【Python】使用Beautiful Soup解析搜狐新闻网页,并从网页中抓取数据
编写Python爬虫抓取网页数据 #生活知识# #编程教程#
1、准备工作(安装bs4库,lxml库)
File -> settings for new Project -> Project Interpreter -> 点击右上方加号 -> 搜索框搜索bs4或lxml -> 点击Install Package
2、打开搜狐新闻首页,定位数据
将鼠标光标停留在对应的数据位置并右击 --》在快捷键菜单中选择“检查“命令
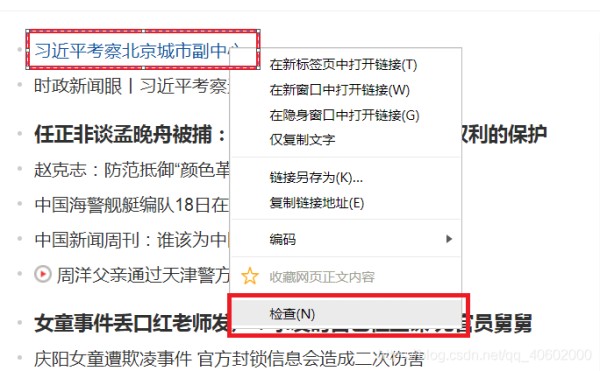
随后在浏览器的右侧出现开发者界面,右击右侧高亮数据,在弹出的快捷菜单中选择”Copy“ -->"Copy Selector"命令,便可自动复制路径
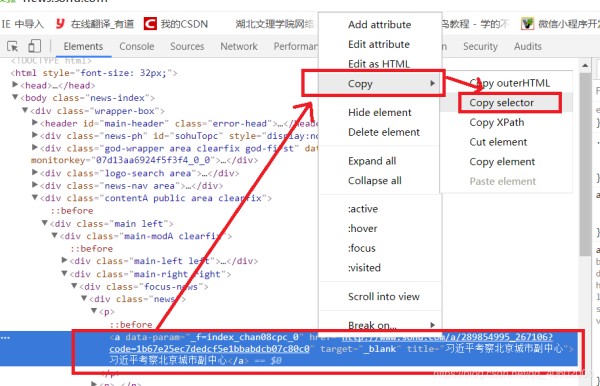
将路径粘贴到文档中(编写代码会用到)
3、撰写代码
import requests
from bs4 import BeautifulSoup
url = 'http://news.sohu.com/'
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text, 'lxml')
data = soup.select('body > div.wrapper-box > div.contentA.public.area.clearfix > '
'div.main.left > div > div.main-right.right > div > div.news > '
'p > a')
for item in data:
result = {
'title': item.get_text(),
'link': item.get('href')
}
print(result)
4、爬取数据结果

网址:【Python】使用Beautiful Soup解析搜狐新闻网页,并从网页中抓取数据 https://www.yuejiaxmz.com/news/view/415589
相关内容
告别重复任务!帮你实现自动化生活的4个网页抓取项目推荐使用:Python驱动的个人助手
使用Python自动下载电视节目
分享4个方便且好用的Python自动化脚本
五个方便好用的Python自动化脚本
如何使用 Python 自动化日常任务
Python学习(一)
轻松实现日常任务自动化的6个Python脚本
掌握Python,高效生活:揭秘5个实用脚本,轻松解决日常编程难题!
使用手机凤凰网官网高效获取新闻资讯的五个技巧
随便看看
最新动态分享
- 丢铺免费正版 v1.2.2.28
- 旧货业节能减排路径研究分析报告.docx
- 旧货企业投资效益分析报告.docx
- 爱回收官方下载
- 绒花雪绒花:吐槽一下以旧换新的旧物回收! 家里热水器最近有点儿漏水,上网查了下原因,可能是内胆漏水了。 现在这电器维修不划算,涉及水电的东西安全更重要。而且看到国家有以旧换新政策,还能享受国补15~20%优惠,就下单了一款海尔热水器,勾选以旧换新选项,不然旧热水器放家里占地方还碍事儿,回收了兴许有点用,两全其美多好啊! 想法很美好,过程很糟糕! 2月20日下单当天,收到了蚁巢预约短信。因新热水...
- 关于免费提供《旧货行业相关法规政策汇编》的通知
- 青塔街道开展旧物改造手工制作活动
- 以旧换新补贴回收
- 个人投资理财规划(完整版)
- 大学生个人理财方案设计课件
热点动态分享
- 136485
- 37571
- 36259
- 23774
- 23315
- 22293
- 21360
- 14956
- 14947
- 14897

