python爬虫实现实时爬取学校最新通知并推送
Python爬虫实战:requests库应用 #生活知识# #编程教程#
1.背景
由于考研复试需要实时获取报考学校的最新通知,以免错过重要的消息,而手动刷新的方式费时费力,因此想到通过爬虫实现实时获取最新通知的功能。但还需解决几个问题:
爬虫爬取的最新通告,采用什么方式推送爬虫爬取的频率设置为多快爬虫应该部署在哪里对于上述的几个问题,经过一番研究后,得出了结论:
想过很多种方法,例如收到通知后采用电子邮件,微信机器人,QQ机器人等,后来发现实现起来都没有非常方便,最后发现了一个相当方便的推送方法,叫虾推啥(点击进入官网)。这是个公众号,关注后获取自己的token,仅用几行代码就可以将通知以公众号推送的方式,通过微信提醒自己。另外相似的还有server酱,由于我只需要实现推送文字通告,而两者在这方面相差不大,虾推啥实现起来更方便,因此选用了虾推啥。为了防止访问过于频繁,后面决定执行的速度为每小时一次。若将爬虫部署在本地,那么想要实现实时推送,必须24小时打开计算机,这显然是不方便的,因此最后决定部署在云服务器上。云服务器有阿里云和腾讯云服务器等,这里使用的是阿里云服务器,经过学生认证和测试,可以免费使用两个月。2.实现过程
2.1准备工作
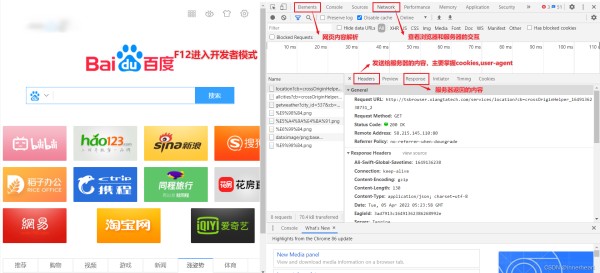
2.1.1分析页面由于不同的网页排版的不同,因此在爬取网页内容时应具体分析,这里只给出了一般分析网页的基本方法,即F12进入开发者模式,然后通过Elements和Network中的内容来判断应该如何获得内容。
爬虫主要需要用到以下第三方库,并且给出了这些库的具体用法。
import bs4
import re
import urllib
import sqlite3
'BeautifulSoup的具体用法。
from bs4 import BeautifulSoup
import re
bs = BeautifulSoup(html, "html.parser")
print(bs)
print(bs.title)
printf(bs.title.string)
printf(bs.title.attrs)
bs.find_all("a")
t_list = bs.find_all(re.complie("a"))
t_list = bs.find_all(id="head")
t_list = bs.find_all(class_="head")
t_list = bs.select(".xxx")
t_list = bs.select("#xxx")
li_list = bs.select("ul > li > span")
li_list = bs.select(".xxx1 ~ .xxx")
print(li_list[0].get("href"))
sqlite3的具体用法。
import sqlite3
connect = sqlite3.connect("xxx")
c = conn.cursor()
sql = ''' '''
c.execute(sql)
connect.commit()
connect.close()
2.2代码编写
2.2.1思路首先确定爬虫实现的功能为:爬取最新的公告并推送。
因此每次执行爬虫操作时得到的应该是网站最新的一条公告,那么如何保证保证每次推送的都是最新消息呢?这里用到了数据库sqlite3,将每次得到的最新公告先在数据库中进行查询,如果为空,说明该公告未被推送过,推送到微信,并且将这条记录插入到数据库;如果数据库已经存在该记录,那么说明不是最新公告,不执行推送操作。这样就解决了保证每次推送的公告不重复,并且是最新公告的问题。因此关于数据库的操作应该为,爬虫项目在执行时就初始化数据库,该操作主要是不存在数据库则建立数据库,并且建表;否则连接数据库。
其次是要生成请求,得到响应。这里主要用到的是urllib,并且需要在请求中填入用户代理,即2.1.1中提到的user-agent,以便爬虫伪装浏览器得到html页面。
然后就是使用BeautifulSoup 分析得到html页面中的标签,以得到自己所需要的内容。这里只需要得到公告标题,标签中的网址后缀,发送公告的日期三个内容,然后合成一个字典返回。
最后就是推送到微信。这一步还需要拆解成两个方法来编写:首先需要一个保存数据的方法,尝试将得到的内容保存到数据库,这一步的作用是如果保存成功,则说明是最新通告,因此才能推送到微信,否则不进行操作,因此需要一个分支语句。
2.2.2具体代码根据以上的思路分析,实际需要编写的方法应该为5个。
首先是初始化数据库,传入数据库的路径,若存在则连接,否则建立数据库。
def init_db(dbpath):
sql = '''
create table if not exists 'notice_info'
(
title text,
date text
)
'''
connect = sqlite3.connect(dbpath)
c = connect.cursor()
c.execute(sql)
connect.commit()
connect.close()
'然后是发送请求,发送响应,即得到一个网页的内容,这里进行了异常的捕捉。
def askURL(url):
head = {
'User-Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / '
'100.0.4896.60 Safari / 537.36 Edg / 100.0.1185.29 '
}
request = urllib.request.Request(url, headers=head)
try:
reponse = urllib.request.urlopen(request)
html = reponse.read()
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
'其次是提取需要的内容,首先使用BeautifulSoup 解析网页,然后使用select方法进行层级解析,并形成一个字典返回
def dataExtarct(html):
bs = BeautifulSoup(html, "html.parser")
li_list = bs.select("ul > li > span > a")
li_list2 = bs.select("ul > li > strong")
mydata = {
"href": base_URL + li_list[0].get("href"),
"title": li_list[0].get_text(),
"date": li_list2[0].get_text()
}
return mydata
'最后是推送到微信,推送前需要尝试保存数据,若保存成功则发送数据,否则不执行操作。save_data方法首先是利用SQL语句统计数据库中是否存在该记录,若存在返回0,表示不推送消息,否则需要插入数据,并且返回1,推送消息。
def insert_data(mydata, connect):
sql = "insert into notice_info(title, date) values('" + mydata["title"] + "', '" + mydata["date"] + "');"
c = connect.cursor()
c.execute(sql)
connect.commit()
connect.close()
def save_data(mydata, dbpath):
sql = "select * from notice_info where title = '" + mydata["title"] + "' and date = '" + mydata["date"] + "';"
print(sql)
connect = sqlite3.connect(dbpath)
c = connect.cursor()
cursor = c.execute(sql)
result = 0
for row in cursor:
print(row)
result += 1
if result == 0:
insert_data(mydata, connect)
return 1
else:
return 0
'推送消息比较简单,利用虾推啥将文字通过post方法推送,最大可推送64k文字。
def sendMessage(token, mydata):
baseurl = "http://wx.xtuis.cn/"
url = baseurl + token + ".send"
data = {
"text": mydata["title"],
"desp": '内容:' + mydata["title"] + '<br>' \
'网址:' + mydata["href"] + '<br>' \
'日期:' + mydata["date"]
}
requests.post(url, data=data)
'2.3部署项目
下面讨论如何将项目部署在云服务器上,以便项目可以不间断的运行。下面的操作建立在已经拥有一个云服务器的基础上。
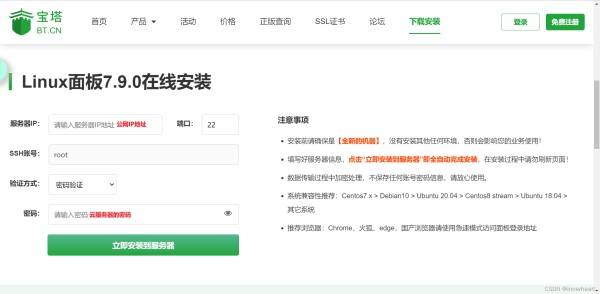
2.3.1安装宝塔面板因购买的服务器未安装任何开发所需的工具,因此可以使用宝塔面板安装大部分的应用,推荐安装LNMP(ginx+MySQL+PHP)。
首先进入宝塔面板(点击进入)的官网,一般推荐安装Linux系统,目前已经有在线安装面板的方法,只需要填写购买的服务器公网IP地址和密码,就可以在线安装。安装完成后,会提示保存创建的面板地址,账号和密码,一定要牢记。
安装完后可能会因为未开放安全组端口而无法登录到以下界面,下面会讲述如何开放安全组端口。

在阿里云云服务器ECS界面首先点击实例,然后点击更多,再点击网络和安全组,最后点击安全组配置。

进入安全组配置页面后,点击配置规则。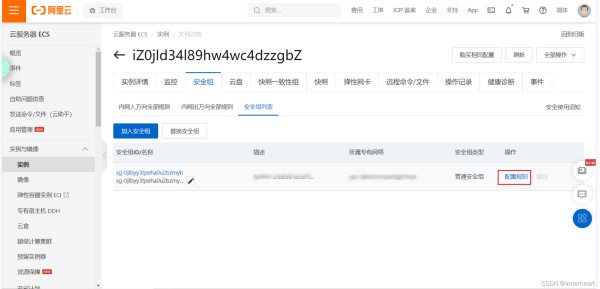
选择入方向,添加方向后目的填写需要开放的端口,源填写0.0.0.0/0,保存即可。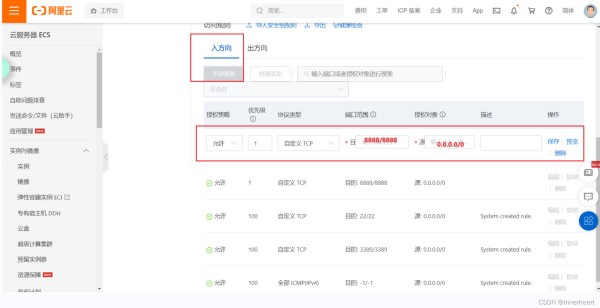
findshell是一个SSH连接工具,可以连接到自己的云服务器,通过终端输入命令的方式执行操作,并且对于文件的增删改查十分方便。 下面给出了下载地址:
Windows版下载地址:
http://www.hostbuf.com/downloads/finalshell_install.exe
Mac版,Linux版安装及教程:
http://www.hostbuf.com/t/1059.html
更新日志:
http://www.hostbuf.com/t/989.html
安装完成以后,下面讲述如何上传项目到云端。
首先点击左上角的文件夹图标,打开连接管理器。
再按下图点击第一个按钮。
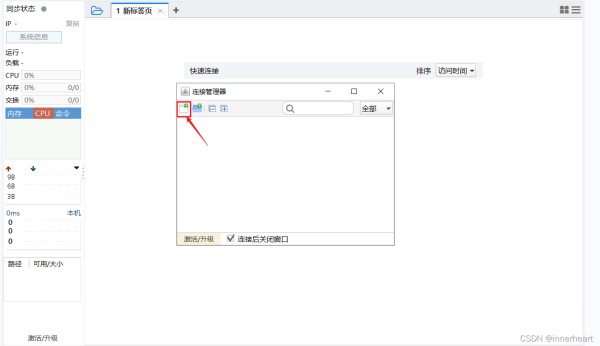
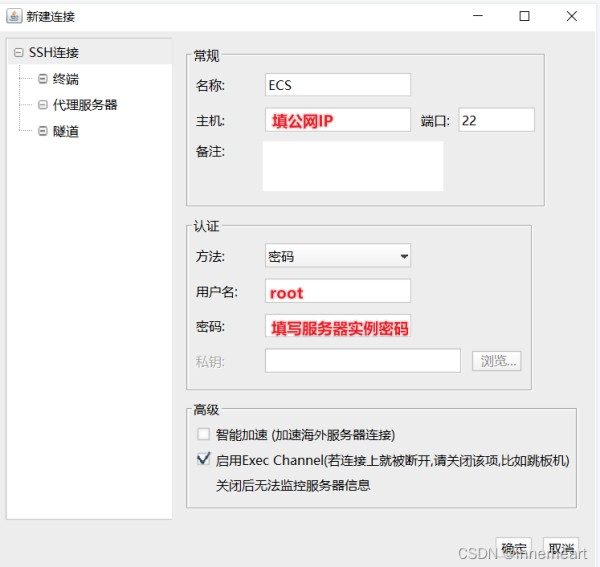
新建的连接框中填入图中的信息,即公网IP,用户名和密码,名称可自定义。
若为第一次连接,则会弹出以下的安全警告,点击接受并保存即可。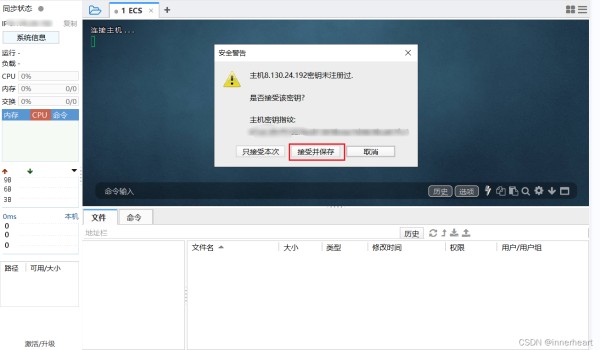
连接实例,输入指令 ssh root@xxx.xxx.xxx,其中xxx.xxx.xxx为公网ip,然后输入密码 注意终端中的黏贴为ctrl+shift+v.

服务器在之前已经安装了必要的环境,但爬虫所用到的一些第三方库还没有安装,因此需要手动安装需要的库。通过输入以下指令,即可安装爬虫所需要的第三方库。
# Linux下安装第三方库的命令,注意为pip3
pip3 install beautifulsoup4
pip3 install pysqlite3
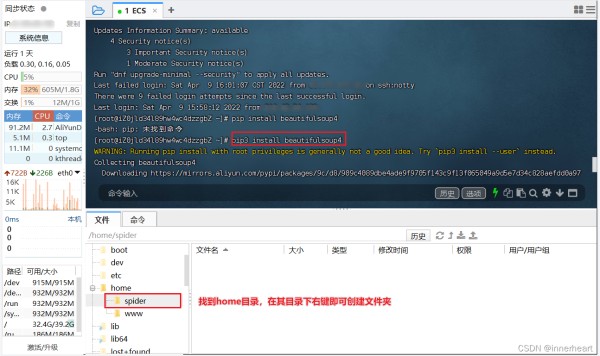
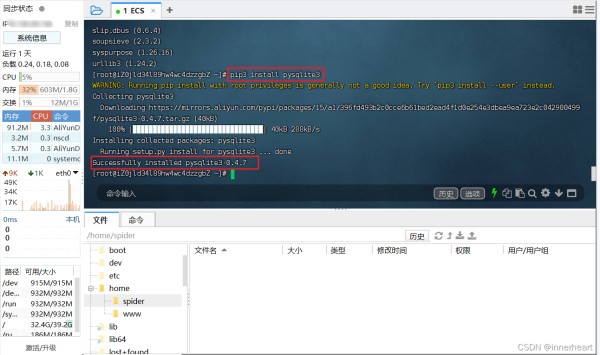
安装完第三方库以后,再将爬虫的源文件和数据库直接拖动到所需要上传的目录下即可。

以上步骤爬虫已经能够成功在服务器上运行,但未实现实时执行的要求。这里需要用到Linux系统的crontab指令,即定时任务。有关于crontab指令的具体参数及使用方法,做一个简单的介绍。crontab命令一般为7个参数,前5个确定执行的具体时间点,第6个参数为该指令的所属者,第7个参数为需要的执行的命令,一般执行脚本文件,.sh为Linux系统的脚本文件后缀名。
项目含义范围第一个"*"一小时当中的第几分钟(minute)0~59第二个"*"一天当中的第几小时(hour)0~23第三个"*"一个月当中的第几天(day)1~31第四个"*"一年当中的第几个月(month)1~12第五个"*"一周当中的星期几(week)0~7(0和7都代表星期日下面还有对于命令的一些例子。
特殊符号 含义*(星号)代表任何时间。比如第一个"*"就代表一小时种每分钟都执行一次的意思。,(逗号)代表不连续的时间。比如"0 8,12,16***命令"就代表在每天的 8 点 0 分、12 点 0 分、16 点 0 分都执行一次命令。-(中杠)代表连续的时间范围。比如"0 5 ** 1-6命令",代表在周一到周六的凌晨 5 点 0 分执行命令。/(正斜线)代表每隔多久执行一次。比如"*/10****命令",代表每隔 10 分钟就执行一次命令。介绍完该指令的基本应用后,就正式开始编写定时任务。
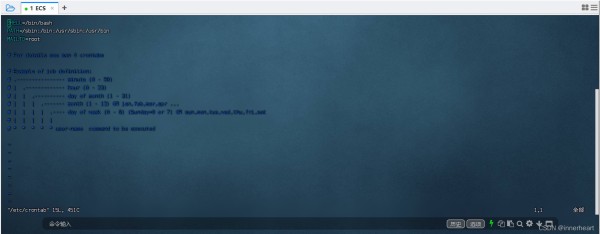
1.vim /ect/crontab 进入一般模式,即上图所示
2.按i进入编辑模式后,将光标移动到下方的波浪号处
3.黏贴已经写好的命令 60 * * * * root /home/spider/spider_notice.sh 这里需要给出脚本文件的绝对路径
4.按esc退出编辑模式,再输入 :wq! 强制保存文件并退出
5.输入 /etc/init.d/cron restart 重启程序 ,若不存在该指令,也可以输入
/sbin/service crond restart 重启服务
3.实现效果
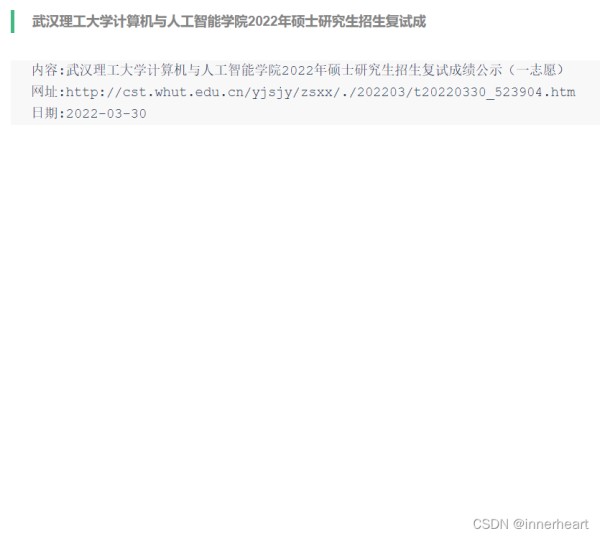
上面已经介绍完所有的工作,接下来展示一下实现的效果图。爬虫获取到最新的通知后,会直接推送到微信,采用公众号提醒的方式,如下面左图所示。点击查看详情后,显示的内容即为下面右图所示,主要为内容,网址,日期三个方面。直接复制网址就可以查看最新的具体通知。

4.总结
本次实现爬虫的原因完全来自于不想要蹲网站等通知,因为等待的过程中一方面是怕看到复试成绩的紧张,另一面又是通知迟迟没有出现的烦躁。因此想要实现一个爬虫自动推送,自此省时省力,缓解了焦虑!
网址:python爬虫实现实时爬取学校最新通知并推送 https://www.yuejiaxmz.com/news/view/503286
相关内容
Python基于网络爬虫的校园食堂菜谱推荐系统的设计与实现Python爬虫抓取基金数据分析、预测系统设计与实现——云诺说
python爬虫代码
python爬虫
python爬虫与数据分析之《向往的生活爬取》
推荐这三款自动化爬虫软件,非常实用!
Python爬虫山东济南景点数据可视化和景点推荐系统 开题报告
Python实现校园网自动登录的脚本分享
python爬取B站千万级数据,发现了这些热门UP主的秘密!
梦见蛆虫满地爬
随便看看
最新动态分享
- 日本家居精致有味!这16个装修大法才实在!活出了主妇们的心灵
- 玄关中西方设计差异
- 超4亿元家居家装消费券今起分三轮发放
- 《消费主张》 20250225 新春走市场:国补引发家居“焕新”热潮!
- 国补再升级,尚品宅配“惠民政策”“服务创新”助力家居消费焕新
- 9月26日晚八点定好闹钟!家居家装消费券准备开抢
- 让家焕发活力的5个装修窍门,告别沉闷老气
- 五招让家具焕然一新(快乐大扫除)
- 简单3步走 新年家居旧貌换新颜
- 妙招教你将家居用品恢复如新.docx
热点动态分享
- 3176
- 2931
- 2923
- 2672
- 2510
- 1972
- 1695
- 1610
- 1594
- 1511

