头歌平台
在线K歌平台如全民K歌:分享你的歌声,或是发现别人的搞笑K歌视频 #生活乐趣# #日常生活趣事# #音乐欣赏的乐趣# #音乐趣事分享平台#
人工智能技术应用 基于 Jieba 的中文分词实战第1关:中文分词工具——Jieba第2关:基于 Jieba 的词频统计 词性标注第1关:词性标注 命名实体识别第1关:命名实体识别第2关:中文人名识别第3关:地名识别 LSA / LSI 算法第1关:学会使用 Gensim第2关:LSA / LSI 算法 博主说第1关:中文分词工具——Jieba
import jieba text = input() seg_list1 = '' seg_list2 = '' # 任务:采用jieba库函数,对text分别进行精确模式分词和搜索引擎模式分词, # 将分词结果分别保存到变量seg_list1和seg_list2中 # ********** Begin *********# seg_list1 = jieba.cut(text,cut_all=False) seg_list2 = jieba.cut_for_search(text) # ********** End **********# print("精确模式:"+'/'.join(seg_list1) +" 搜索引擎模式:"+ ' /'.join(seg_list2)) 12345678910111213141516
第2关:基于 Jieba 的词频统计
import jieba text= input() words = jieba.lcut(text) # 搜索引擎模式分词 data={} # 词典 # 任务:完成基于 Jieba 模块的词频统计 # ********** Begin *********# for chara in words: if len(chara) < 2: continue if chara in data: data[chara] += 1 # 再次出现则加 1 else: data[chara] = 1 # 首次出现则为 1 # ********** End **********# data = sorted(data.items(), key=lambda x: x[1], reverse=True) # 排序 print(data[:3],end="") 123456789101112131415161718192021222324
词性标注
第1关:词性标注
import jieba.posseg as psg text=input() #任务:使用jieba模块的函数对text完成词性标注并将结果存储到result变量中 # ********** Begin *********# words = list(psg.cut(text)) result = '' for word, flag in words: result += word + '/' + flag + ' ' # ********** End **********# print(result) 123456789101112131415
命名实体识别
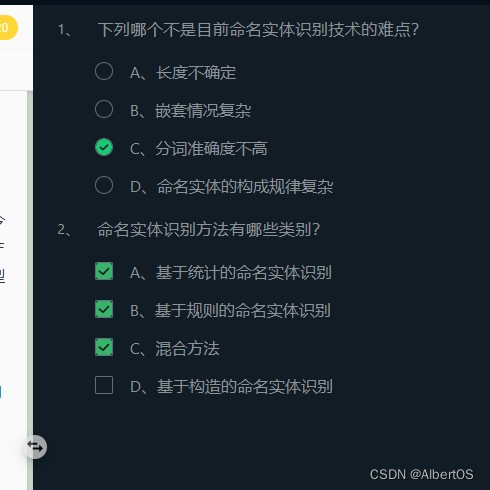
第1关:命名实体识别
第2关:中文人名识别
from pyhanlp import HanLP text =input() # 任务:完成对 text 文本的人名识别并输出结果 # ********** Begin *********# segment = HanLP.newSegment().enableNameRecognize(True); # 构建人名识别器 result = segment.seg(text) # 对text文本进行人名识别 print(result) # 输出结果 # ********** End **********# 123456789101112
第3关:地名识别
from pyhanlp import HanLP text =input() # 任务:完成对 text 文本的地名识别并输出结果 # ********** Begin *********# segment = HanLP.newSegment().enablePlaceRecognize(True); # 构建地名识别器 result = segment.seg(text) # 对text文本进行地名识别 print(result) # ********** End **********# 123456789101112
LSA / LSI 算法
第1关:学会使用 Gensim
from gensim import corpora, models import jieba.posseg as jp, jieba from basic import get_stopword_list texts=[] # 构建语料库 for i in range(5): s=input() texts.append(s) flags = ('n', 'nr', 'ns', 'nt', 'eng', 'v', 'd') # 词性 stopwords = get_stopword_list() words_ls = [] for text in texts: words = [word.word for word in jp.cut(text) if word.flag in flags and word.word not in stopwords] words_ls.append(words) # 去重,存到字典 dictionary = corpora.Dictionary(words_ls) corpus = [dictionary.doc2bow(words) for words in words_ls] # 任务:基于 gensim 的models构建一个lda模型,主题数为1个 # ********** Begin *********# lda = models.LdaModel(corpus,id2word=dictionary, num_topics=1) # ********** End **********# for topic in lda.print_topics(num_words=1): print(topic[1].split('*')[1],end="") 12345678910111213141516171819202122232425262728293031
注:这个LdaModel有可能超时,可以多等等再次重试
第2关:LSA / LSI 算法
from gensim import corpora, models import functools from others import seg_to_list,load_data,word_filter,cmp import math class TopicModel(object): # 三个传入参数:处理后的数据集,关键词数量,具体模型(LSI、LDA),主题数量 def __init__(self, doc_list, keyword_num, model='LSI', num_topics=4): # 使用gensim的接口,将文本转为向量化表示 # 先构建词空间 self.dictionary = corpora.Dictionary(doc_list) # 任务:使用BOW模型进行向量化,并保存到corpus变量中 # ********** Begin *********# corpus = [self.dictionary.doc2bow(words) for words in doc_list] # ********** End **********# # 对每个词,根据tf-idf进行加权,得到加权后的向量表示 self.tfidf_model = models.TfidfModel(corpus) self.corpus_tfidf = self.tfidf_model[corpus] self.keyword_num = keyword_num self.num_topics = num_topics # 选择加载的模型 if model == 'LSI': self.model = self.train_lsi() else: self.model = self.train_lda() # 得到数据集的主题-词分布 word_dic = self.word_dictionary(doc_list) self.wordtopic_dic = self.get_wordtopic(word_dic) def train_lsi(self): lsi = models.LsiModel(self.corpus_tfidf, id2word=self.dictionary, num_topics=self.num_topics) return lsi def train_lda(self): lda = models.LdaModel(self.corpus_tfidf, id2word=self.dictionary, num_topics=self.num_topics) return lda def get_wordtopic(self, word_dic): wordtopic_dic = {} for word in word_dic: single_list = [word] wordcorpus = self.tfidf_model[self.dictionary.doc2bow(single_list)] wordtopic = self.model[wordcorpus] wordtopic_dic[word] = wordtopic return wordtopic_dic # 计算词的分布和文档的分布的相似度,取相似度最高的keyword_num个词作为关键词 def get_simword(self, word_list): sentcorpus = self.tfidf_model[self.dictionary.doc2bow(word_list)] senttopic = self.model[sentcorpus] # 余弦相似度计算 def calsim(l1, l2): a, b, c = 0.0, 0.0, 0.0 for t1, t2 in zip(l1, l2): x1 = t1[1] x2 = t2[1] a += x1 * x1 b += x1 * x1 c += x2 * x2 sim = a / math.sqrt(b * c) if not (b * c) == 0.0 else 0.0 return sim # 计算输入文本和每个词的主题分布相似度 sim_dic = {} for k, v in self.wordtopic_dic.items(): if k not in word_list: continue sim = calsim(v, senttopic) sim_dic[k] = sim for k, v in sorted(sim_dic.items(), key=functools.cmp_to_key(cmp), reverse=True)[:self.keyword_num]: print(k + "/ ", end='') print() # 词空间构建方法和向量化方法,在没有gensim接口时的一般处理方法 def word_dictionary(self, doc_list): dictionary = [] for doc in doc_list: dictionary.extend(doc) dictionary = list(set(dictionary)) return dictionary def doc2bowvec(self, word_list): vec_list = [1 if word in word_list else 0 for word in self.dictionary] return vec_list def topic_extract(word_list, model, pos=False, keyword_num=10): doc_list = load_data(pos) topic_model = TopicModel(doc_list, keyword_num, model=model) topic_model.get_simword(word_list) if __name__ == '__main__': text = input() pos = True seg_list = seg_to_list(text, pos) filter_list = word_filter(seg_list, pos) topic_extract(filter_list, 'LSI', pos) 12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182838485868788899091
博主说
这个实验很简单真正要写的只有从begin到end中间的几个函数,看清楚流程做起来很简单的(python入门就是这么简单)
本科的人工智能技术就是一个笑话,算法也不会跟大家讲的很明白,全都是不断的调用库函数,做调参员;
真正的人工智能的岗位都是要去研究算法细节的,这个实验没有啥指导性的作用,只是让大家了解一下NLP领域的一些常用的算法库的使用,大家有兴趣可以深入学习一下。
网址:头歌平台 https://www.yuejiaxmz.com/news/view/726244
相关内容
四季沐歌电热水龙头安装方法 四季沐歌电热水龙头清洁保养苏轼水调歌头明月几时有赏析 水调歌头的鉴赏
木桥社区:歌声与智趣同台,生活缤纷多彩
量子之歌为中老年群体打造高质量学习平台,满足新老年学习需求
智能家居平台资讯
智能家居平台有哪些?智能家居平台上有什么产品?
量子之歌:以科技赋能银发生活,布局打造“线上+线下”融合服务平台
网络学习平台,在线学习平台哪个好?
衢州2台生活娱乐频道推荐10首热门歌曲
想要更好的 Spotify 听歌体验,你需要这份歌单「整理术」
随便看看
最新动态分享
- 阳台空间的几个巧妙利用
- 越来越多人阳台装个洗衣台,太机智了,看完立马回家做一个
- 还纠结“阳台封不封”?如今流行“半封阳台”,一半生活一半休闲
- 巧手改造,生活阳台变卫生间,空间利用新思路
- 厨房生活阳台巧利用,打造多功能空间新体验
- 河源「美的城」→售楼处电话→首页网站|河源美的城最新销售公告|在售户型丨周边配套介绍
- 越来越多人在阳台上装这个,水费能节省一大半,太聪明了!
- 成都中海云缦源境_楼盘详情_中海云缦源境_售楼处电话_网站首页
- 深圳女园艺师打造5.9㎡阳台果园圈粉10万!这些植物搭配技巧让你轻松拥有绿色天堂
- 67㎡温馨小家,装修成喜欢的样子,独居生活太舒服了!
热点动态分享
- 3161
- 2923
- 2921
- 2658
- 2502
- 1969
- 1694
- 1602
- 1585
- 1489

