【移动端深度学习模型优化】:量化技巧揭秘,提升速度与减小体积
深度学习模型训练的优化方法:批量归一化可以提升模型性能 #生活技巧# #学习技巧# #深度学习技巧#
目录
摘要 关键字 1. 深度学习模型优化概述 2. 深度学习模型量化理论基础 2.1 量化的基本概念与原理 2.1.1 精度与精度损失的理解 2.1.2 量化对模型性能的影响 2.2 量化方法分类与比较 2.2.1 权重量化与激活量化的差异 2.2.2 后训练量化与量化感知训练 2.3 量化模型的数学基础 2.3.1 整数线性代数与定点表示 2.3.2 量化误差的数学模型 3. 深度学习模型量化实践技巧 3.1 量化工具与框架 3.1.1 量化工具介绍与选择 3.1.2 框架支持与环境搭建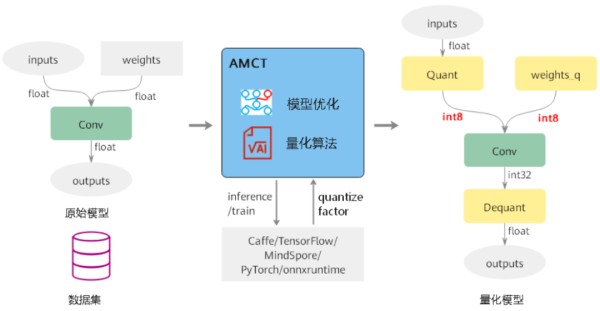
摘要
深度学习模型优化是提升模型性能和效率的重要途径,其中量化作为关键技术,涉及降低模型参数的精度以缩减计算资源和提高执行速度。本文首先概述了深度学习模型优化的基本概念与原理,随后深入探讨了不同量化方法的分类及其对模型性能的影响,并讨论了量化模型的数学基础。在此基础上,本文提供了一系列量化实践技巧,并通过实战案例分析展示了量化技术在实际应用中的效果。此外,本文还评估了量化模型的速度、体积、能耗和适用性,并探讨了深度学习模型优化的未来发展方向,包括量化技术趋势和硬件协同进化。最后,本文分享了多个深度学习模型优化的实战案例,涵盖跨平台应用和特定行业模型优化的实际应用场景。
关键字
深度学习;模型优化;量化;数学基础;性能评估;未来方向
参考资源链接:移动端深度学习框架对比:NCNN vs MNN
1. 深度学习模型优化概述
在当今这个人工智能飞速发展的时代,深度学习模型优化已经成为提升模型性能、扩展其应用范围的关键。模型优化涉及的范围广泛,包括但不限于模型结构设计、参数调整、加速计算以及资源分配等多个方面。而在这些方面中,模型量化因其能显著减少模型的存储大小和计算需求,成为了一项重要的优化技术。
量化技术的核心思想是将模型中的浮点数参数(如32位浮点数)转化为低比特数(如8位整数)的表示形式,这样做不仅减少了模型的内存占用和带宽需求,还有助于提高模型在特定硬件上的运行效率。然而,量化过程并非没有代价,它可能会导致模型精度的下降,因此,在实际应用中如何平衡模型性能和精度损失,实现高效准确的模型量化,是当前深度学习社区面临的重要挑战。
本文将从量化理论基础讲起,逐步深入探讨量化实践技巧,并通过实际案例分析,探索量化在不同场景下的应用与效果评估。通过对深度学习模型优化的全面剖析,旨在为读者提供深度学习模型优化的知识地图,并揭示未来优化技术的发展趋势。
2. 深度学习模型量化理论基础
2.1 量化的基本概念与原理
量化是将深度学习模型的参数和激活从浮点数(如32位浮点数)转换为低精度数值(如8位整数)的过程。这一过程能显著减少模型的大小和提高执行速度,但前提是必须确保这种精度的降低不会对模型的性能造成过度的损害。
2.1.1 精度与精度损失的理解在量化过程中,模型精度损失是不可避免的。但理解精度损失的影响是优化模型性能的关键。精度损失通常与量化位宽(即数值表示所需的位数)有关。例如,量化至8位整数的模型比32位浮点数的模型有更低的精度,因此会有精度损失。然而,通过采用适当的量化策略,可以最大限度地减小这种损失,同时利用低精度模型带来的好处。
2.1.2 量化对模型性能的影响量化对模型性能的影响主要体现在模型精度和速度上。量化可以显著减少模型存储和内存占用,降低内存带宽需求,从而加快模型推理速度。在某些情况下,量化甚至可以提高模型的泛化能力,尤其是在数据较少时。但在其他情况下,过度量化可能会影响模型性能,特别是在模型的原始精度较高的情况下。因此,量化过程需要权衡性能与精度之间的关系。
2.2 量化方法分类与比较
量化方法的分类涉及到权重和激活量化的不同方式,以及训练过程中量化感知的策略。
2.2.1 权重量化与激活量化的差异权重量化和激活量化是深度学习模型量化过程中的两种不同的应用。权重量化是指将模型权重从高精度格式转换为低精度格式,而激活量化则是对层间激活值进行同样的处理。两者的差异在于量化过程中考虑的误差来源不同。权重量化的主要误差来源是参数的近似,而激活量化则还需考虑到动态范围的估计误差。一般情况下,激活量化对于存储和计算的节省贡献更大,但同时可能会引入更大的量化误差。
2.2.2 后训练量化与量化感知训练后训练量化(Post-Training Quantization,PTQ)和量化感知训练(Quantization-Aware Training,QAT)是目前两种主流的量化策略。PTQ是在模型训练完成后进行的量化,对原模型的结构和参数不作改变,操作简单。而QAT是在训练阶段就模拟量化过程,通过引入量化误差来优化模型参数,从而降低量化的精度损失。QAT通常能够达到更好的性能,但计算成本也更高。
2.3 量化模型的数学基础
量化模型的数学基础涉及整数线性代数和定点表示,以及量化误差的数学模型。
2.3.1 整数线性代数与定点表示整数线性代数是一种利用整数进行线性运算的数学方法,广泛应用于量化模型中。在量化过程中,传统的浮点运算被转换为整数运算,这需要将浮点数映射到一个固定的整数范围,并在该范围内执行所有运算。这种映射称为定点表示,它简化了计算复杂度,减少了资源消耗,使得模型更适合在资源受限的平台上部署。
2.3.2 量化误差的数学模型量化误差主要来源于数值表示的有限精度。在量化模型中,连续的浮点数值被离散的整数所取代,这个离散化的过程导致了量化的精度损失。量化误差的数学模型需要对这种误差的大小进行分析和评估。通常,量化误差可以被建模为随机变量,其数学期望接近于零,而方差则与量化位宽相关。理解并建模量化误差对于量化过程的优化至关重要,它可以帮助我们预测和控制量化的性能影响。
3. 深度学习模型量化实践技巧
3.1 量化工具与框架
在深度学习模型优化的过程中,量化工具和框架的选择是至关重要的第一步。不同工具和框架有着各自的特点和优势,能够帮助开发者更好地实现模型的量化。
3.1.1 量化工具介绍与选择
量化工具的多样性使得开发者能够根据不同的需求和环境进行选择。一些主流的量化工具包括:
TensorRT:NVIDIA推出的深度学习推理加速器,它支持层融合和内核自动调优,是优化深度学习模型的强有力工具。 TensorFlow Lite:专为移动和嵌入式设备设计的轻量级解决方案,提供了多种模型优化工具。 PyTorch Quantization:作为PyTorch的一个模块,提供了多种量化方法,易于集成和使用。选择合适的量化工具时,开发者需要考虑以下几个因素:
目标硬件平台:不同的量化工具针对不同的硬件进行了优化,选择与目标硬件兼容的工具能够获得更好的性能。 模型大小和复杂度:某些工具对大型模型的优化效果更显著,而有些则更适合于轻量级模型。 社区支持和文档:一个活跃的社区和详尽的文档可以大大降低开发者的使用难度。 支持的量化类型:不同的工具支持不同类型的量化,例如,有的支持对权重和激活的对称量化,而有的支持非对称量化。3.1.2 框架支持与环境搭建
在选择量化工具后,需要搭建一个适合开发和测试的环境。这通常包括以下几个步骤:
安装依赖库:如CUDA、cuDNN等NVIDIA提供的库,以及对应深度学习框架的Python包。 设置开发环境:配置开发工具,如Jupyter Notebook或PyCharm,并设置好路径以便使用量化工具。 测试环境:对量化工具进行简单测试,确保量化流程能够顺畅运行。# 示例:安装TensorFlow Lite的Python依赖pip install tflite_support
安装完毕后,通过编写简单的代码进行验证:
import tflite_runtime.interpreter as tflite# 加载TFLite模型interpreter = tflite.Interpreter(model_path="model.tflite")interpreter.allocat
网址:【移动端深度学习模型优化】:量化技巧揭秘,提升速度与减小体积 https://www.yuejiaxmz.com/news/view/609895
相关内容
网络优化:提升速度与体验深度学习模型的24种优化策略
深度学习提升模型表现的技巧
深度学习模型中神经网络结构的优化策略
Dropout技术全面解析——深度学习中的泛化能力提升策略
网站制作中的前端资源懒加载优化:提升首屏加载速度
【科技前沿】用深度强化学习优化电网,让电力调度更聪明!
机器/深度学习模型最优化问题详解及优化算法汇总
深度学习中的优化问题(Optimization)
算法优化大揭秘:12个加速算法运行速度的实用技巧
随便看看
最新动态分享
- 书房装饰精美挂画,韵中生韵,香外生香
- 书房装饰挂画精选,书房里的“颜如玉”就是它
- 12号公馆装修全案:现代简约风格如何打造都市精英生活空间?
- 高清名人名言挂画定制指南客厅背景墙卧室装饰书房软装必备!精选50款经典语录设计要点与选购秘籍
- 楼梯装饰天花板!10句治愈系名人名言挂画推荐|客厅书房走廊必备家居灵感
- 均联智行赋力第三生活空间 智能化、网联化系统持续领航
- 智能电动车大比拼:问界M7与问界M5哪款更适合你?
- 空间智能化交互革命已来,华为发布全屋智能4.0
- 深蓝S7带来的超感智能化体验:“第三生活空间” 给消费者诸多期待
- 佛山诗尼曼全屋定制:高端家具定制专家,打造您的理想生活空间
热点动态分享
- 136562
- 39314
- 36291
- 23789
- 23595
- 23127
- 21410
- 15383
- 14970
- 14936

