BAKU:一种用于多任务策略学习的高效 Transformer
避免多任务处理,专注一个任务可以提高学习效率。 #生活技巧# #自我提升技巧# #学习效率提升策略#
24年6月来自纽约大学的论文“BAKU: An Efficient Transformer for Multi-Task Policy Learning”。
训练能够解决各种任务的通才智体是一项挑战,通常需要大量专家演示数据集。这在机器人技术中尤其成问题,因为每个数据点都需要在现实世界中实际执行动作。因此,迫切需要能够有效利用可用训练数据的架构。这项工作提出 BAKU,一种简单的 Transformer 架构,可以高效学习多任务机器人策略。BAKU 以离线模仿学习的最新进展为基础,精心结合观察主干、动作分块、多感官观察和动作头,大大改进以前的工作。在 LIBERO、Meta-World 套件和 Deepmind Control 套件中对 129 个模拟任务进行实验,与 RT-1 和 MT-ACT 相比,总体绝对改进 18%,与更难的 LIBERO 基准相比,改进 36%。在 30 个现实世界的操作任务中,平均每个任务只有 17 个演示,BAKU 的成功率达到 91%。
模仿学习 (IL) IL [23] 指的是智体从演示中学习,而无需获得环境奖励。IL 大致可分为行为克隆 (BC) [48, 68] 和逆强化学习 (IRL) [41, 1]。BC 仅从离线演示中学习,但在分布外(OOD)样本方面存在问题 [56],而 IRL 则专注于通过在线交互学习稳健的奖励函数,但存在样本效率低下的问题 [17, 18]。
近年来,随着使用 GMM [36, 39]、EBM [13]、BeT [60, 11, 31] 和扩散 [45, 10, 55, 7] 的多模态动作生成模型的发展,单任务行为克隆取得了重大进展。通过模仿学习解决长期任务方面也取得了显著进展,其中一些工作完全依赖于机器人数据 [38, 21, 9, 77, 33, 65],而另一些工作则试图从人类数据中引导学习 [72]。此外,这些策略学习方面的进步与自我监督表征学习的重大进步相结合 [8, 42, 20],使得这些策略能够在混乱和不可预测的环境中部署,例如家庭 [61],以及在野外进行零样本部署 [62, 64]。然而,尽管大量工作推动了单任务机器人策略学习,但策略学习的单任务和多任务性能之间仍然存在差距 [75, 44, 57]。
多任务学习机器人技术具有悠久的多任务学习历史。大量研究专注于机器人抓取的学习策略,旨在推广到 9 个新任务 [32, 47, 14, 71, 12]、机器人语言理解 [40, 35, 66, 3],并将多任务学习视为目标达成问题 [51, 28, 22]。此外,一些研究收集了各种多任务机器人数据集 [38, 34, 5, 43, 30]。最近,基于 Transformer 的架构在多任务机器人学习中的应用越来越多,涉及机器人导航 [62, 64]、运动 [27, 15, 49, 50] 和操控 [6, 78, 11, 5]。虽然这些研究大多数使用文本条件来指定任务,但有些研究超越了文本,还使用了目标图像 [11, 16] 和视频 [26, 25]。另一个新兴趋势是将这些机器人策略与其他任务(例如视觉问答和图像字幕 [52, 78])一起训练,以开发更具通用性的策略。总体而言,多任务学习已广泛应用于机器人技术,最近,使用高容量 Transformer 模型来学习机器人控制策略已成为该领域的常见做法。尽管这些策略很有效,但它们的架构往往很复杂,必要的组件有时不清楚。
多任务动作分块Transformer (MT-ACT) [5] 是一种用于学习多任务策略的最先进的Transformer编码器-解码器架构。MT-ACT 将ACT [77] 扩展到多任务设置。MT-ACT 将来自多个摄像机视图、机器人本体感受和任务指令的观察结果作为输入。每种输入模态都经过专用编码器。然后将编码的观察结果融合到Transformer编码器中,其输出调节Transformer解码器以预测未来动作块。每个预测动作对应于解码器的位置嵌入输入。在 ACT 和 MT-ACT 中,条件变分自动编码器 (CVAE) 用于学习多模态风格变量,该变量调节编码器以处理多模态动作分布。在推理过程中,风格变量设置为零,导致单模态行为。
RT-1 [6] 是一种基于 Transformer 的多任务策略学习架构,它通过将动作均匀地离散化为bins来将动作建模为离散类。RT-1 使用 FiLM 条件视觉编码器(在本文实现中为 ResNet-18),但它不是直接使用最终的 512 维表示,而是将大小为 k × k × 512 的中间特征图拆分为 k2 个 512 维的 token。这些 token 通过 Token Learner [58] 模块,以将它们减少到每幅图像 8 个 token。
多任务学习算法的设计涉及许多有关模型架构和组件选择的决策。这通常会导致架构复杂,其中各个组件的重要性有时不明确。对先前工作 [6, 5, 63] 提出的各种多任务学习架构进行系统而彻底的消融研究,并介绍一种用于多任务策略学习的简单架构 BAKU。为了便于分析,将整个模型架构分为三个主要组件:传感编码器、观察主干和动作头。传感编码器将来自不同模态的原始传感器输入处理成有用的特征表示。观察主干将来自不同模态的编码信息组合起来。最后,动作头利用组合信息来预测动作。
如图所示:(a) BAKU,是一种简单的 Transformer 架构,可学习各种任务的多任务策略;BAKU 使用特定于模态的编码器对来自不同模态的输入进行编码。编码后的表征在观察主干中合并,然后通过动作头预测动作。(b) 在 LIBERO-90 基准中为 90 项任务制定了统一的策略,讨论了影响多任务性能的设计选择。© 在 xArm 机器人上,BAKU 可以学习 30 项任务的单一多任务策略,平均每项任务收集 17 个演示。
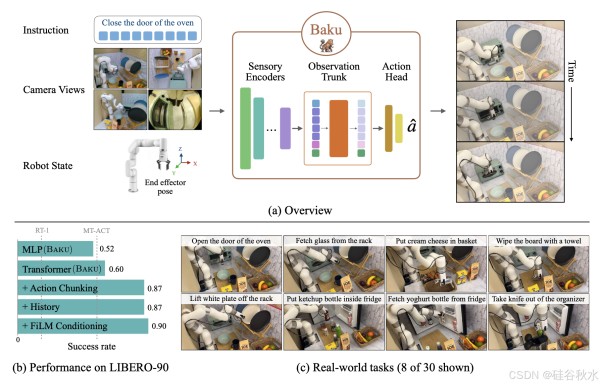
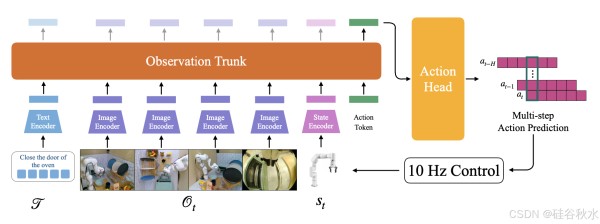
在 BAKU 中,专注于视觉、机器人本体感受以及基于文本或目标图像的任务指令。对于视觉,使用 ResNet-18 [19] 视觉编码器来处理场景图像,并使用 FiLM [46] 层进行增强,以整合特定于任务的信息。机器人本体感受数据通过两层多层感知 (MLP) 编码器进行处理。对于文本,用 Sentence Transformers [54] 中提供的 6 层 MiniLM [73]。通过额外的 MLP 层将从所有模态获得的表示投影到相同的维度,以便于组合编码信息。
所有感官模态的编码输入都组合在观察主干中。探索主干网络的两种变型: Transformer和MLP。
尝试了五种动作头变型:原始 MLP,高斯混合模型(GMM)[36],Behavior Transformer(BeT)[60],矢量量化 BeT(VQ-BeT)[31]和扩散策略[45,10,55]。
如图所示:通过大量实验,最终的架构包括一个经过修改的 FiLM 调节 ResNet-18 视觉编码器(随 LIBERO 基准 [34] 提供)、一个用于机器人本体感受的 MLP 编码器和一个用于任务指令的预训练文本编码器。对于具有多个摄像机视图的环境,在所有视图中使用通用视觉编码器。仅提供当前观察作为输入,观察主干使用因果Transformer解码器架构 [29]。模型的基础版使用具有动作分块和时间平滑的 MLP 动作头来产生更平滑的运动。还尝试动作头的多模态变型。传感编码器的参数数量约为 2.1M,观察主干的参数数量约为 6.5M,动作头的参数数量约为 1.4M,使总模型大小达到约 10M 个参数。
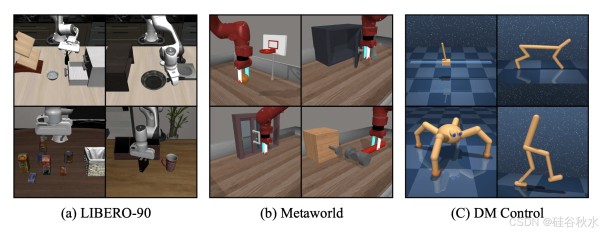
如图所示,BAKU 在 3 个模拟基准(LIBERO、Meta-World 和 DM Control)上进行评估:
如图所示现实世界的策略展开,展示了 BAKU 执行复杂操作任务的能力:

网址:BAKU:一种用于多任务策略学习的高效 Transformer https://www.yuejiaxmz.com/news/view/676669
相关内容
高效学习策略高效学习策略通用12篇
《高效率学习策略》课件
高效学习策略范文
高效的学习策略
八种科学高效学习策略,直接套用,简单高效!
高效学习法五种策略
如何利用学习策略提高学习效率
通用学习策略——高效记忆策略
6s高效学习策略:自我调节策略
随便看看
最新动态分享
- 从空间到生活方式,卡诺亚重塑品质家居体验
- 李晟携手顾家整家定制:以「十大微场景」开启家居设计新叙事
- 沃格定制美好家
- XIIF 禧梵高端定制:于山海间雕琢理想之居
- 私人定制文案55条
- 专业定制,品质保障,让您的家居生活更加完美
- 为生活做减法,致简致美
- 全屋定制产品
- 从门窗定制开始,为你的质感生活提案
- 《于贝尔·德·纪梵希:高级定制的生活》法语电影
热点动态分享
- 22721
- 13985
- 6209
- 6135
- 5071
- 4553
- 4139
- 4025
- 4002
- 3170

