pytorch中的Optimizer的灵活运用
使用PyTorch的`nn.CrossEntropyLoss`进行多分类问题的损失计算 #生活技巧# #学习技巧# #深度学习技巧#
pytorch可以自动求导梯度,不过要对需要求梯度的tensor设置为“requires grad = TRUE"。同时,pytorch可以对神经网络进行灵活训练,主要同通过Optimazer的设计来实现的。
以下针对不同的应用场景需要对optimizer的使用进行总结。
1. 多个神经网络联合训练
应用场景
(1)Autoencoder网络分为encoder与decoder两部分组成,中间加入了AWGN噪声。首先两部分进行联合训练,得到压缩编码,然后再单独将接收端进行训练,观看性能是否有所提升。
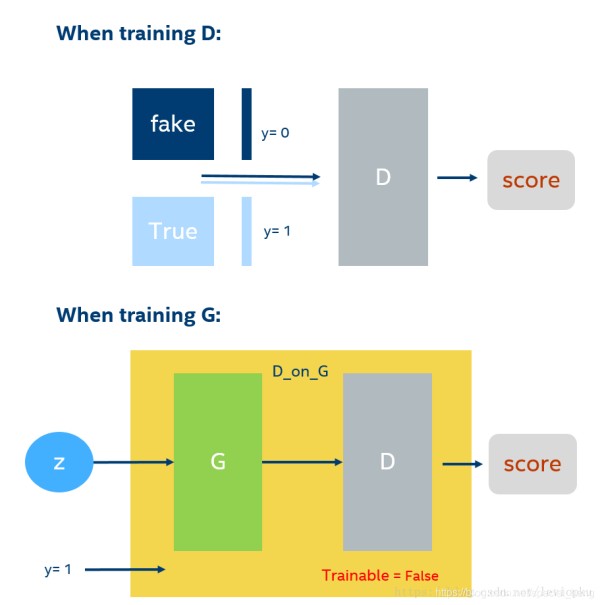
(2)GAN网络的discriminator需要单独进行training,generator需要经过discriminator后,再进行参数更新,同时,discriminator锁死,不进行参数更新,只进行梯度反传。
具体实现
(1)Autoencoder只进行接收端的训练时,网络结构如下,定义一个encoder的网络参数,再定义一个decoder的网络参数
super(AutoEncoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(InputNum, 128),
nn.LeakyReLU(),
nn.Linear(128,OutputBit),
)
self.decoder = nn.Sequential(
nn.Linear(OutputBit,128),
nn.LeakyReLU(),
nn.Linear(128, InputNum),
)
Optimizer定义为:
net = AutoEncoder()
net.apply(weight_init)
optimizer = optim.Adam(net.parameters(), lr = LR)
decoder_optimizer = optim.Adam(net.decoder.parameters(), lr=LR)
criterion = nn.CrossEntropyLoss()
第一个optimaizer为整个net的parameters,第二个decoder_optimizer的参数只传入了net.decoder.parameters(),所以
decoder_optimizer.step()
只更新decoder的参数。
(2)GAN在训练网络时如下图:
pytorch网络结构实现为:
class discriminator(nn.Module):
def __init__(self):
super(discriminator,self).__init__()
self.dis=nn.Sequential(
nn.Linear(784,256),#输入特征数为784,输出为256
nn.LeakyReLU(0.2),#进行非线性映射
nn.Linear(256,256),#进行一个线性映射
nn.LeakyReLU(0.2),
nn.Linear(256,1),
nn.Sigmoid()#也是一个激活函数,二分类问题中,
# sigmoid可以班实数映射到【0,1】,作为概率值,
# 多分类用softmax函数
)
def forward(self, x):
x=self.dis(x)
return x
class generator(nn.Module):
def __init__(self):
super(generator,self).__init__()
self.gen=nn.Sequential(
nn.Linear(100,256),
nn.ReLU(True),
nn.Linear(256,256),
nn.ReLU(True),
nn.Linear(256,784),
nn.Tanh()
)
def forward(self, x):
x=self.gen(x)
return x
discriminator的优化器设置如下:
#创建对象
D=discriminator()
G=generator()
criterion = nn.BCELoss() #是单目标二分类交叉熵函数
d_optimizer=torch.optim.Adam(D.parameters(),lr=0.0003)
g_optimizer=torch.optim.Adam(G.parameters(),lr=0.0003)
# 损失函数和优化
d_loss = d_loss_real + d_loss_fake #损失包括判真损失和判假损失
d_optimizer.zero_grad() # 在反向传播之前,先将梯度归0
d_loss.backward() # 将误差反向传播
d_optimizer.step() # 更新参数
generator优化器为:
# 计算假的图片的损失
z = Variable(torch.randn(num_img, z_dimension)).cuda() # 得到随机噪声
fake_img = G(z) #随机噪声输入到生成器中,得到一副假的图片
output = D(fake_img) # 经过判别器得到的结果
g_loss = criterion(output, real_label) # 得到的假的图片与真实的图片的label的loss
g_optimizer.zero_grad() # 梯度归0
g_loss.backward() # 进行反向传播
g_optimizer.step() # .step()一般用在反向传播后面,用于更新生成网络的参数
由于两个网络是分开设置的,所以两个网络的参数也是分开更新的。在更新G的参数时,使用D网络进行传输,所以D网络的梯度进行计算,但是在step时,D的参数并不更新。
2.对网络中固定部分参数进行训练
方法一:首先将网络层中不进行更新的参数的requires_grad属性设置为False,然后再optimizer中加入过滤器即可。
具体参考:https://blog.csdn.net/guotong1988/article/details/79739775
https://blog.csdn.net/weixin_34261739/article/details/87555871?tdsourcetag=s_pcqq_aiomsg
optimizer.SGD(filter(lambda p: p.requires_grad, model.parameters()), lr=1e-3)
对于网络层中的设置方法比较多,如:features是构建NN中的一个模组。
for i, para in enumerate(self._net.module.features.parameters()):
if i < 16:
para.requires_grad = False
else:
para.requires_grad = True
在加载预训练模型之后,在原来的基础上添加一部分的网络,我们可以固定原来的参数,然后只训练我们添加的这部分网络,完了之后再全部训练.
class RESNET_attention(nn.Module):
def __init__(self, model, pretrained):
super(RESNET_attetnion, self).__init__()
self.resnet = model(pretrained)
for p in self.parameters():
p.requires_grad = False
self.f = nn.Conv2d(2048, 512, 1)
self.g = nn.Conv2d(2048, 512, 1)
self.h = nn.Conv2d(2048, 2048, 1)
self.softmax = nn.Softmax(-1)
self.gamma = nn.Parameter(torch.FloatTensor([0.0]))
self.avgpool = nn.AvgPool2d(7, stride=1)
self.resnet.fc = nn.Linear(2048, 10)
optimizer = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=0.0001, betas=(0.9, 0.999), eps=1e-08, weight_decay=1e-5)
如果是Variable,则可以初始化时指定
j = Variable(torch.randn(5,5), requires_grad=True)
但是如果是
m = nn.Linear(10,10)
是没有requires_grad传入的
m.requires_grad也没有
需要用for循环
for i in m.parameters():
i.requires_grad=False
另外一个小技巧就是在nn.Module里,可以在中间插入这个
for p in self.parameters():
p.requires_grad=False
这样前面的参数就是False,而后面的不变
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
for p in self.parameters():
p.requires_grad=False
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
在fine tuning一个预训练的网络时,要增加一个参数组,还可以用下面方法:
add_param_group(param_group)
加载optimizer的状态
load_state_dict(state_dict)
获取一个optimizer的状态(一个dict)。
state_dict()
model=resnet()#自己构建的模型,以resnet为例
model_dict = model.state_dict()
pretrained_dict = torch.load('xxx.pkl')
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict)
for k,v in model.named_parameters():
if k!='xxx.weight' and k!='xxx.bias' :
v.requires_grad=False#固定参数
optimizer2=torch.optim.Adam(params=[model.xxx.weight,model.xxx.bias],lr=learning_rate,betas=(0.9,0.999),weight_decay=1e-5)
3.Optimizer不同的参数设置不同的学习速率
参考:https://www.cnblogs.com/hellcat/p/8496727.html
为不同的子网络参数不同的学习率,finetune常用,使分类器学习率参数更高,学习速度更快(理论上).
网络结构:
import torch as t
class LeNet(t.nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.features = t.nn.Sequential(
t.nn.Conv2d(3, 6, 5),
t.nn.ReLU(),
t.nn.MaxPool2d(2, 2),
t.nn.Conv2d(6, 16, 5),
t.nn.ReLU(),
t.nn.MaxPool2d(2, 2)
)
# 由于调整shape并不是一个class层,
# 所以在涉及这种操作(非nn.Module操作)需要拆分为多个模型
self.classifiter = t.nn.Sequential(
t.nn.Linear(16*5*5, 120),
t.nn.ReLU(),
t.nn.Linear(120, 84),
t.nn.ReLU(),
t.nn.Linear(84, 10)
)
def forward(self, x):
x = self.features(x)
x = x.view(-1, 16*5*5)
x = self.classifiter(x)
return x
net = LeNet()
(1)经由构建网络时划分好的模组进行学习率设定:(粗粒度设定)
optimizer = optim.SGD([{'params': net.features.parameters()}, # 默认lr是1e-5
{'params': net.classifiter.parameters(), 'lr': 1e-2}], lr=1e-5)
(2)以网络层对象为单位进行分组,并设定学习率:(细粒度)着重学习nn.ModuleList是如何工作的。
special_layers = t.nn.ModuleList([net.classifiter[0], net.classifiter[3]])
special_layers_params = list(map(id, special_layers.parameters()))
print(special_layers_params)
base_params = filter(lambda p: id(p) not in special_layers_params, net.parameters())
optimizer = t.optim.SGD([{'params': base_params},
{'params': special_layers.parameters(), 'lr': 0.01}], lr=0.001)
(3)在训练中动态的调整学习率
'''调整学习率'''
print(optimizer.param_groups[0]['lr'])
old_lr = 0.1
optimizer = optim.SGD([{'params': net.features.parameters()},
{'params': net.classifiter.parameters(), 'lr': old_lr*0.1}], lr=1e-5)
可以看到optimizer.param_groups结构,[{'params','lr', 'momentum', 'dampening', 'weight_decay', 'nesterov'},{……}],集合了优化器的各项参数。
辅助理解:
法1(比较推荐):新建一个optimizer。对于使用动量的优化器(如Adam),会丢失动量等状态信息,可能会造成损失函数的收敛出现震荡等情况
old_lr = 0.1 optimizer1 =optim.SGD([ {'params': net.features.parameters()}, {'params': net.classifier.parameters(), 'lr': old_lr*0.1} ], lr=1e-5) optimizer1
法2:一种是修改optimizer.param_groups中对应的学习率
# 方法2: 调整学习率, 手动decay, 保存动量 for param_group in optimizer.param_groups: param_group['lr'] *= 0.1 # 学习率为之前的0.1倍 optimizer
网址:pytorch中的Optimizer的灵活运用 https://www.yuejiaxmz.com/news/view/738739
相关内容
深入了解PyTorch中的语音识别和语音生成PyTorch 深度学习框架简介:灵活、高效的 AI 开发工具
神经网络在现实生活中的应用
pytorch中的model=model.to(device)使用说明
把显存用在刀刃上!17 种 pytorch 节约显存技巧
wlan optimizer下载
对循环神经网络(RNN)中time step的理解
深入理解PyTorch的语音识别与语音合成1.背景介绍 语音识别和语音合成是人工智能领域中的两个重要技术,它们在现实生活
pytorch 1.1.0升级
实战教程:如何利用Optimizer优化你的Windows系统?
随便看看
最新动态分享
- 蔬果搭配哪些食物吃了好
- 解锁夏日健康秘诀,果蔬搭配一网打尽!
- 怎样根据不同的季节进行合理膳食搭配?专家支招
- 掌握饮食黄金时间,助力体重管理和健康生活
- 糖尿病就不能吃水果?这个误会该解开了
- 四月必吃的6种水果,照着这张图来挑
- 糖尿病可以吃什么水果?控糖生活不单调:糖尿病适宜水果全记录
- 牛奶和这些水果一起吃,健康又美味
- 联合国决议 | 2021年为“国际果蔬年”,促进健康膳食、强化免疫系统尤为重要
- 食物搭配的科学与误区:基于消化原理的饮食优化指南
热点动态分享
- 3155
- 2918
- 2916
- 2645
- 2495
- 1964
- 1690
- 1594
- 1579
- 1478

