- 1531
- 1514
- 1336

