机器学习基础(二)——概率论与数理统计
统计学基础:理解概率和数据可视化 #生活技巧# #工作学习技巧# #数字技能训练#
转载仅供个人回顾高数及数理统计知识。
原文出处:https://blog.csdn.net/zuoyonggang123/article/details/79110916
1 基本概念
概率论在机器学习中扮演着一个核心角色,因为机器学习算法的设计通常依赖于对数据的概率假设。
1.1 概率空间说到概率,通常是指一个具有不确定性的event发生的可能性。例如,下周二下雨的概率。因此,为了正式地讨论概率论,我们首先要明确什么是可能事件。
正规说来,一个probability space是由三元组(Ω,F,P)定义:
- Ω为样本空间
- F⊆2Ω(Ω的幂集)为(可度量的)事件空间
- P为将事件E∈F映射到0~1真值区间的概率度量(概率分布),可以将P看作概率函数
注: Ω的幂集2Ω——是Ω的所有子集的集合,符号:P(Ω):={U|U⊆Ω},|Ω|=n个元素,|P(Ω)|=2n个元素。
假设给定样本空间Ω,则对于事件空间F来说:
- F包含Ω本身和∅
- F对于并集闭合,例如:如果α,β∈F,则α∪β∈F
- F对于补集闭合,例如:如果α∈F,则(Ω∖α)∈F
Example1: 假如我们投掷一个(6面)骰子,那么可能的样本空间Ω={1,2,3,4,5,6}。我们可能感兴趣的事件是骰子点数是奇数还是偶数,那么这种情况下事件空间就是F={∅,{1,3,5},{2,4,6}}.
可以看到样本空间Ω为有限集时,就像上一个例子,我们通常令事件空间F为2Ω。这种策略并不完全通用,但是在实际使用中通常是有效的。然而,当样本空间为无限集时,我们需要仔细定义事件空间。
给定一个事件空间F,概率函数P需要满足几个公理:
- (非负)对于所有α∈F,P(α)≥0
- P(F)=1,事件空间的概率值为1
- (互斥事件的加法法则)对于所有α,β∈F和α∩β=∅,P(α∪β)=P(α)+P(β)
Example2: 回到掷骰子的例子,假设事件空间F为2Ω ,进一步地,定义F上的概率函数P为:
P({1})=P({2})=…=P({6})=16
那么这种概率分布P可以完整定义任意给出事件的发生概率(通过可加性公理)。例如,投掷点数为偶数的概率为:
P({2,4,6})=P({2})+P({4})+P({6})=16+16+16=12
因为任意事件(此处指样本空间内的投掷出各点数)之间都没有交集
随机变量在概率论中扮演着一个重要角色。最重要的一个事实是,随机变量并不是变量,它们实际上是将(样本空间中的)结果映射到真值的函数。我们通常用一个大写字母来表示随机变量。
Example3: 还是以掷骰子为例。 另X为取决于投掷结果的随机变量。X的一个自然选择是将i映射到值i,例如,将事件“投掷1点”映射到值1。我们也可以选择一些特别的映射,例如,我们有一个随机变量Y——将所有的结果映射到0,这就是一个很无聊的函数。或者随机变量Z——当i为奇数时,将结果i映射到2i;当i为偶数时,将结果i映射到i。
从某种意义上说,随机变量让我们可以将事件空间的形式概念抽象出来,通过定义随机变量来采集相关事件。举个例子,考虑Example1中投掷点数为奇/偶的事件空间。我们其实可以定义一个随机变量,当结果i为奇数时取值为1,否则随机变量取值为0。这种二元算计变量在实际中非常常见,通常以指示变量为人所知,它是因用于指示某一特定事件是否发生而得名。所以为什么我们要引进事件空间?就是因为当一个人在学习概率论(更严格来说)通过计量理论来学习时,样本空间和事件空间的区别非常重要。这个话题对于这个简短的复习来说太前沿了,因此不会涉及。不管怎样,最好记住事件空间并不总是简单的样本空间的幂集。
继续,我们后面主要会讨论关于随机变量的概率。虽然某些概率概念在不使用随机变量的情况下也能准确定义,但是随机变量让我们能提供一种对于概率论的更加统一的处理方式。取值为a的随机变量X的概率可以记为:
P(X=a)或PX(a)
同时,我们将随机变量X的取值范围记为:Val(X)
我们经常会谈论变量的分布。正式来说,它是指一个随机变量取某一特定值的概率,例如:
Example4:假设在投掷一个骰子的样本空间Ω上定义一个随机变量X,如果骰子是均匀的,则X的分布为:
PX(1)=PX(2)=…=PX(6)=16
注意,尽管这个例子和Example2类似,但是它们有着不同的语义。Example2中定义的概率分布是对于事件而言,而这个例子中是随机变量的概率分布。
我们用P(X)来表示随机变量X的概率分布。
有时候,我们会同时讨论大于一个变量的概率分布,这种概率分布称为联合分布,因为此事的概率是由所涉及到的所有变量共同决定的。这个可以用一个例子来阐明。
Example5:在投掷一个骰子的样本空间上定义一个随机变量X。定义一个指示变量Y,当抛硬币结果为正面朝上时取1,反面朝上时取0。假设骰子和硬币都是均匀的,则X和Y的联合分布如下:
像前面一样,我们可以用P(X=a,Y=b)或PX,Y(a,b)来表示X取值为a且Y取值为b时的概率。用P(X,Y)来表示它们的联合分布。
假定有一个随机变量X和Y的联合分布,我们就能讨论X或Y的边缘分布。边缘分布是指一个随机变量对于其自身的概率分布。为了得到一个随机变量的边缘分布,我们将该分布中的所有其它变量相加,准确来说,就是:
P(X)=∑b∈Val(Y)P(X,Y=b)……………………………………(1)
之所以取名为边缘分布,是因为如果我们将一个联合分布的一列(或一行)的输入相加,将结果写在它的最后(也就是边缘),那么该结果就是这个随机变量取该值时的概率。当然,这种思路仅在联合分布涉及两个变量时有帮助。
条件分布为概率论中用于探讨不确定性的关键工具之一。它明确了在另一随机变量已知的情况下(或者更通俗来说,当已知某事件为真时)的某一随机变量的分布。
正式地,给定Y=b时,X=a的条件概率定义为:
P(X=a|Y=b)=P(X=a,Y=b)P(Y=b)…………………………………(2)
注意,当Y=b的概率为0时,上式不成立。
Example6:假设我们已知一个骰子投出的点数为奇数,想要知道投出的点数为“1”的概率。令X为代表点数的随机变量,Y为指示变量,当点数为奇数时取值为1,那么我们期望的概率可以写为:
P(X=1|Y=1)=P(X=1,Y=1)P(Y=1)=1612=13
条件概率的思想可以自然地扩展到一个随机变量的分布是以多个变量为条件时,即:
P(X=a|Y=b,Z=c)=P(X=a,Y=b,Z=c)P(Y=b,Z=c)
我们用P(X|Y=b)来表示当Y=b时随机变量X的分布,也可以用P(X|Y)来表示X的一系列分布,其中每一个都对应不同的Y可以取的值。
(https://zh.wikipedia.org/wiki/%E7%8B%AC%E7%AB%8B_(%E6%A6%82%E7%8E%87%E8%AE%BA))
在概率论中,独立性是指随机变量的分布不因知道其它随机变量的值而改变。在机器学习中,我们通常都会对数据做这样的假设。例如,我们会假设训练样本是从某一底层空间独立提取;并且假设样例i的标签独立于样例j(i≠j)的特性。
从数学角度来说,随机变量X独立于Y,当:
P(X)=P(X|Y)
(注意,上式没有标明X,Y的取值,也就是说该公式对任意X,Y可能的取值均成立。)
利用等式(2),很容易可以证明如果X对Y独立,那么Y也独立于X。当X和Y相互独立时,记为X⊥Y。
对于随机变量X和Y的独立性,有一个等价的数学公式:
P(X,Y)=P(X)P(Y)
我们有时也会讨论条件独立,就是当我们当我们知道一个随机变量(或者更一般地,一组随机变量)的值时,那么其它随机变量之间相互独立。正式地,我们说“给定Z,X和Y条件独立”,如果:
P(X|Z)=P(X|Y,Z)
或者等价的:
P(X,Y|Z)=P(X|Z)P(Y|Z)
机器学习(Andrew Ng)的课中会有一个朴素贝叶斯假设就是条件独立的一个例子。该学习算法对内容做出假设,用来分辨电子邮件是否为垃圾邮件。假设无论邮件是否为垃圾邮件,单词x出现在邮件中的概率条件独立于单词y。很明显这个假设不是不失一般性的,因为某些单词几乎总是同时出现。然而,最终结果是,这个简单的假设对结果的影响并不大,且无论如何都可以让我们快速判别垃圾邮件。
我们现在给出两个与联合分布和条件分布相关的,基础但是重要的可操作定理。第一个叫做链式法则,它可以看做等式(2)对于多变量的一般形式。
定理1(链式法则):
P(X1,X2,…,Xn)=P(X1)P(X2|X1)…P(Xn|X1,X2,…,Xn−1)…………(3)
链式法则通常用于计算多个随机变量的联合概率,特别是在变量之间相互为(条件)独立时会非常有用。注意,在使用链式法则时,我们可以选择展开随机变量的顺序;选择正确的顺序通常可以让概率的计算变得更加简单。
第二个要介绍的是贝叶斯定理。利用贝叶斯定理,我们可以通过条件概率P(Y|X)计算出P(X|Y),从某种意义上说,就是“交换”条件。它也可以通过等式(2)推导出。
定理2(贝叶斯定理):
(https://zh.wikipedia.org/wiki/%E8%B4%9D%E5%8F%B6%E6%96%AF%E5%AE%9A%E7%90%86)
P(X|Y)=P(Y|X)P(X)P(Y)………………………………(4)
记得,如果P(Y)没有给出,我们可以用等式(1)找到它:
P(Y)=∑a∈Val(X)P(X=a,Y)=∑a∈Val(X)P(Y|X=a)P(X=a)
这种等式(1)的应用有时也被称为全概率公式(https://zh.wikipedia.org/wiki/%E5%85%A8%E6%A6%82%E7%8E%87%E5%85%AC%E5%BC%8F)。
贝叶斯定理可以推广到多个随机变量的情况。在有疑问的时候,我们都可以参考条件概率的定义方式,弄清楚其细节。
Example7:考虑以下的条件概率:P(X,Y|Z)和(X|Y,Z)
P(X,Y|Z)=P(Z|X,Y)P(X,Y)P(Z)=P(Y,Z|X)P(X)P(Z)
P(X|Y,Z)=P(Y|X,Z)P(X,Z)P(Y,Z)=P(Y|X,Z)P(X|Z)P(Z)P(Y|Z)P(Z)=P(Y|X,Z)P(X|Z)P(Y|Z)
2 定义一个概率分布
前面已经讨论了一下概率分布,但是我们如何定义一个分布呢?广义上来说,有两种类型的分布,它们看似需要进行两种不同的处理(它们可以用度量学来进行统一)。也就是说,离散分布和连续分布。我们后面会讨论如何定义分布。
注意,以下的讨论和我们怎样能有效表示一个分布是截然不同的。有效表示概率分布的课题实际上是一个非常重要且活跃的研究领域,它值得开一个专门的课程。(CS228: Probabilistic Models in Artificial Intelligence)
(https://zh.wikipedia.org/wiki/%E6%A6%82%E7%8E%87%E8%B4%A8%E9%87%8F%E5%87%BD%E6%95%B0)
就一个离散分布而言,我们是指这种基本分布的随机变量只能取有限多个不同的值(或者样本空间有限)。
在定义一个离散分布时,我们可以简单地列举出随机变量取每一个可能值的概率。这种列举方式称为概率质量函数(probability mass function[PMF]),因为它将(总概率的)每一个单元块分开,并将它们和随机变量可以取的不同值对应起来。这个可以类似的扩展到联合分布和条件分布。
(https://zh.wikipedia.org/wiki/%E6%A9%9F%E7%8E%87%E5%AF%86%E5%BA%A6%E5%87%BD%E6%95%B8)
对连续分布而言,我们是指这种基本分布的随机变量能取无限多个不同值(或者说样本空间是无限的)。
连续分布相比离散分布来说是一种更加需要揣摩的情况,因为如果我们将每一个值取非零质量数,那么总质量相加就会是一个无限值,这样就不符合总概率相加等于1的要求。
在定义一个连续分布时,我们会使用概率密度函数(probability density function[PDF])。概率密度函数f是一个非负,可积(分)的函数,类似于:
∫Val(X)f(x)dx=1
符合PDFf的随机变量X的概率分布可以用如下公式计算:
P(a≤X≤b)=∫baf(x)dx
注意,特别地,默认连续分布的随机变量取任意单一值的概率为零。
Example8:(均匀分布)假设随机变量X在[0,1]上均匀分布,则对应的PDF为:
f(x)={10if 0≤x≤1otherwise
我们可以确定∫101dx为1,因此f为PDF。计算X的概率小于1/2:
P(X≤12)=∫1201dx=[x]120=12
更一般地,假设X在[a,b]上均匀分布,那么PDF即为:
f(x)={1b−a0if a≤x≤botherwise
有时我们也会讨论累积分布函数,这种函数给出了随机变量在小于某一值的概率。累积分布函数F和基本概率密度函数f的关系如下:
F(b)=P(X≤b)=∫b−∞f(x)dx
因此,F(x)=∫f(x)dx(就不定积分而言)。
要将连续分布的定义扩展到联合分布,需要把概率密度函数扩展为多个参数,即:
P(a1≤X1≤b1,a2≤X2≤b2,…,an≤Xn≤bn)=∫b1a1∫b2a2…∫bnanf(x1,x2,…,xn)dx1dx2…dxn
将条件分布扩展到连续随机变量时,会遇到一个问题——连续随机变量在单个值上的概率为0,因此等式(2)不成立,因为分母等于0。为了定义连续变量的条件分布,要令f(x,y)为X和Y的联合分布。通过分析,我们能看到基于分布P(Y|X)的PDF f(y|x)为:
f(y|x)=f(x,y)f(x)
即如果直接用P的话,P可能在分母为零,所以用f,通过f积分间接得到P。
例如:
P(a≤Y≤b|X=c)=∫baf(y|c)dy=∫baf(c,y)f(c)dy
3 期望(Expectations)和方差(Variance)
3.1 期望(https://zh.wikipedia.org/wiki/%E6%9C%9F%E6%9C%9B%E5%80%BC)
我们对随机变量做的最常见的操作之一就是计算它的期望,也就是它的平均值(mean),期望值(expected value),或一阶矩(first moment)。随机变量的期望记为E(x),计算公式:
E(x)=∑a∈Val(x)aP(X=a)或E(x)=∫a∈Val(x)xf(x)dx……………………(5)
Example9:令X为投掷一个均匀骰子的结果,则X的期望为:
E(X)=(1)16+(2)16+…+(6)16=312
有时我们可能会对计算随机变量X的某一函数f的期望值感兴趣,再次重申,随机变量本身也是一个函数,因此最简单的考虑方法是定义一个新的随机变量Y=f(X),然后计算Y的期望。
当使用指示变量时,一个有用的判别方式是:
E(X)=P(X=1) X为指示变量
此处可以脑补X还有一个取值为0,即E(x)=1×P(X=1)+0×P(X=0)=P(X=1)
当遇到随机变量的和时,一个最重要的规则之一是线性期望(linearity of expectations)。
定理3(线性期望):令X1,X2,…,Xn为(可能是独立的)随机变量:
E(X1+X2+…+Xn)=E(X1)+E(X2)+…+E(Xn)………………(6)
期望为线性函数。
期望的线性非常强大,因为它对于变量是否独立没有限制。当我们对随机变量的结果进行处理时,通常没什么可说的,但是,当随机变量相互独立时,有:
定理4:令X和Y为相互独立的随机变量,则:
E(XY)=E(X)E(Y)
3.2 方差(https://zh.wikipedia.org/wiki/%E6%96%B9%E5%B7%AE)
一个随机变量的方差描述的是它的离散程度,也就是该变量离其期望值的距离。一个实随机变量的方差也称为它的二阶矩或二阶中心动差,恰巧也是它的二阶累积量。方差的算术平方根称为该随机变量的标准差。
方差的定义:
Var(X)=E((X−E(X))2)………………………………(7)
随机变量的方差通常记为σ2,给它取平方的原因是因为我们通常想要找到σ,也就是标准差。方差和标准差(很明显)可以用公式σ=Var(X)−−−−−−√相关联。
为了找到随机变量X的方差,通常用以下替代公式更简单:
Var(X)=E(X2)−(E(X))2
注意,不同于期望,方差不是关于随机变量X的线性函数,事实上,我们可以证明(aX+b)的方差为:
Var(aX+b)=a2Var(X)
如果随机变量X和Y相互独立,那么:
Var(X+Y)=Var(X)Var(Y),如果X⊥Y
有时我们也会讨论两个随机变量的协方差,它可以用来度量两个随机变量的相关性,定义如下:
Cov(X,Y)=E((X−E(X))(Y−E(Y)))
4 一些重要的分布
以下包含一些课中会提到的概率分布,但是并不是我们所需要了解的全部概率分布,特别是几何分布、超几何分布、二项分布等,这些都是在各自的领域十分有用,并且在基础概率论中有研究到的,没有在此提及。
4.1 伯努利(Bernoulli)分布伯努利分布是最基础的概率分布之一,一个服从伯努利分布的随机变量有两种取值{0,1} ,它能通过一个变量p来表示其概率,为了方便,我们令P(X=1)为p。它通常用于预测试验是否成功。
有时将一个服从伯努利分布的变量X的概率分布按如下表示会很有用:
P(X)=px(1−p)1−x
一个伯努利分布起作用的例子是Lecture Notes1中的分类任务。为了给这个任务开发一个逻辑回归算法,对于特征来说,我们假设标签遵循伯努利概率分布。
(https://zh.wikipedia.org/wiki/%E6%B3%8A%E6%9D%BE%E5%88%86%E4%BD%88)
泊松分布是一种非常有用的概率分布,通常用于处理事件发生次数的概率分布。在给定一个事件发生的固定平均概率,并且在该段事件内事件发生相互独立时,它可以用来度量单位时间内事件发生的次数。它包含一个参数——平均事件发生率λ。泊松分布的概率质量函数为:
P(X=k)=exp(−λ)λkk!
服从泊松分布的随机变量的平均值为λ,其方差也为λ,E(X)=V(X)=λ
高斯分布,也就是正态分布,是概率论中最“通用”的概率分布之一,并且在很多环境中都有出现。例如,在试验数量很大时用在二项分布的近似处理中,或者在平均事件发生率很高时用于泊松分布。它还和大数定理相关。对于很多问题来说,我们还会经常假设系统中的噪声服从高斯分布。基于高斯分布的应用很多很多。 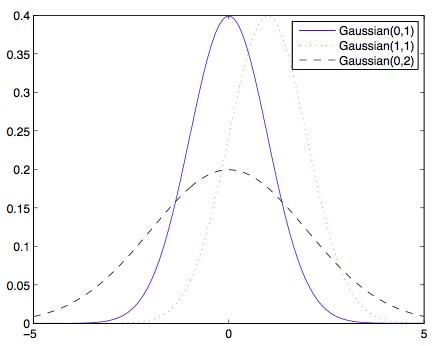
上图为不同期望和方差下的高斯分布。
高斯分布由两个参数决定:期望μ和方差σ2。其概率密度函数为:
f(x)=12π−−√σexp(−(x−μ)22σ2)………………(8)
为了更好的感受概率分布随着期望和方差的改变,在上图中绘制了三种不同的高斯分布。
在这个课中,我们会经常和多变量高斯分布打交道。一个k维多变量高斯分布用参数(μ,∑)表示,其中,μ为Rk上的期望矢量,∑为Rk×k上的协方差矩阵,也就是说,∑ii=Var(Xi)且∑ij=Cov(Xi,Xj)。其概率密度函数由输入的矢量定义:
f(x)=12πk|∑|−−−−−−√exp(−12(x−μ)T∑−1(x−μ))………………(9)
(我们标记矩阵A的行列式为|A|,其转置为A−1)
处理多变量高斯分布有时可能会比较困难,令人生畏。让我们生活更简单的一个方法,至少是让我们有对于某个问题的直觉的一个方法,是在我们刚开始试图解决一个问题时假设协方差为零。当协方差为零时,行列式|∑|就仅由变量生成,可以对∑对角线元素做转置来得到它的转置∑−1。
5 概率处理
因为接下来会有很多对概率和分布的处理,所以下面列出一些用于有效处理概率分布的tips。
5.1 The log trick在机器学习中,我们通常会假设不同样本之间相互独立。因此,我们常常需要对一定数量(大量)的概率分布的产物进行处理。当我们的目标为优化这些产物的函数时,如果我们先处理这些函数的对数通常会更加简单。因为取对数的函数是一个严格单增函数,因此它不会改变最大值的取值点(尽管更加明确来说,这个函数在取对数前后的最大值是不同的)。
举例来说,在Lecture Note 1,第17页的似然函数:
L(θ)=∏i=1m(hθ(x(i)))y(i)(1−hθ(x(i)))1−y(i)
我敢说这是一个看起来相当吓人的函数,但是通过对它取对数,相应的我们可以得到:
l(θ)=logL(θ)=∑i=1my(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))
现在它不是世界上最漂亮的函数,但至少更加易处理。我们现在可以一次处理一项(即一个训练样本),因为它们是相加而不是相乘。
因为概率相加要等于一,我们常常要进行归一化处理,特别是对连续概率分布来说。例如,对于高斯分布来说, 指数外面的项就是为了确保PDF的积分等于1。当我们确定某些代数的最终结果为一个概率分布,或者在寻找某些最优分布时,将归一化常数记为Z通常会更加简单,而不用一直考虑计算出归一化常数。
5.3 Jenson不等式有时我们会计算一个函数对某个随机变量的期望,通常我们只需要一个区间而不是具体的某个值。在这种情况下,如果该函数是凸函数或者凹函数,通过Jenson不等式,我们可以通过计算随机变量自身期望处的函数值来获得一个区间。 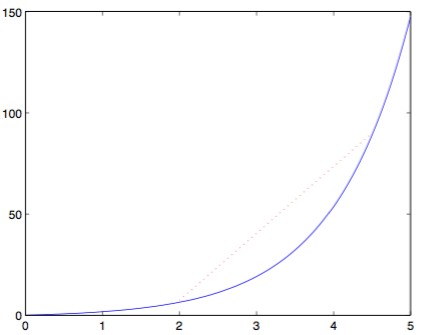
(上图为Jenson不等式图示)
定理5 (Jenson不等式):令X为一个随机变量,f为凸函数,那么:
f(E(X))≤E(f(X))
如果f为凹函数,那么:
f(E(X))≥E(f(X))
尽管我们可以用代数表示Jenson不等式,但是通过一张图更容易理解。上图中的函数为一个凹函数,我们可以看到该函数任意两点之间的直线都在函数的上方,也就是说,如果一个随机变量只能取两个值,那么Jenson不等式成立。这个也可以比较直接地推广到一般随机变量。
网址:机器学习基础(二)——概率论与数理统计 https://www.yuejiaxmz.com/news/view/536601
相关内容
心理压力管理的理论基础一学习研究.ppt基于大数据的学习资源推荐系统的设计与实现(论文+源码)
计算机应用基础
机器学习——线性回归基础
博弈论+机器学习=?
小白也能轻松学的计算机网络零基础入门(附学习路线 + 计算机网络教程)
python+flask计算机毕业设计基于的二手图书交易系统设计与实现(程序+开题+论文)
基于知识图谱的个性化学习资源推荐系统的设计与实现(论文+源码)
毕业设计:基于机器学习的生活垃圾智能分类系统
学习网络基础知识的方法
随便看看
最新动态分享
- 家里旧物如何处理,分分钟把它变成宝
- 清理垃圾最强软件APP推荐
- 免费清理软件大全
- 2024年最新:彻底清理垃圾软件的5个超级有效步骤!
- 快速清理电脑垃圾用什么命令,设计百科 winvk.com
- 清垃圾软件有哪些 可以清理垃圾的软件排行榜
- 电脑用什么软件清除垃圾比较快
- 电脑清理工具推荐:让你的设备时刻保持最佳状态
- 手机用久了内存不足还卡顿?教您清理这3个软件,瞬间清理出20个G!
- 手机万能清理软件大全
热点动态分享
- 2773
- 2657
- 2369
- 2297
- 2164
- 1805
- 1642
- 1491
- 1361
- 1304

