python3 登录公众号并抓取数据
公众号领取:关注商家公众号,经常查看推送的优惠券信息。 #生活技巧# #节省生活成本# #生活成本# #优惠券使用方法#
python3 登录公众号并抓取数据
公司有一个微信公众号,每天都会推送同事原创的文章,技术类、文学类、生活类什么都有。虽然微信本身提供了报表功能,但是不满足我们自己的运营需求,需要手工统计下每月的数据,后来我帮忙写了脚本抓取数据
目标: 登录微信公众号获取图文分析数据获取用户分析数据 相关工具 抓包 Fiddler+chrome network 请求生成 chrome postman 编辑器 pycharm通过抓包工具可以分析出步骤如下
初始化登录页面提交用户名密码获取登录二维码定时(我设置的是每一秒)检测二维码状态:未扫描,已扫描,已登录,超时(这个未做测试,不过应该有这个环节)二维码登录成功后,调用登录接口,获取首页和token(每次登录成功的token都不一样,在请求数据的时候token为必填参数)访问登录成功后的页面开始抓取数据有几个点需要注意下:
必须要初始化页面,获取cookie中的u_id密码是32位小写md5加密的,不能明文提交(这个可以通过抓包发现,实例代码中配置的是加密过后的数据)token必须获取,登录成功后请求数据都必须把token作为参数请求header必须加 ‘referer’: ‘https://mp.weixin.qq.com/’ ,这个微信后台有做校验,虽然抓包的时候各个请求的header不一样,但是经试验,统一写成这个是没问题的,整个请求可以使用同一个header登录流程比较长,有严格的cookie校验,为了方便,我是用的是client = requests.Session()来接收session,串联整个请求示例代码使用的账号是被管理员加入了公众号运营的,所以登录很顺利,其他登录流程暂未尝试本次试验是在window 7,python3 环境 示例代码# coding:utf-8 import calendar import datetime import json import random import time import requests from PIL import Image from urllib3.exceptions import InsecureRequestWarning from wechat.db_util.db_util import insert_appmsg, insert_user from wechat.login.config import password, username # 禁用安全请求警告 requests.packages.urllib3.disable_warnings(InsecureRequestWarning) root_url = 'https://mp.weixin.qq.com' headers = { 'accept-encoding': "gzip, deflate, sdch, br", 'accept-language': "en-US,en;q=0.8,zh-CN;q=0.6,zh;q=0.4", 'user-agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36", 'accept': "*/*", 'x-requested-with': "XMLHttpRequest", 'connection': "keep-alive", 'cache-control': "no-cache", 'referer': 'https://mp.weixin.qq.com/' } client = requests.Session() def init_login_page(): # 初始化登录页面,获取u_id client.request("GET", root_url, headers=headers, verify=False) def submit_pwd(): # 提交登录用户名和密码 url = root_url + '/cgi-bin/bizlogin' querystring = {"action": "startlogin"} payload = "username=" + username + "&pwd=" + password + "&imgcode=&f=json&token=&lang=zh_CN&ajax=1" response = client.request("POST", url, data=payload, headers=headers, params=querystring, verify=False) content = response.text return json.loads(content)['redirect_url'] def get_qr_code_page(redirect_url): redirect_url = root_url + redirect_url client.request("GET", redirect_url, headers=headers) def get_qr_code(): qr_code = client.get(root_url + '/cgi-bin/loginqrcode?action=getqrcode') open('login.jpg', 'wb').write(qr_code.content) img = Image.open('login.jpg') img.show() def check_qr_code_status(): while True: url = root_url + "/cgi-bin/loginqrcode" querystring = {"action": "ask", "token": "", "lang": "zh_CN", "f": "json", "ajax": "1"} response = client.request("GET", url, headers=headers, params=querystring) content = response.text print(content) if json.loads(content)['user_category'] == 3: break time.sleep(1) def final_login(): url = root_url + "/cgi-bin/bizlogin" querystring = {"action": "login"} payload = "token=&lang=zh_CN&f=json&ajax=1" response = client.request("POST", url, data=payload, headers=headers, params=querystring, verify=False) content = response.text return json.loads(content)['redirect_url'] def get_home_page(redirect_url): redirect_url = root_url + redirect_url client.request("GET", redirect_url, headers=headers, verify=False) def get_useranalysis(token, begin, end, month): url = "https://mp.weixin.qq.com/misc/useranalysis" querystring = {"": "", "begin_date": begin, "end_date": end, "source": "99999999,99999999", "token": token, "lang": "zh_CN", "f": "json", "ajax": "1", "random": random.uniform(0, 1)} headers['referer'] = "https://mp.weixin.qq.com/misc/useranalysis?&token=" + token + "&lang=zh_CN" response = client.request("GET", url, headers=headers, params=querystring) insert_user(response.text, month) def get_appmsganalysis(token, begin, end, month): url = "https://mp.weixin.qq.com/misc/appmsganalysis" querystring = {"action": "all", "begin_date": begin, "end_date": end, "order_by": "1", "order_direction": "2", "token": token, "lang": "zh_CN", "f": "json", "ajax": "1", "random": "0.27315807795869107"} response = client.request("GET", url, headers=headers, params=querystring) insert_appmsg(response.text, month) def domain(month): begin, end = get_month_first_day_last_day(month) # 初始化登录页面 init_login_page() # 提交用户名密码,获取二维码页面url redirect_url = submit_pwd() # 跳转二维码页面 get_qr_code_page(redirect_url) # 下载二维码到本地,并打开 get_qr_code() # 循环检测二维码状态,直到被扫描 check_qr_code_status() # 获取登录成功后的页面 redirect_url = final_login() get_home_page(redirect_url) # 解析token,以后请求都需要这个token arr = redirect_url.split('=') token = arr[len(arr) - 1] # 获取用户分析数据 get_useranalysis(token, begin, end, month) # 获取图文分析数据 get_appmsganalysis(token, begin, end, month) print("done") def get_month_first_day_last_day(str=None): arr = str.split('-') year = int(arr[0]) month = int(arr[1]) # 获取当月第一天的星期和当月的总天数 firstDayWeekDay, monthRange = calendar.monthrange(year, month) # 获取当月的第一天 firstDay = datetime.date(year=year, month=month, day=1) lastDay = datetime.date(year=year, month=month, day=monthRange) return time.strftime('%Y-%m-%d', firstDay.timetuple()), time.strftime('%Y-%m-%d', lastDay.timetuple()) if __name__ == '__main__': domain("2017-08")
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149这里面的wechat.login.config.py是配置的账号和密码,就不宜贴出来了,insert操作是把数据插入mongodb里面,这里就不赘述了
其中有很多的请求都是用postman生成的,这里简单介绍下:
比如要用python3抓取百度首页
通过chrome获取到curl命令
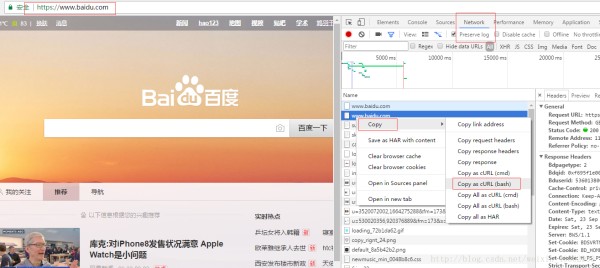
得到这样的内容:
curl 'https://www.baidu.com/' -H 'Accept-Encoding: gzip, deflate, sdch, br' -H 'Accept-Language: en-US,en;q=0.8,zh-CN;q=0.6,zh;q=0.4' -H 'Upgrade-Insecure-Requests: 1' -H 'User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36' -H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8' -H 'Cookie: BAIDUID=36E510C5B8088D855DC1BC020DA0FBCE:FG=1; PSTM=1500784814; BIDUPSID=F29907779469DA92CEA9E9E0A8B1C162; BDUSS=UppSnptcGtpZlJrYjNxelhSa01zcldIMnlQbjNYZWRvVzc0bmN0TkVTeHlSYlpaTVFBQUFBJCQAAAAAAAAAAAEAAADo6~If8LLT8Men0rkzMjcAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHK4jllyuI5ZW; H_PS_PSSID=1431_24544_21096_18559_17001_20928; BD_UPN=12314353; sug=3; sugstore=1; ORIGIN=0; bdime=21110; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDSVRTM=0' -H 'Connection: keep-alive' --compressed1
打开postman,选择import->paste raw text->将内容粘贴进去->import

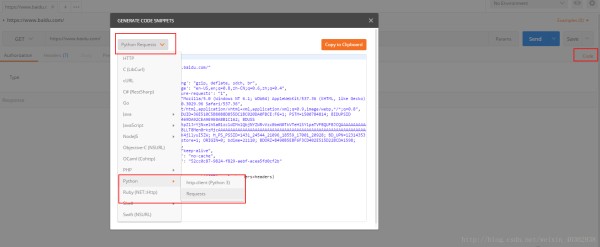
这样就能抓取公众号后台的数据,然后进一步进行分析和生成报表了,生成报表的过程中还用到了历史文章、作者以及发布时间等信息,之前公众号里面有提供这些数据,后面不知怎么的,没有了,所以我只好换其他方式进行抓取了,下次再介绍吧
网址:python3 登录公众号并抓取数据 https://www.yuejiaxmz.com/news/view/738732
相关内容
Python3python3读取文件和异常处理(七)
会员登录
Python3安装PyYAML
《Python3爬虫、数据清洗和可视化实战》之阅读不懂处、主要代码总结(5
如何推送微信公众号消息
公交线路数据获取脚本分享
乐竞网页版登录
APIX平台获取生活服务数据,步骤有哪些?
公众号排版长图设计工具
随便看看
最新动态分享
- 电器保养秘籍!这些备件你必须知道! – 一招妙解
- 智能锁故障排查与解决方案,家电保养秘籍
- 家电安全使用指南:空调、冰箱、洗衣机、热水器等常见故障排除与保养秘籍,让生活更安心!
- 清洁也疯狂:家居保养的另类秘籍
- “会用”才能真的省心 白电保养护理秘籍
- 家电故障处理秘籍,轻松应对日常问题
- 厨房小家电独家保养秘籍(图).doc
- 凛冬将至 空调等家电保养秘笈了解下
- 如何预防家电故障:日常保养与维护技巧
- 宜百利教你冬季三大家用电器的保养秘诀
热点动态分享
- 2825
- 2694
- 2619
- 2355
- 2207
- 1837
- 1652
- 1500
- 1396
- 1313

