5. 学习笔记:使用MindNode或Evernote做笔记 #生活技巧# #工作学习技巧#
最新推荐文章于 2023-11-04 21:24:25 发布

 songyuequan 于 2018-05-18 10:00:56 发布
songyuequan 于 2018-05-18 10:00:56 发布
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
Home
optimization problem
θ∗=argminθL(θ)

Tip 1: Tuning your Learning rates
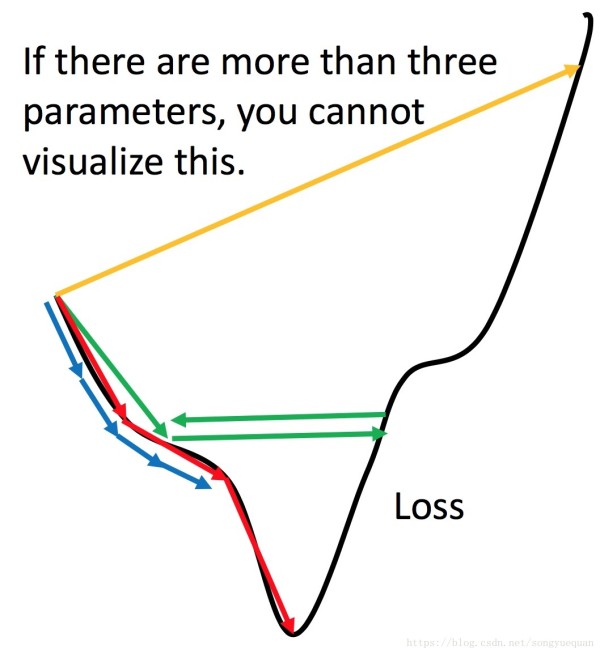
- 1 small 如果步伐非常小 训练的时间会非常长。
- 2 large 如果步伐非常大 没有办法走到最低点。会在一个范围震荡
- 3 very large 如果步伐太大 loss很快就飞出去了。
visionlize loss 和 参数更新的关系。 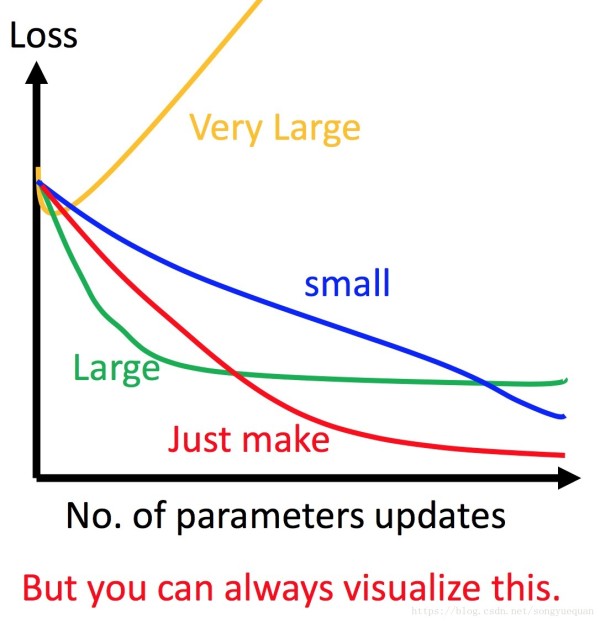
- 1 learning rate 太小 loss下降非常慢
- 2 lerning rate 太大 loss下降非常快 但是很快就卡住。
- 3 learning rate 特别大 loss很快就飞出去了。
在做梯度下降的时候,最好把这个图画出来。否则你不知道这个梯度下降在哪里坏掉了。 Adaptive Learning Rates Popular & Simple Idea: Reduce the learning rate by some factor every few epochs. 通常leaning rate 随着参数的update会减小。
At the beginning, we are far from the destination, so we use larger learning rate(刚开始的时候,离最低点比较远,所以你的步伐需要大一点。) After several epochs, we are close to the destination, so we reduce the learning rate(经过几次更新之后呢,已经比较靠近目标了,这时候就应该减小learning rate) eg ηt=η/√t+1
Learning rate cannot be one-size-fits-all Giving different parameters different learning rates
不同的参数有不同的learning rate)
Adagrad 
w1←w0−η0δ0g0δ0=√(g0)2
w2←w1−η1δ1g1δ1=√12[(g0)2+(g1)2]
网址:李宏毅Machine Learning学习笔记3 Gradient Descent https://www.yuejiaxmz.com/news/view/419555
相关内容
李弘毅机器学习笔记:回归演示Deep Learning(深度学习)学习笔记整理系列之(四)机器学习Machine Learning:成本(cost) 函数,损失(loss)函数,目标(Objective)函数的区别和联系?终身学习(LifeLong Learning)/ 增量学习(Incremental Learning)、在线学习(Online Learning)李宏毅机器学习(六) 神经网络训练技巧(2)DeepLearning(深度学习)学习笔记整理.pdf资源链接、资源(学习)人工智能与交互设计:如何结合创新技术改变现实生活智能决策支持系统的评估与优化方法1.背景介绍 智能决策支持系统(Intelligent Decision Support批量学习与在线学习
随便看看

