数分笔记整理11
利用数字化工具整理笔记 #生活技巧# #学习技巧# #知识整理技巧#
数据处理
数据加载
首先,我们需要将收集的数据加载到内存中,才能进行进一步的操作。pandas提供了非常多的读取数据的函数,分别应用在各种数据源环境中,我们常用的函数为:
read_csvread_tableread_sql说明:
read_csv与read_table默认使用的分隔符不同。 常用参数read_csv与read_table常用的参数:
sep / delimiterheadernamesindex_colusecolsimport numpy as np import pandas as pd 12
# 读取数据,并返回DataFrame类型的对象来存储数据。 # 在读取数据时,默认会将最开始的行视为标题行,如果数据没有标题行,则可以设置 # header=None。 # data = pd.read_csv("spider.csv", header=None) # data.head() # sep 指定分隔符,默认使用逗号(,)来分隔。 # data = pd.read_csv("spider.csv", header=None, sep=",") # 我们可以通过columns属性来设置列标题(列标签)。 # data.columns = ["A", "B", "C", "D", "E"] # 我们也可以通过names参数来设置列标题。 #data = pd.read_csv("spider.csv", header=None, names=["date", "url", "content", "data1", "data2"]) # index_col 设置作为索引的列。当我们要读取的数据集中,已经有一(多)列可以作为该条记录的唯一标识,例如,数据库表中的 # 主键,则我们就可以拿该列充当索引列,而无需再生成从0开始,增量为1的索引。 #data = pd.read_csv("spider.csv", header=None, index_col=0) # usecols 用来指定显示哪些列。当我们读取一个数据集时,数据集中可能存在很多列,而未必所有列都是我们需要的。 # 此时,我们就可以通过usecols参数来指定我们需要哪些列。 # data = pd.read_csv("spider.csv", header=None, usecols=[0, 1, 2]) # data = pd.read_csv("spider.csv", header=None, names=["date", "url", "content", "data1", "data2"], usecols=["date", "url"]) # data.head() # read_table与read_csv功能相同,不同之处仅在于,read_csv以逗号(,)作为分隔符。 # read_table以制表符(\t)作为分隔符。
12345678910111213141516171819202122import sqlite3 1
# 连接参数指定的数据库,如果数据库不存在,则创建数据库,并返回数据库连接(对象)。 # 如果数据库已经存在,则不再创建,而是直接返回数据库连接对象。 connect = sqlite3.connect("test.db") # execute方法可以用来执行sql语句。 # connect.execute("create table person(id int primary key, name varchar(20), age int)") # 向person表中插入数据(记录) 1234567
# connect.execute("insert into person(id, name, age) values(3, 'kkk', 15)") # 提交,更新操作。 connect.commit() 123
pd.read_sql("select id, name, age from person", connect) 1
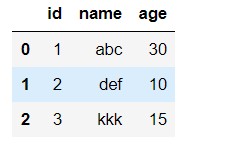
DataFrame与Series对象的to_csv方法:
to_csv该方法可以将数据写入:
文件中数据流中 常用参数 sepheader 是否写入标题行na_rep 空值的表示index 是否写入索引index_label 索引字段的名称columns 写入的字段df = pd.DataFrame([[1, 2, 3], [4, 5, np.NaN]]) display(df) # df.to_csv("data.csv") # sep 设置写入数据的分隔符。默认为逗号(,) # df.to_csv("data.csv", sep=";") # header 是否写入标题行,默认为True。 # df.to_csv("data.csv", header=False # na_rep 设置空值显示的内容,默认空值不显示。 # df.to_csv("data.csv", na_rep="空值") # 设置是否显示行索引,默认为True。 # df.to_csv("data.csv", index=False) # index_label设置行索引的名称,默认为空。 # df.to_csv("data.csv", index_label="行索引的名称") # columns 设置写入的列。 # df.to_csv("data.csv", columns=[0, 1]) 123456789101112131415

# 类文件对象:像文件一样,具有read, write, seek tell等方法功能的对象。 from io import StringIO 12
# 创建类文件对象。 sio = StringIO() # 向类文件对象中写入数据。 df.to_csv(sio) # 注意,在写入完成后,文件指针指向最后一个写入内容的下一个位置。如果此时对文件进行读取, # 则无法读取任何内容。如果需要读取内容,可以将文件指针移动到最开头的位置。 # sio.seek(0) # sio.read() # 获取缓存区中的数据内容,与文件指针无关。 sio.getvalue() 12345678910
网址:数分笔记整理11 https://www.yuejiaxmz.com/news/view/536845
相关内容
js数据操作笔记整理《两性勾搭指南》笔记整理分享,一起了解心里思维
怦然心动的人生整理魔法笔记+日常整理记录(多图)
《365天子弹笔记》:每天365秒,用笔记整理你的时间与心情
数字图像处理笔记一
笔记本怎么清理cmos
数字生活:10万字纯文字笔记如何整理?这是我的心得
高效能笔记法
【笔记本触摸屏】实用技巧整理
日日抚慰:改变人生的心灵整理术的笔记(14)
随便看看
最新动态分享
- 阳台绿化植物要如何养护?
- 求份园林绿化养护方案?麻烦具体说说
- 室内绿化植物的养护与管理(苍松参考)
- 加强秋季园林养护 助力绿植安全过冬
- 家居绿化养护链家居间协议.docx
- 专业绿植植物租赁租摆、绿化养护景观设计开业花篮配送
- 广州绿植物租摆 花卉租赁 植物摆放 园林绿化施工养护价格
- 道路绿化养护技术与高耐候植物选育
- 盐城大丰:秋季绿化养护忙 城市颜值再提升
- 广州专业植物租摆
热点动态分享
- 2773
- 2657
- 2371
- 2297
- 2164
- 1805
- 1642
- 1491
- 1361
- 1304

