智能推荐算法演变及学习笔记(一):智能推荐算法综述
购物体验智能化,推荐算法让商品推荐更加精准 #生活知识# #生活感悟# #科技生活变迁# #人工智能普及#
目录
一、基于内容的智能推荐:最古老的智能推荐方案!1. 定义2. 主要步骤3. 优缺点二、基于协同过滤的智能推荐:最流行的智能推荐方案!1. 基于内存的协同过滤方法2. 基于模型的协同过滤方法:最主流的智能推荐方案! 三、混合推荐1. 从推荐结果的角度2. 从特征的角度3. 从算法的角度4. 从系统的角度 四、智能推荐系统可能存在的问题1. 冷启动问题2. 数据稀疏性问题3. 马太/长尾效应4. 模糊问题5. 同义问题6. 稳定性/可塑性问题7. 多样性/精确性问题 五、智能推荐的企业级应用1. 采用召回候选集+业务规则过滤+模型打分排序的智能推荐系统思路2. 采用分支型混合推荐应对不同的业务场景3. 评估指标【说在前面】本人博客新手一枚,象牙塔的老白,职业场的小白。以下内容仅为个人见解,欢迎批评指正,不喜勿喷![握手][握手]
一、基于内容的智能推荐:最古老的智能推荐方案!
1. 定义
根据用户历史喜欢的item,为用户推荐与其内容相似的item。
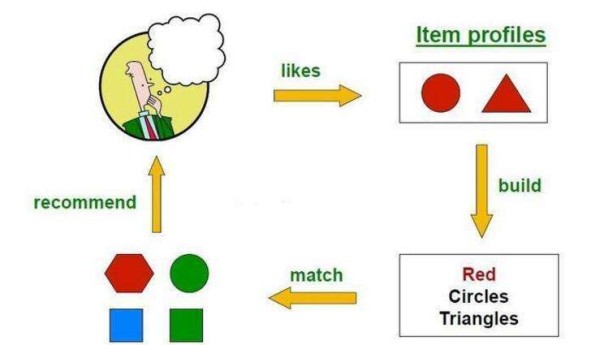
2. 主要步骤
(1)从用户每个历史item的内容中抽取出一些特征 结构化数据:直接用即可 非结构化数据:转化为结构化数据后再使用(例如:针对文本数据的向量空间模型、TF-IDF等) (2)利用用户历史喜欢或不喜欢的item特征集合,学习出用户的兴趣特征表示 可以直接选择item的相似度衡量方法:欧几里得距离(适用于结构化数据)、余弦相似性(适用于非结构化数据转化后的向量表示)等 可以采用机器学习算法进行有监督训练:线性回归、最近邻、朴素贝叶斯、决策树、神经网络等 (3)比较用户的兴趣特征与候选item的特征,选择相关性前Top-n的item进行推荐 如果2中直接采用相似度衡量方法:只要把与用户兴趣特征最相关的n个item作为推荐返回给用户即可 如果2中采用机器学习算法:只要把模型预测的用户最可能感兴趣的n个item作为推荐返回给用户即可3. 优缺点
(1)优点 不需要其它用户的数据,没有物品冷启动问题和数据稀疏问题 能推荐新的或不是很流行的项目,没有新项目问题 能为具有特殊兴趣爱好的用户进行推荐 可以通过推荐项目的内容特征,解释其推荐理由 (2)缺点 存在用户冷启动问题 对item内容的特征抽取并不容易实现 将各用户独立,只能推荐用户历史感兴趣的item,用户的潜在喜好无法挖掘二、基于协同过滤的智能推荐:最流行的智能推荐方案!
1. 基于内存的协同过滤方法
(1)基于用户的推荐:主要考虑用户之间的相似度,将相似用户评分Top-n的物品推荐给用户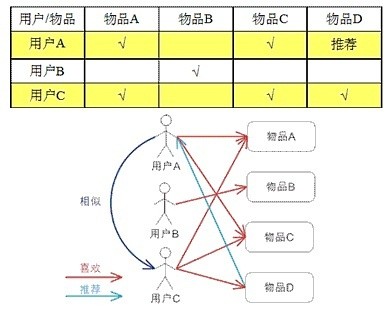

和基于内容的推荐方法相比,该协同过滤具有如下的优点:
能够过滤难以进行机器自动内容分析的信息,如艺术品、音乐等 能够共享其他用户的经验,避免了内容分析的不完全和不精确 能够有效使用其他相似用户的反馈信息,加快个性化学习的速度 具有推荐新信息的能力,可以发现用户潜在的但自己尚未发现的兴趣偏好但该协同过滤仍有许多的问题需要解决:
存在冷启动问题和数据稀疏问题 商品、用户越多,协同过滤越复杂,可扩展问题 不能为具有特殊兴趣爱好的用户进行推荐(找不到相似用户)2. 基于模型的协同过滤方法:最主流的智能推荐方案!
(1)基于关联规则的推荐:主要方法是从 Apriori 和 FP-Growth 两个算法发展演变而来(计算复杂度过大)
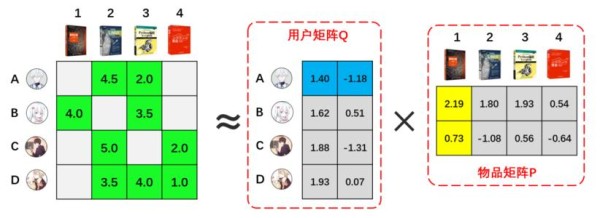 (3)基于隐语义模型的推荐:主要方法包括隐性语义分析LSA和隐含狄利克雷分布LDA等。(主要是基于用户的nlp语义分析进行相关推荐)
(3)基于隐语义模型的推荐:主要方法包括隐性语义分析LSA和隐含狄利克雷分布LDA等。(主要是基于用户的nlp语义分析进行相关推荐) 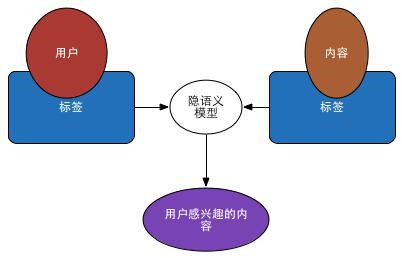
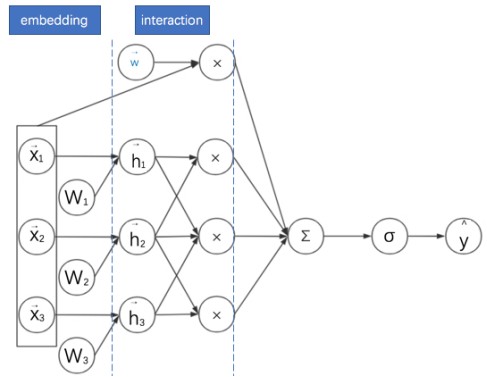
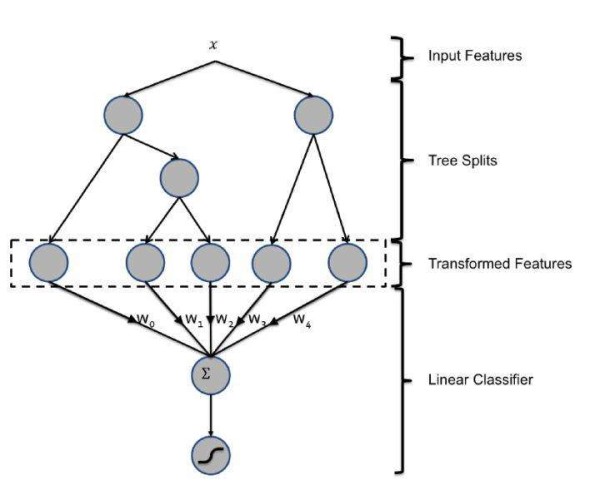
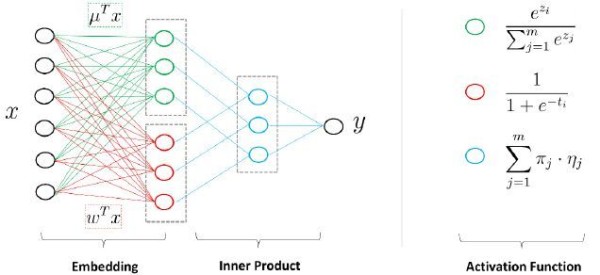
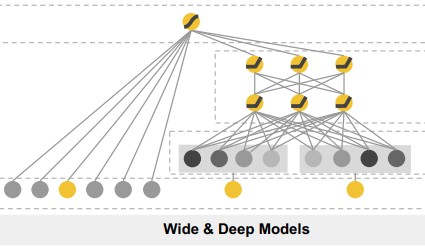
双塔模型DSSM:两侧分别对{用户,上下文} 和 {物品} 进行建模
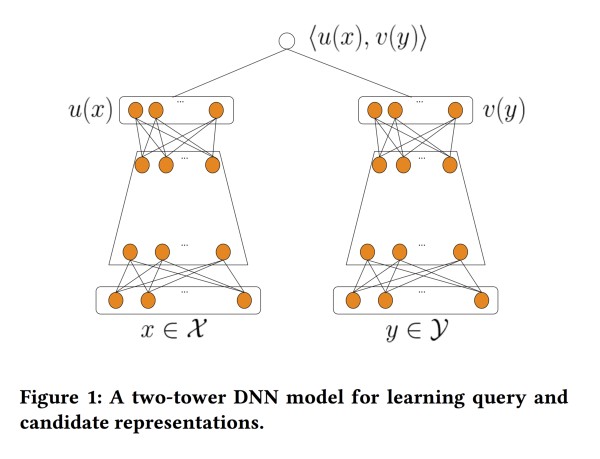



【更新】为了具体介绍,博主更新了两篇新随笔:
CTR预估模型演变及学习笔记 基于图模型的智能推荐算法学习笔记(含知识图谱/图神经网络,不止于智能推荐)【更新】介绍比较新的一些深度学习推荐模型改进方向:
引入用户行为序列建模(例如TDM/TransRec等) 将用户历史行为看做一个无序集合,对所有embedding取sum、max和各种attention等 将用户历史行为看做一个时间序列,采用RNN/LSTN/GRU等建模 抽取/聚类出用户的多峰兴趣,方法有Capsule等(阿里MIND提出) 根据业务场景的特殊需求,采用其他方法 引入NLP领域知识建模(例如Transformer/BERT等) 多目标优化/多任务学习(例如阿里ESMM/Google MMoE等) 多模态信息融合 长期/短期兴趣分离(例如SDM等) 结合深度强化学习(例如YouTube推荐/今日头条广告推荐DEAR等) 图神经网络的预训练(即引入迁移学习的思路) ......三、混合推荐
1. 从推荐结果的角度
加权型混合推荐:指将多种推荐技术的计算结果加权混合产生推荐 分支型混合推荐:指根据问题背景和实际情况采用不同的推荐方法 混杂型混合推荐:指采用多种推荐技术给出的推荐结果,即取并集2. 从特征的角度
特征组合:指组合来自不同推荐数据源的特征被另一种推荐算法所采用 特征扩充:指一种技术产生附加的特征信息嵌入到另一种推荐技术的特征输入中3. 从算法的角度
增强型混合推荐:指前一个推荐方法的输出作为后一个推荐方法的输入 层叠型混合推荐:指第一推荐方法输出粗略的推荐列表,该推荐列表又由下一推荐方法改进4. 从系统的角度
离线学习和在线学习:hadoop/storm/spark等大数据环境下的智能推荐 满足业务上的一些需求:加入人工规则等四、智能推荐系统可能存在的问题
1. 冷启动问题
主要包含新用户启动问题、新物品启动问题和新系统启动问题 可以采用热门物品推荐、根据地域推荐、让用户选择兴趣标签、根据好友推荐、利用交叉领域信息等方法2. 数据稀疏性问题
可以采用简单填值、用户/物品聚类、矩阵分解、降维、混合推荐等方法3. 马太/长尾效应
指的是存在热门物品越来越受关注、其他物品越来越得不到关注的问题 可以采用混合推荐等方法4. 模糊问题
指的是用户的兴趣爱好不太明显、比较散乱(例如一家人用同一个智能电视) 可以采用混合推荐等方法5. 同义问题
指的是存在推荐相关性过大、甚至推荐重复的物品给用户(例如一个物品的不同版本) 可以采用混合推荐等方法6. 稳定性/可塑性问题
指的是用户兴趣会慢慢改变、而推荐系统仍然保留用户的历史兴趣 可以对用户的兴趣物品进行时间衰减操作7. 多样性/精确性问题
可以采用混合推荐等方法五、智能推荐的企业级应用
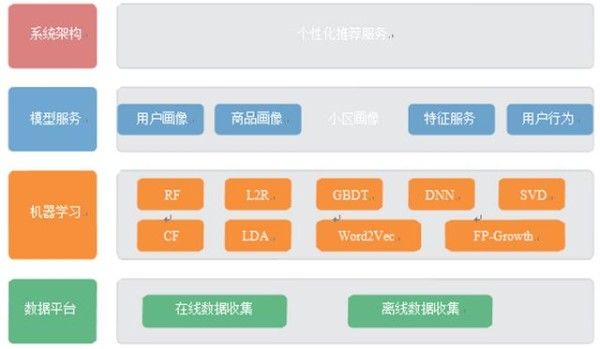
1. 采用召回候选集+业务规则过滤+模型打分排序的智能推荐系统思路
(1)召回(matching):一般包括召回和粗排两个部分。粗排部分负责将各路召回的内容进行统一的排序,取出top的内容送入到排序模块中。粗排一般使用一些不那么复杂的模型,例如gbdt、lr、fm等。
(2)排序(ranking):一般包括精排和重排等部分。精排部分主要涉及到的技术为点击率预估(CTR预估),使用point-wise的方法对<user,item,context>三元组打出一个分,然后进行排序。
两者的主要差别为:Deepmatch中没有目标物料的概念,而排序中可以使用目标物料,同时也可以基于目标物料做一些交叉特征。
* 建议可以好好学习一下Google 16年发表的 《Deep Neural Networks for YouTube Recommendations》框架,辅助理解。

2. 采用分支型混合推荐应对不同的业务场景
3. 评估指标
个人理解企业级的上线问题以及评估指标,应该与数据挖掘类似,这里不再赘述。
一是离线算法本身的评估指标:分类问题评估指标和回归问题评估指标等 二是业务上线的评估指标:例如点击率、转化率等老规矩,最后直接上完整的思维导图!
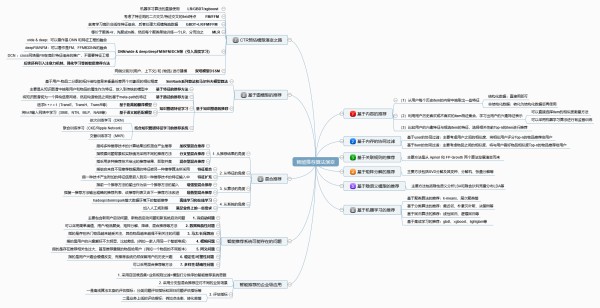
如果您对数据挖掘感兴趣,欢迎浏览我的另一篇博客:数据挖掘比赛/项目全流程介绍
如果您对人工智能算法感兴趣,欢迎浏览我的另一篇博客:人工智能新手入门学习路线和学习资源合集(含AI综述/python/机器学习/深度学习/tensorflow)
如果你是计算机专业的应届毕业生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的应届生,你如何准备求职面试?
如果你是计算机专业的本科生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的本科生,你可以选择学习什么?
如果你是计算机专业的研究生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的研究生,你可以选择学习什么?
如果你对金融科技感兴趣,欢迎浏览我的另一篇博客:如果你想了解金融科技,不妨先了解金融科技有哪些可能?
之后博主将持续分享各大算法的学习思路和学习笔记:hello world: 我的博客写作思路
网址:智能推荐算法演变及学习笔记(一):智能推荐算法综述 https://www.yuejiaxmz.com/news/view/578357
相关内容
推荐算法综述智能购物推荐算法研发.doc
揭秘AutoML:智能推荐算法如何改变你的生活?
ChatGPT:个性化广告推荐的智能算法
个性化推荐算法概述与展望
国内外推荐算法研究述评
个性化推荐算法综述(历史学毕业论文).doc
无限轮播的个性化推荐算法.pptx
揭秘家庭生活,智能推荐算法如何精准打造个性化体验
揭秘推荐算法:从演变到影响生活的关键变革
随便看看
最新动态分享
- 将清洁任务融入繁忙的日程中
- “宿舍劳动谁出马,干净卫生靠大家”——北大经院宿舍卫生评比结果出炉!
- 关于我的周末生活英语作文(精选38篇)
- 老师,您如何平衡工作与生活?| 每周一问
- 找时间写作:在繁忙的日程中写作的 3 种万无一失的方法
- 大扫除 | 广东人“年二十八,洗邋遢”
- 美国 70 家顶级清洁公司
- 在繁忙的日程中,叶舒华与宋雨琦的坚韧人生
- 洁癖spickandspan指南:如何在繁忙生活中保持整洁周全
- 家中忙碌童未扫落花?如何保持清洁与美观
热点动态分享
- 2773
- 2657
- 2372
- 2299
- 2164
- 1805
- 1642
- 1491
- 1361
- 1304

