
 Favourite流沙 于 2016-11-11 20:50:53 发布
Favourite流沙 于 2016-11-11 20:50:53 发布一、引言
如何在不泄露用户隐私的前提下,提高大数据的利用率,挖掘大数据的价值,是目前大数据研究领域的关键问题。具体而言,实施大数据环境下的隐私保护,需要在大数据产生的整个生命周期中考虑两个方面:如何从大数据中分析挖掘出更多 的价值;如何保证在大数据的分析使用过程中,用户的隐私不被泄露。本论文将围绕下图所示的大数据隐私保护生命周期模型展开。
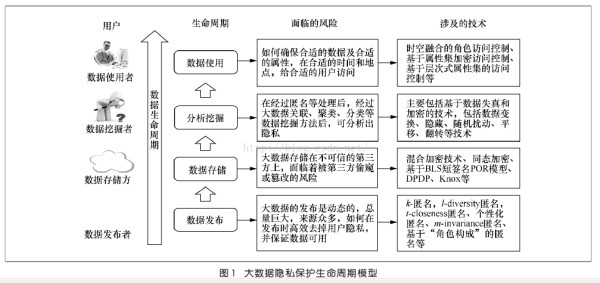
二、大数据生命周期的隐私保护模型
2.1 数据发布
与传统针对隐私保护进行的数据发布手段相比,大数据发布面临的风险是大数据的发布是动态的,且针对同一用户的数据来源众多,总量巨大。需要解决的问题是如果在数据发布时,保证用户数据可用的情况下,高效、可靠地去掉可能泄露用户隐私的内容。传统针对数据的匿名发布技术,包括k-匿名、l-diversity匿名、t-closeness匿名、个性化匿名、m-invariance匿名、基于“角色构成”的匿名方法等,可以实现对发布数据时的匿名保护。在大数据环境下,需要对这些数据进行改进和发展。
2.2 数据存储
在大数据时代,数据存储方一般为云存储平台,大数据的存储者和拥有者是分离的,云存储服务商并不能保证是完全可信的。用户的数据面临着被不可信的第三方偷窃数据或者篡改数据的风险。加密方法是解决该问题的传统思路,但是,由于大数据的查询、统计、分析和计算等操作也需要在云端进行,为传统加密技术带来了新的挑战。同态加密技术、混合加密技术、基于BLS短签名POR模型、DPDP、Knox等方法,是针对数据存储时防止隐私泄露而采取的一些方法。
2.3 数据挖掘
在大数据环境下,由于数据存在来源多样性和动态性等特点,在经过匿名等处理后的数据,经过大数据关联分析、聚类、分类等数据挖掘方法后,依然可以分析出用户的隐私。针对数据挖掘的隐私保护技术&

