Python pandas 数据清洗(二)
数据分析:Python的Pandas库数据处理 #生活知识# #编程教程#
关注微信公共号:小程在线

关注CSDN博客:程志伟的博客
Python 版本:
Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)]
Type "copyright", "credits" or "license" for more information.
IPython 7.12.0 -- An enhanced Interactive Python.
本节主要讲解:
1.利用concat和merge对数据进行合并;
2.对空值和重复值进行处理;
3.根据条件进行数据筛选;
4.利用groupby进行分组
一、利用concat和merge对数据进行合并
加载包
import pandas as pd
读取Excel文件
df1=pd.read_excel(r'F:\Python\科室数据集.xlsx',sheet_name='第一人民医院')
df1
Out[2]:
机构 科室 就诊人数 增长率 上期人数
0 第一人民医院 内科 35188 0.0998 31994.908165
1 第一人民医院 外科 28467 0.1127 25583.715287
2 第一人民医院 妇科 35617 0.0850 32826.728111
df2=pd.read_excel(r'F:\Python\科室数据集.xlsx',sheet_name='第二人民医院')
df2
Out[3]:
机构 科室 就诊人数 增长率 上期人数
0 第二人民医院 外科 1981 0.0575 1873.286052
1 第二人民医院 内科 1958 0.1471 1706.913085
2 第二人民医院 妇科 1532 0.0850 1411.981567
df3=pd.read_excel(r'F:\Python\科室数据集.xlsx',sheet_name='第三人民医院')
df3
Out[4]:
机构 科室 就诊人数 增长率 上期人数
0 第三人民医院 外科 1780 0.1315 1573.133009
1 第三人民医院 内科 1447 0.0104 1432.106097
2 第三人民医院 妇科 965 0.0850 889.400922
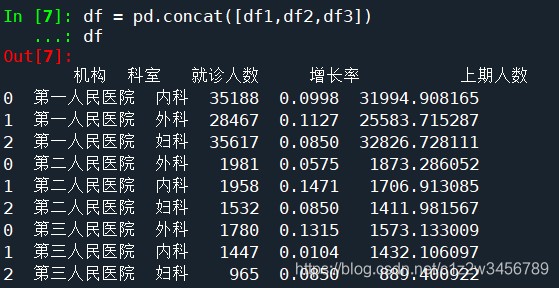
#将数据进行纵行合并
df = pd.concat([df1,df2,df3])
df
Out[7]:
机构 科室 就诊人数 增长率 上期人数
0 第一人民医院 内科 35188 0.0998 31994.908165
1 第一人民医院 外科 28467 0.1127 25583.715287
2 第一人民医院 妇科 35617 0.0850 32826.728111
0 第二人民医院 外科 1981 0.0575 1873.286052
1 第二人民医院 内科 1958 0.1471 1706.913085
2 第二人民医院 妇科 1532 0.0850 1411.981567
0 第三人民医院 外科 1780 0.1315 1573.133009
1 第三人民医院 内科 1447 0.0104 1432.106097
2 第三人民医院 妇科 965 0.0850 889.400922
#创建数据,进行横向合并
w1 = pd.DataFrame({'内科':[865,897,798,958],
'外科':[86,98,75,69],
'妇科':[658,421,395,582]},
index=['第一医院','第二医院','第三医院','第四医院'])
w1
Out[8]:
内科 外科 妇科
第一医院 865 86 658
第二医院 897 98 421
第三医院 798 75 395
第四医院 958 69 582
w2 = pd.DataFrame({'儿科':[97,78,98],
'骨科':[86,98,69],
'妇科':[68,42,58]},
index=['第三医院','第四医院','中医院'])
w2
Out[9]:
儿科 骨科 妇科
第三医院 97 86 68
第四医院 78 98 42
中医院 98 69 58
w2 = pd.DataFrame({'儿科':[97,78,98],
'骨科':[86,98,69]},
index=['第三医院','第四医院','中医院'])
w2
Out[10]:
儿科 骨科
第三医院 97 86
第四医院 78 98
中医院 98 69
#how='inner'表示内连接
pd.merge(left=w1,right=w2,left_index=True,right_index=True,how='inner')
Out[11]:
内科 外科 妇科 儿科 骨科
第三医院 798 75 395 97 86
第四医院 958 69 582 78 98
#how='left'表示左连接
pd.merge(left=w1,right=w2,left_index=True,right_index=True,how='left')
Out[12]:
内科 外科 妇科 儿科 骨科
第一医院 865 86 658 NaN NaN
第二医院 897 98 421 NaN NaN
第三医院 798 75 395 97.0 86.0
第四医院 958 69 582 78.0 98.0
#how='right'表示右连接
pd.merge(left=w1,right=w2,left_index=True,right_index=True,how='right')
Out[13]:
内科 外科 妇科 儿科 骨科
第三医院 798.0 75.0 395.0 97 86
第四医院 958.0 69.0 582.0 78 98
中医院 NaN NaN NaN 98 69
#how='outer'表示全连接
pd.merge(left=w1,right=w2,left_index=True,right_index=True,how='outer')
Out[14]:
内科 外科 妇科 儿科 骨科
中医院 NaN NaN NaN 98.0 69.0
第一医院 865.0 86.0 658.0 NaN NaN
第三医院 798.0 75.0 395.0 97.0 86.0
第二医院 897.0 98.0 421.0 NaN NaN
第四医院 958.0 69.0 582.0 78.0 98.0

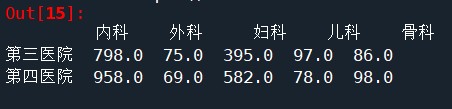
* 删除全连接中含有null的值,相当于对数据集进行内连接操作
w3 =pd.merge(left=w1,right=w2,left_index=True,right_index=True,how='outer')
w3.dropna()
Out[15]:
内科 外科 妇科 儿科 骨科
第三医院 798.0 75.0 395.0 97.0 86.0
第四医院 958.0 69.0 582.0 78.0 98.0
二、对空值和重复值进行处理;
#合并数据进行数据去重
w4 = pd.concat([w3,w3])
print('数据集行数:',len(w4))
数据集行数: 10
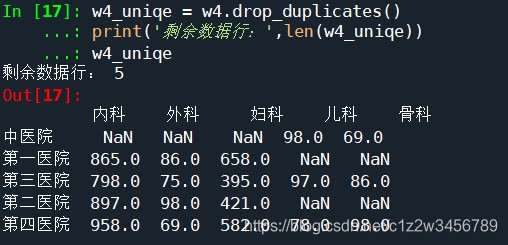
w4_uniqe = w4.drop_duplicates()
print('剩余数据行:',len(w4_uniqe))
w4_uniqe
剩余数据行: 5
Out[17]:
内科 外科 妇科 儿科 骨科
中医院 NaN NaN NaN 98.0 69.0
第一医院 865.0 86.0 658.0 NaN NaN
第三医院 798.0 75.0 395.0 97.0 86.0
第二医院 897.0 98.0 421.0 NaN NaN
第四医院 958.0 69.0 582.0 78.0 98.0
三、按条件筛选数据
#筛选符合条件的数据
w4.loc[(w4['内科']>800)&(w4['外科']>80),:]
Out[24]:
内科 外科 妇科 儿科 骨科
第一医院 865.0 86.0 658.0 NaN NaN
第二医院 897.0 98.0 421.0 NaN NaN
第一医院 865.0 86.0 658.0 NaN NaN
第二医院 897.0 98.0 421.0 NaN NaN
#按照大小对数据进行排序,ascending=False降序排序
w4_sort = w4_uniqe.sort_values('内科',ascending=False)
w4_sort
Out[25]:
内科 外科 妇科 儿科 骨科
第四医院 958.0 69.0 582.0 78.0 98.0
第二医院 897.0 98.0 421.0 NaN NaN
第一医院 865.0 86.0 658.0 NaN NaN
第三医院 798.0 75.0 395.0 97.0 86.0
中医院 NaN NaN NaN 98.0 69.0
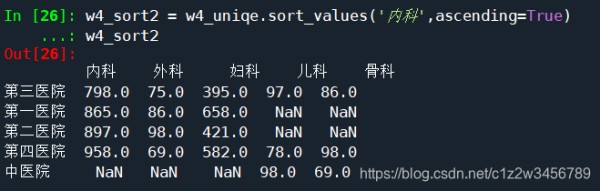
#按照大小对数据进行排序,ascending=True降序排序
w4_sort2 = w4_uniqe.sort_values('内科',ascending=True)
w4_sort2
Out[26]:
内科 外科 妇科 儿科 骨科
第三医院 798.0 75.0 395.0 97.0 86.0
第一医院 865.0 86.0 658.0 NaN NaN
第二医院 897.0 98.0 421.0 NaN NaN
第四医院 958.0 69.0 582.0 78.0 98.0
中医院 NaN NaN NaN 98.0 69.0
四、分组
ks=pd.read_excel(r'F:\Python\科室数据.xlsx')
ks
Out[28]:
地区 机构 科室 就诊人数 增长率 上期人数
0 北京 第一人民医院 内科 35188 0.0998 31994.908165
1 天津 第一人民医院 外科 28467 0.1127 25583.715287
2 上海 第一人民医院 内科 13747 0.0254 13406.475522
3 深圳 第一人民医院 外科 5183 0.0247 5058.065775
4 广州 第一人民医院 内科 4361 0.0431 4180.807209
5 北京 第二人民医院 外科 4063 0.1157 3641.659944
6 天津 第二人民医院 内科 2122 0.1027 1924.367462
7 上海 第二人民医院 外科 2041 0.0706 1906.407622
8 深圳 第二人民医院 内科 1991 0.1652 1708.719533
9 广州 第二人民医院 外科 1981 0.0575 1873.286052
10 北京 第三人民医院 外科 1780 0.1315 1573.133009
11 天津 第三人民医院 内科 1447 0.0104 1432.106097
12 上海 第三人民医院 外科 39048 0.1160 34989.247312
13 深圳 第三人民医院 内科 3316 0.0709 3096.460921
14 广州 第三人民医院 外科 2043 0.0504 1944.973343
#按条件进行统计
ks.groupby('地区').sum()
Out[29]:
就诊人数 增长率 上期人数
地区
上海 54836 0.2120 50302.130455
北京 41031 0.3470 37209.701119
天津 32036 0.2258 28940.188845
广州 8385 0.1510 7999.066605
深圳 10490 0.2608 9863.246229
#按条件对部分列进行分组统计
ks.groupby('地区')['就诊人数','上期人数'].sum()
__main__:1: FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.
Out[31]:
就诊人数 上期人数
地区
上海 54836 50302.130455
北京 41031 37209.701119
天津 32036 28940.188845
广州 8385 7999.066605
深圳 10490 9863.246229
#as_index=False表示不将分组条件作为索引列
ks.groupby('地区',as_index=False)['就诊人数','上期人数'].sum()
__main__:1: FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.
Out[32]:
地区 就诊人数 上期人数
0 上海 54836 50302.130455
1 北京 41031 37209.701119
2 天津 32036 28940.188845
3 广州 8385 7999.066605
4 深圳 10490 9863.246229
#按照某列对数据进行分组,并打标签
ks1 =ks.groupby('地区',as_index=False)['就诊人数','上期人数'].sum()
pd.cut(x=ks1['就诊人数'],bins=[0,10000,20000,30000,40000,50000,60000])
__main__:1: FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.
Out[34]:
0 (50000, 60000]
1 (40000, 50000]
2 (30000, 40000]
3 (0, 10000]
4 (10000, 20000]
Name: 就诊人数, dtype: category
Categories (6, interval[int64]): [(0, 10000] < (10000, 20000] < (20000, 30000] < (30000, 40000] < (40000, 50000] < (50000, 60000]]
ks['等级'] = pd.cut(x=ks['就诊人数'],bins=[0,10000,20000,30000,40000],
right=False,labels=['D','C','B','A'])
ks
Out[35]:
地区 机构 科室 就诊人数 增长率 上期人数 等级
0 北京 第一人民医院 内科 35188 0.0998 31994.908165 A
1 天津 第一人民医院 外科 28467 0.1127 25583.715287 B
2 上海 第一人民医院 内科 13747 0.0254 13406.475522 C
3 深圳 第一人民医院 外科 5183 0.0247 5058.065775 D
4 广州 第一人民医院 内科 4361 0.0431 4180.807209 D
5 北京 第二人民医院 外科 4063 0.1157 3641.659944 D
6 天津 第二人民医院 内科 2122 0.1027 1924.367462 D
7 上海 第二人民医院 外科 2041 0.0706 1906.407622 D
8 深圳 第二人民医院 内科 1991 0.1652 1708.719533 D
9 广州 第二人民医院 外科 1981 0.0575 1873.286052 D
10 北京 第三人民医院 外科 1780 0.1315 1573.133009 D
11 天津 第三人民医院 内科 1447 0.0104 1432.106097 D
12 上海 第三人民医院 外科 39048 0.1160 34989.247312 A
13 深圳 第三人民医院 内科 3316 0.0709 3096.460921 D
14 广州 第三人民医院 外科 2043 0.0504 1944.973343 D
网址:Python pandas 数据清洗(二) https://www.yuejiaxmz.com/news/view/529416
相关内容
利用Python进行数据分析——Pandas(2)大数据清洗随手记(一)
数据清洗:最佳实践与工具推荐
python数据结构练习
数据清洗实战:工业生产数据的深入探讨
Python数据分析实战
Python财务数据分析与金融风险评估
python数据分析
Python中的生活数据分析与个人健康监测.pptx
从零开始:建立高效的数据清洗流程
随便看看
最新动态分享
- 【空调过滤器清洗】怎样清洗空调过滤网 空调过滤器的清洗方法
- 空调的滤网怎么清洗(分享空调滤网怎么拿出来)
- 空调过滤器怎么拆洗,轻松拆洗空调过滤器,让你清凉一夏!
- 谁知道家用空调滤网如何清洗?简单操作易懂的。
- 空调滤芯该如何清洗
- 空调过滤网要怎么清洗?
- 空调滤网清洗小妙招
- 如何拆洗空调过滤网
- 如何清洗空调过滤网丨无锡中央空调
- 华凌空调滤网深度清洁教程,轻松拆卸与清洗,享受清新空气体验
热点动态分享
- 2798
- 2674
- 2492
- 2329
- 2186
- 1824
- 1649
- 1495
- 1379
- 1309

