深度学习常见的优化方法(Optimizer)总结:Adam,SGD,Momentum,AdaGard等
使用Adam优化器结合学习率衰减策略(如Step Decay)可以改善模型训练效果 #生活技巧# #学习技巧# #深度学习技巧#
机器学习的常见优化方法在最近的学习中经常遇到,但是还是不够精通.将自己的学习记录下来,以备不时之需
基础知识:机器学习几乎所有的算法都要利用损失函数 lossfunction 来检验算法模型的优劣,同时利用损失函数来提升算法模型.
这个提升的过程就叫做优化(Optimizer)
下面这个内容主要就是介绍可以用来优化损失函数的常用方法
常用的优化方法(Optimizer): 1.SGD&BGD&Mini-BGD:SGD(stochastic gradient descent):随机梯度下降,算法在每读入一个数据都会立刻计算loss function的梯度来update参数.假设loss function为L(w),下同.w−=η▽wiL(wi)" role="presentation">w−=η▽wiL(wi)
Pros:收敛的速度快;可以实现在线更新;能够跳出局部最优
Cons:很容易陷入到局部最优,困在马鞍点.
BGD(batch gradient descent):批量梯度下降,算法在读取整个数据集后累加来计算损失函数的的梯度
w−=η▽wL(w)" role="presentation">w−=η▽wL(w)
Pros:如果loss function为convex,则基本可以找到全局最优解
Cons:数据处理量大,导致梯度下降慢;不能实时增加实例,在线更新;训练占内存
Mini-BGD(mini-batch gradient descent):顾名思义,选择小批量数据进行梯度下降,这是一个折中的方法.采用训练集的子集(mini-batch)来计算loss function的梯度.w−=η▽wi:i+nL(wi:i+n)" role="presentation">w−=η▽wi:i+nL(wi:i+n)
这个优化方法用的也是比较多的,计算效率高而且收敛稳定,是现在深度学习的主流方法.
上面的方法都存在一个问题,就是update更新的方向完全依赖于计算出来的梯度.很容易陷入局部最优的马鞍点.能不能改变其走向,又保证原来的梯度方向.就像向量变换一样,我们模拟物理中物体流动的动量概念(惯性).引入Momentum的概念. 2.Momentum在更新方向的时候保留之前的方向,增加稳定性而且还有摆脱局部最优的能力Δw=αΔw−η▽L(w)" role="presentation">Δw=αΔw−η▽L(w) w=w+Δw" role="presentation">w=w+Δw
若当前梯度的方向与历史梯度一致(表明当前样本不太可能为异常点),则会增强这个方向的梯度,若当前梯度与历史梯方向不一致,则梯度会衰减。一种形象的解释是:我们把一个球推下山,球在下坡时积聚动量,在途中变得越来越快,η" role="presentation">η可视为空气阻力,若球的方向发生变化,则动量会衰减。
3.Adagrad:(adaptive gradient)自适应梯度算法,是一种改进的随机梯度下降算法.以前的算法中,每一个参数都使用相同的学习率α" role="presentation">α. Adagrad算法能够在训练中自动对learning_rate进行调整,出现频率较低参数采用较大的α" role="presentation">α更新.出现频率较高的参数采用较小的α" role="presentation">α更新.根据描述这个优化方法很适合处理稀疏数据.$$G=\sum ^{t}{\tau=1}g g_{\tau}^{T} 其中 s.t. g_{\tau}=\bigtriangledown L(w_{i})对角线矩阵" role="presentation">对角线矩阵G_{j,j}=\sum {\tau=1}^{t} g^{2}这个对角线矩阵的元素代表的是参数的出现频率.每个参数的更新" role="presentation">这个对角线矩阵的元素代表的是参数的出现频率.每个参数的更新w_{j}=w_{j}-\frac{\eta}{\sqrt{G_{j,j}}}g_{j}$$ 4.RMSprop:(root mean square propagation)也是一种自适应学习率方法.不同之处在于,Adagrad会累加之前所有的梯度平方,RMProp仅仅是计算对应的平均值.可以缓解Adagrad算法学习率下降较快的问题.v(w,t)=γv(w,t−1)+(1−γ)(▽L(wi))2,其中γ是遗忘因子" role="presentation">v(w,t)=γv(w,t−1)+(1−γ)(▽L(wi))2,其中γ是遗忘因子 参数更新w=w−ηv(w,t)▽L(wi)" role="presentation">w=w−ηv(w,t)▽L(wi) 5.Adam:(adaptive moment estimation)是对RMSProp优化器的更新.利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率.
优点:每一次迭代学习率都有一个明确的范围,使得参数变化很平稳.
mwt+1=β1mwt+(1−β1)▽Lt,m为一阶矩估计" role="presentation">mwt+1=β1mwt+(1−β1)▽Lt,m为一阶矩估计
vwt+1=β2mwt+(1−β2)(▽Lt)2,v为二阶矩估计" role="presentation">vwt+1=β2mwt+(1−β2)(▽Lt)2,v为二阶矩估计
m^w=mwt+11−β1t+1,估计校正,实现无偏估计" role="presentation">m^w=mwt+11−β1t+1,估计校正,实现无偏估计
v^w=vwt+11−β2t+1" role="presentation">v^w=vwt+11−β2t+1
wt+1←=wt−ηm^wv^w+ϵ" role="presentation">wt+1←=wt−ηm^wv^w+ϵ
Adam是实际学习中最常用的算法
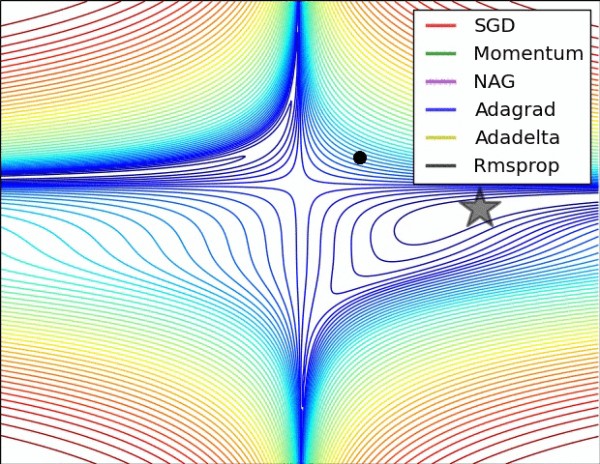
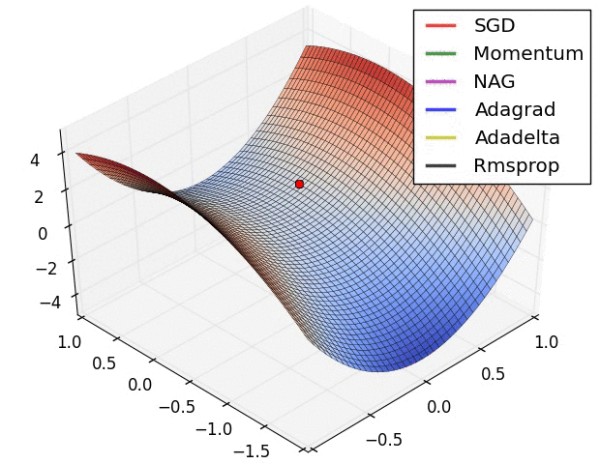
网址:深度学习常见的优化方法(Optimizer)总结:Adam,SGD,Momentum,AdaGard等 https://www.yuejiaxmz.com/news/view/574198
相关内容
Tensorflow 中优化器optimizer参数 adam认识深度学习
深度学习入门(四):与学习相关的技巧
深度学习中的优化问题(Optimization)
深度學習
最强总结!神经网络中常用的九种优化技术(一)特征缩放、批量标准化、梯度下降、基于动量的梯度下降(非常详细)大模型入门到精通!
【深度学习】深度学习语音识别算法的详细解析
深度学习模型的24种优化策略
常见的几种最优化方法(梯度下降法、牛顿法、拟牛顿法、共轭梯度法等)
使用Python实现深度学习模型:智能家电控制与优化
随便看看
最新动态分享
- 书改变了我的生活作文700字
- 思维教育创新:笃定前行:读书,改写人生的密钥 在人生的广袤征途上,“读书改变人生”这一观点犹如一座屹立不倒的灯塔,为无数人照亮了前行的道路。然而,对于这一观点,社会上却也不乏质疑之声,有人认为读书不过是纸上谈兵,无法切实改变人生轨迹。但在我看来,读书,无疑是改变人生最为有力的杠杆,它蕴含着扭转乾坤的巨大能量。 回溯历史的长河,无数仁人志士用他们的亲身经历为“读书改变人生”写下了生动注脚。匡...
- 琼瑶名著电影精选 长情万缕 2VCD电影 林青霞
- 上海调节池清理 生化池清掏 泵站清淤沉淀池淤泥干湿分离环保处理
- 旧书回收二手书回收
- 二手书,旧书,古旧书回收 上海上门回收旧书
- 武汉二手图书回收
- 周口二手图书回收
- 开封二手图书回收
- 宜昌二手图书回收
热点动态分享
- 136649
- 40106
- 36360
- 23857
- 23810
- 23792
- 21462
- 15668
- 14990
- 14980

