数据分析
参加数据分析认证,如数据分析上岗证或数据分析师证书 #生活技巧# #工作学习技巧# #技能培训认证#
算法学习、4对1辅导、论文辅导、核心期刊
项目的代码和数据下载可以通过公众号滴滴我
项目介绍
在当今快节奏的生活中,早餐的选择变得至关重要。而肯德基(KFC)作为全球知名的快餐连锁品牌,其早餐系列丰富多样。想象一下,通过巧妙地爬取 KFC 早餐的相关信息,我们能够轻松地为自己搭配出一份营养均衡的早餐。
通过爬取到的丰富数据,通过多个因素可以分析出早餐主食的最多选择。
数据描述
数据共90行,共4个字段。分别是:name、foods、price、img_url。
以下是表的部分数据:

分析数据
1、导入库import pandas as pd import jieba import wordcloud import imageio from collections import Counter from pyecharts import options as opts from pyecharts.charts import Bar 1234567
导入数据,查看缺失值,异常值的处理
data = pd.read_csv('kfc.csv') data.head() 12

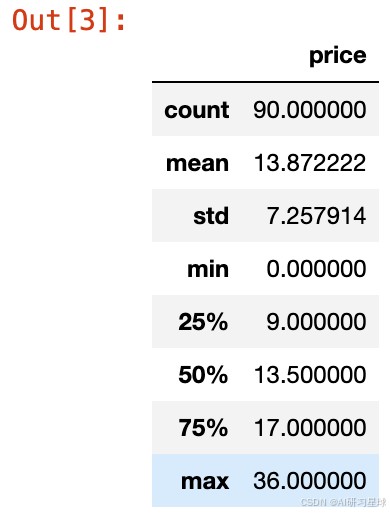
data.describe() 1
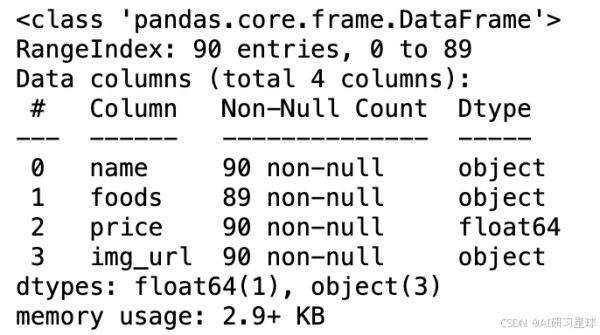
data.info() 1
价格为 0.0 的使用平均数填充
# 价格为 0.0 的使用平均数填充 def f(p): if p == 0.0: p = 14 return p else: return p data['price'] = data['price'].map(f) 12345678
删除缺失值的行
# 删除缺失值的行 data = data.dropna() 12
连接所有餐名,食物内容及通过jieba分词处理
# 连接所有餐名,食物内容 names = list(data['name']) foods = list(data['foods']) names.extend(foods) names = ' '.join(names) # 分词 ls = jieba.lcut(names) txt = ' '.join(ls) 123456789

# 清洗掉与食物无关的词语 txt = txt.replace('产品','').replace('包装','').replace('包装实物','')\ .replace('br','').replace('随心换','').replace('实物','')\ .replace('主要','').replace('原料','').replace('指比菜','')\ .replace('单单','').replace('加价','').replace('换购','')\ .replace('总价','').replace('金额','').replace('为准','')\ .replace('早餐','').replace('饮品','') 1234567 2、主食营养分配
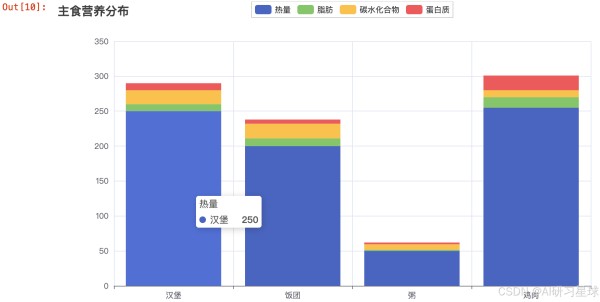
hamburger = { '热量' : 250, '脂肪' : 10, '碳水化合物' : 20, '蛋白质' : 10 } rice_ball = { '热量' : 200, '脂肪' : 11, '碳水化合物' : 21, '蛋白质' : 6 } porridge = { '热量' : 50, '脂肪' : 1.5, '碳水化合物' : 8, '蛋白质' : 2.5 } chicken = { '热量' : 255, '脂肪' : 15, '碳水化合物' : 10, '蛋白质' : 21 } 123456789101112131415161718192021222324
x = ['汉堡','饭团','粥','鸡肉'] y1 = [250,200,50,255] y2 = [10,11,1.5,15] y3 = [20,21,8,10] y4 = [10,6,2.5,21] c = Bar() c.add_xaxis(x) c.add_yaxis("热量", y1, stack="stack1") c.add_yaxis("脂肪", y2, stack="stack1") c.add_yaxis("碳水化合物", y3, stack="stack1") c.add_yaxis("蛋白质", y4, stack="stack1") c.set_series_opts(label_opts=opts.LabelOpts(is_show=False)) c.set_global_opts(title_opts=opts.TitleOpts(title="主食营养分布")) #c.render_notebook() c.render_notebook() 123456789101112131415
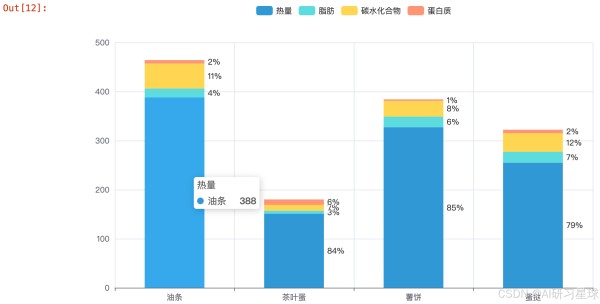
youtiao = { '热量' : 388, '脂肪' : 18, '碳水化合物' : 51, '蛋白质' : 7 } chayedan = { '热量' : 151, '脂肪' : 6, '碳水化合物' : 12, '蛋白质' : 11 } shubin = { '热量' : 327, '脂肪' : 22, '碳水化合物' : 32, '蛋白质' : 3 } danta = { '热量' : 255, '脂肪' : 22, '碳水化合物' : 38, '蛋白质' : 7 } 123456789101112131415161718192021222324
from pyecharts import options as opts from pyecharts.charts import Bar from pyecharts.commons.utils import JsCode from pyecharts.globals import ThemeType list2 = [ {"value": 388, "percent": 388 / (388 + 18 + 51 + 7)}, {"value": 151, "percent": 151 / (151 + 6 + 12 + 11)}, {"value": 327, "percent": 327 / (327 + 22 + 32 + 3)}, {"value": 255, "percent": 255 / (22 + 38 + + 7 + 255)}, ] list3 = [ {"value": 18, "percent": 18 / (388 + 18 + 51 + 7)}, {"value": 6, "percent": 6 / (151 + 6 + 12 + 11)}, {"value": 22, "percent": 22 / (327 + 22 + 32 + 3)}, {"value": 22, "percent": 22 / (22 + 38 + 7 + 255)}, ] list4 = [ {"value": 51, "percent": 51 / (388 + 18 + 51 + 7)}, {"value": 12, "percent": 12 / (151 + 6 + 12 + 11)}, {"value": 32, "percent": 32 / (327 + 22 + 32 + 3)}, {"value": 38, "percent": 38 / (22 + 38 + 7 + 255)}, ] list5 = [ {"value": 7, "percent": 7 / (388 + 18 + 51 + 7)}, {"value": 11, "percent": 11 / (151 + 6 + 12 + 11)}, {"value": 3, "percent": 3 / (327 + 22 + 32 + 3)}, {"value": 7, "percent": 7 / (22 + 38 + 7 + 255)}, ] c = Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT)) c.add_xaxis(['油条','茶叶蛋','薯饼','蛋挞']) c.add_yaxis("热量", list2, stack="stack1", category_gap="50%") c.add_yaxis("脂肪", list3, stack="stack1", category_gap="50%") c.add_yaxis("碳水化合物", list4, stack="stack1", category_gap="50%") c.add_yaxis("蛋白质", list5, stack="stack1", category_gap="50%") c.set_series_opts( label_opts=opts.LabelOpts( position="right", formatter=JsCode( "function(x){return Number(x.data.percent * 100).toFixed() + '%';}" ), ) ) c.render_notebook() 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748
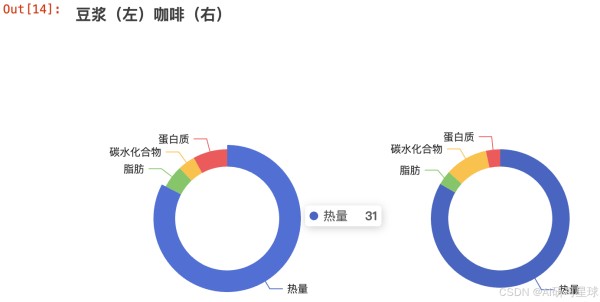
doujiang = { '热量' : 31, '脂肪' : 2, '碳水化合物' : 1.5, '蛋白质' : 3 } coffe = { '热量' : 100, '脂肪' : 4, '碳水化合物' : 12, '蛋白质' : 4 } 123456789101112
from pyecharts import options as opts from pyecharts.charts import Pie c = Pie() c.add( "", [list(z) for z in zip(["热量", "脂肪",'碳水化合物','蛋白质'], [31,2,1.5, 3])], center=["20%", "50%"], radius=[60, 80], ) c.add( "", [list(z) for z in zip(["热量", "脂肪",'碳水化合物','蛋白质'], [100,4,12, 4])], center=["55%", "50%"], radius=[60, 80], ) c.set_global_opts( title_opts=opts.TitleOpts(title="豆浆(左)咖啡(右)"), legend_opts=opts.LegendOpts( type_="scroll", pos_top="200%", pos_left="80%", orient="vertical" ), ) c.render_notebook() 1234567891011121314151617181920212223242526
网址:数据分析 https://www.yuejiaxmz.com/news/view/625399
相关内容
人人都是数据分析师:到底什么是数据分析?如何进行数据分析?【数据分析师
生存数据分析
2 数据分析EDA
睡眠数据分析:如何通过数据分析优化睡眠质量?
统计数据分析
Python数据分析:对饮食与健康数据的分析与可视化
商业数据分析从入门到入职(1)商业数据分析综述
生活中的数据分析案例,生活中数据分析应用案例
数据分析逻辑整理——餐厅数据
随便看看
最新动态分享
- 中电建物业西南区域低碳手工活动圆满举办
- 节能环保改造对创建绿色饭店的促进意义
- 2025年内蒙古实施农牧区危房改造5437户
- 巧手改造——绿洲社用创意让“废盒”焕新颜
- 酒店大扫除怎么过原神 《原神》酒店大扫除任务攻略
- 直击现场!商场、酒店、废品站这样开展爱国卫生运动
- 保洁,保洁公司,专业酒店保洁,大型开荒保洁,沙发地毯保养清洗,厂房地面保洁,擦玻璃,地铁站开荒保洁,深度精细铺商场学校医院保洁,别墅厂房店保洁
- 美食烹饪助手软件最新版下载
- 做菜好的APP推荐
- 做饭的工具有哪些APP推荐
热点动态分享
- 136497
- 38088
- 36268
- 23778
- 23354
- 22587
- 21381
- 15008
- 14958
- 14908

