mobile task automation using vision
'Using powerpoint presentations effectively',简洁明了 #生活技巧# #职场沟通技巧# #商务英语#
西安交大最新成果!端侧智能体VisionTasker:让AI自动完成手机中各种任务
智猩猩GenAI 2024年11月22日 19:34 北京
大会预告

12月5-6日,智猩猩共同主办的2024中国生成式AI大会(上海站)将举办。北大(临港)大模型对齐中心执行主任徐骅,腾讯优图实验室天衍研究中心负责人吴贤,银河通用机器人合伙人张直政,西湖心辰CEO醒辰,趣丸科技副总裁贾朔等30+位嘉宾已确认参会演讲。欢迎报名~
导读

西安交通大学智能网络与网络安全教育部重点实验室 (MOE KLINNS Lab)投稿。
移动任务自动化是一个关注度不断升高的新兴研究领域。本文主要介绍了MOE KLINNS Lab提出的基于视觉的移动设备任务自动化框架VisionTasker。VisionTasker是一个结合了基于视觉的UI理解和LLM任务规划的两阶段开源框架,用于实现移动任务的自动化。相关论文已被人机交互领域顶会UIST 2024收录。
这项研究来自西安交通大学蔡忠闽教授、宋云鹏副教授团队,团队主要研究方向为智能人机交互、混合增强智能、电力系统智能化等;曾受到科技创新 2030—"新一代人工智能"重大项目、国家自然科学基金及创新群体、国家“863”计划等多个国家级项目支持;在国际顶级会议如NeurIPS、CHI、UIST、UbiComp、CSCW上已公开发表多篇论文,涵盖人机交互技术、混合增强智能等领域。
01

引言
随着人工智能技术的飞速发展,移动任务自动化成为一个新兴的研究领域。它利用AI技术精准捕捉并解析人类意图,进而在移动设备上高效执行多样化任务,为那些因认知局限、身体条件限制或身处特殊情境下的用户提供前所未有的便捷与支持。例如,移动任务自动化能够辅助老年人跨越数字鸿沟,轻松完成诸如水电缴费等以往可能显得繁琐复杂的日常生活事务;帮助视觉障碍用户完成导航、阅读或在线购物等关键任务;帮助车主在驾驶过程中完成发送短信或调节车内环境等操作;此外,还能替用户完成日常生活中普遍存在的重复性任务,如设置多个日历事项或发送相似消息。这项研究不仅为普通用户提供了更智能的移动设备使用体验,也展现出了对特殊需求群体的关怀与赋能,为他们提供更人性化便利服务。
传统自动化方法比如基于演示的编程(Programming By Demonstration, PBD)通过记录用户操作创建脚本,但对应用版本更新敏感且依赖于预设任务。新兴研究转向利用视图层次结构和大语言模型(LLM)来提升任务自动化,但视图层级结构存在可访问性和数据准确性的挑战。有研究还尝试通过大规模数据集训练多模态模型以理解用户命令,但是这些数据集常包含错误样本,限制了模型对新任务的适应能力。
研究提出了VisionTasker,这是一个结合了基于视觉的UI理解和LLM任务规划的两阶段开源框架,用于实现移动任务的自动化。首先,VisionTasker使用基于视觉的UI理解方法将UI界面转换为自然语言描述,消除对视图层次结构的依赖。其次,采用逐步任务规划方法,一次只呈现一个界面给LLM;LLM识别界面中相关元素并确定下一个动作,提高了执行的准确性和实用性。通过广泛的实验,VisionTasker在4个公开数据集上的UI表示表现能力突出,超越了先前的方法。此外,在自动化执行智能手机上的147个真实的世界任务时,VisionTasker在处理人类不熟悉的任务时表现地比人类执行更有优势,且在与PBD机制集成时其能力还可以进一步提升。
研究的主要贡献包括:
1. 提出了VisionTasker,这是一个结合了基于视觉的UI理解和LLM任务规划的两阶段框架,用于逐步实现移动任务自动化。这种方法有效消除了表示UI对视图层次结构的依赖,提高了对不同应用界面的适应性;同时无需大量数据训练大模型。
2. 定制了一种基于视觉的UI理解方案,并设计了一个系统的过程,将UI截图转换为自然语言形式的表达性UI布局语义;并可以通过结合演示编程(PBD)方法进一步增强。该方案避免了使用视图层次结构可能导致的可访问性问题和信息缺失,增强了对UI元素理解能力和任务规划的准确性。
3. 通过广泛的实验验证了VisionTasker在多个公开数据集上的有效性,在跨屏幕尺寸、任务类型和复杂程度的自动化任务中能力突出。

• 原文链接:https://dl.acm.org/doi/10.1145/3654777.3676386
• 项目链接:https://github.com/AkimotoAyako/VisionTasker
• 论文标题:VisionTasker: Mobile Task Automation Using Vision Based UI Understanding and LLM Task Planning.
这项研究来自西安交通大学蔡忠闽教授、宋云鹏副教授团队,团队主要研究方向为智能人机交互、混合增强智能、电力系统智能化等。曾受到科技创新 2030—"新一代人工智能"重大项目、国家自然科学基金及创新群体、国家“863”计划等多个国家级项目支持;在国际顶级会议如NeurIPS、CHI、UIST、UbiComp、CSCW上已公开发表多篇论文,涵盖人机交互技术、混合增强智能等领域。
02

框架介绍
VisionTasker工作流
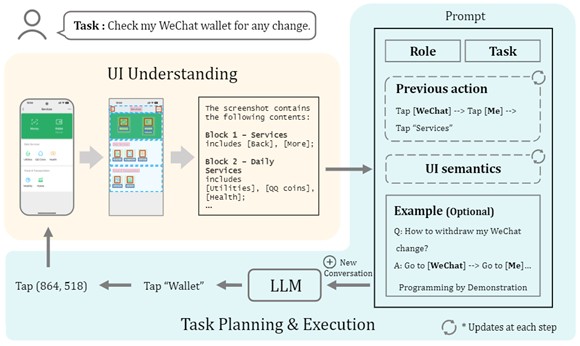
1. VisionTasker工作从用户以自然语言提出任务需求开始,智能agent开始理解并执行指令。
2. 智能agent利用大语言模型(LLM)作为导航器,对用户界面的屏幕界面进行深入分析,以自然语言的形式解释当前界面的UI元素及其布局。
3. 随后,agent进入任务规划与执行阶段,将用户的任务细化为可执行的步骤,如点击或滑动操作,以自动推进任务的完成。
在需要时,agent还可以通过用户提供的示例或通过演示编程(PBD)机制来辅助任务规划。每一步完成后,agent都会根据最新的界面状态和历史动作更新其对话和任务规划,确保每一步的决策都是基于当前上下文的。
这个过程是迭代的,持续进行直到任务完成或达到预设的动作限制。用户虽然可以从手动交互中解放,但仍可以通过界面上的可见提示监控任务进度,并随时停止任务,保持对整个流程的控制。
基于视觉的UI理解过程
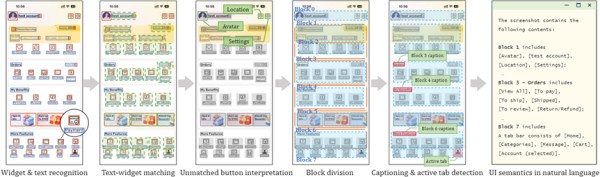
VisionTasker 通过视觉基础 UI 理解过程来解析和解释用户界面:
首先识别界面中的小部件和文本,使用YOLO v8 等模型来检测按钮、文本框等元素及其位置。
对于那些没有直接文本标签的按钮,系统利用 CLIP 模型基于视觉设计来推断其可能的功能。
随后,系统根据 UI 布局的视觉信息进行区块划分,将界面分割成多个具有不同功能的区块,并对每个区块生成自然语言描述。这个过程还包括文本与小部件的匹配,确保正确理解每个元素的功能,以及为区块生成标题和检测活动标签。
最终,所有这些信息被转化为自然语言描述,为大语言模型提供清晰、语义丰富的界面信息,使其能够有效地进行任务规划和自动化操作。
03

实验
对比实验
实验评估部分,文章提供了对三种 UI 理解方法——GPT-4V、VH(视图层级),以及作者提出的 VisionTasker 方法的比较分析。

三种UI理解方法的比较分析
文章这些指标显示 VisionTasker 在多个维度上相比其他方法有显著优势。此外,文章中的方法在处理跨语言应用时也表现出了良好的泛化能力,例如在英文应用上训练并在中文应用上测试。表明 VisionTasker 的以视觉为基础的 UI 理解方法在理解和解释 UI 方面具有明显优势,尤其是在面对多样化和复杂的用户界面时尤为明显。
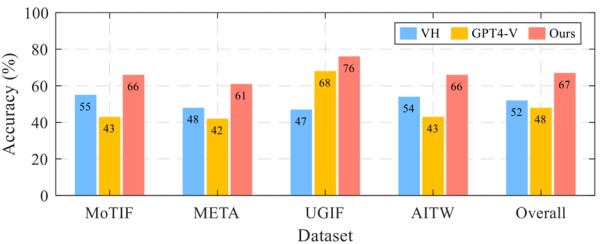
跨四个数据集的单步预测准确性
文章还进行了单步预测实验,根据当前的任务状态和用户界面,预测接下来应该执行的动作或操作。结果显示 VisionTasker 在所有数据集上的平均准确率达到了 67%,比基线方法提高了超过 15%。
真实世界任务:VisionTasker vs 人类
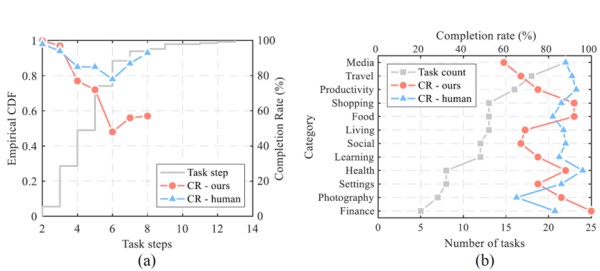
实验设计了147个真实世界的多步骤任务,用以测试 VisionTasker 在以华为 P20 智能手机为例上的表现。这些任务涵盖了中国常用的42个应用程序。并设置了人类基线测试,由12名人类评估者手动执行这些任务,并与 VisionTasker 的结果进行比较。
实验结果显示,VisionTasker 在大多数任务中都能达到与人类相当的完成率,并且在某些不熟悉的任务中表现优于人类。这表明 VisionTasker 是一个有前景的移动任务自动化工具,能够处理各种复杂性的任务,并且在某些情况下可能比人类用户更有效。

实际任务自动化实验的结果 "Ours-qwen"是指使用开源Qwen实现VisionTasker框架,"Ours"表示使用文心一言作为LLM
还评估了VisionTasker在不同条件下的表现,包括使用不同的大语言模型(LLM)和编程演示(PBD)机制。VisionTasker 在大多数直观任务中达到了与人类相当的完成率,在熟悉任务中略低于人类但在不熟悉任务中优于人类。
在任务步骤数量和任务类别方面,VisionTasker显示出良好的性能,尽管随着步骤数量的增加,任务完成率有所下降。通过PBD机制,VisionTasker在之前未能完成的36个任务中成功自动化了约70%,显示了PBD在任务规划中的有效性。实验还发现,即使在不同设备、屏幕大小、分辨率和语言环境下,PBD生成的序列也表现出良好的适应性。错误分析显示,VisionTasker在UI理解和任务规划方面的错误较少,尤其是在使用自然语言描述UI时,相比基于HTML的UI描述,能够为LLM提供更准确的任务规划支持。
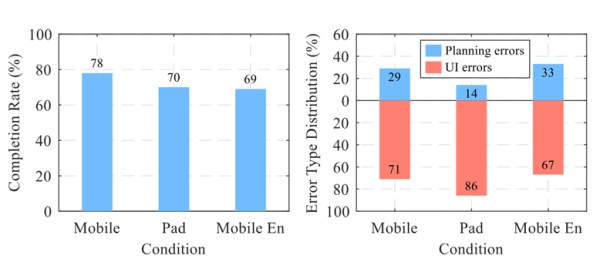
PBD在不同条件下的有效性
最后验证了在不同条件下通过演示编程(PBD)机制增强 VisionTasker 任务自动化系统的有效性。实验在三种不同的环境中进行:同一智能手机、不同屏幕尺寸和分辨率的平板电脑、以及语言版本变化的智能手机,以测试 PBD 序列的适应性和鲁棒性。
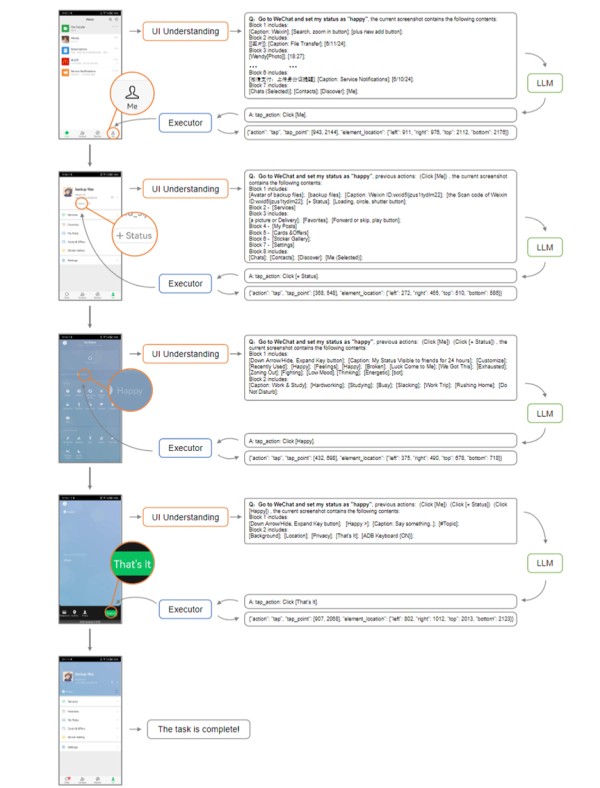
VisionTasker逐步完成任务的展示
04

结论
VisionTasker作为一个基于视觉和大模型的移动任务自动化框架,克服了现阶段移动任务自动化对视图层级结构的依赖。通过一系列对比实验,证明了其在用户界面表示上超越了传统的编程演示和视图层级结构方法。它在4个不同的数据集上都展示了高效的UI表示能力,表现出更广泛的应用性;并在自动化Android智能手机上的147个真实世界任务中,特别是在复杂任务的处理上,表现了出超越人类的任务完成能力。此外,通过集成编程演示(PBD)机制,VisionTasker在任务自动化方面实现了显著的性能提升,显示了其在自动化执行领域的广阔前景。VisionTasker的成功实验,验证了其在移动任务自动化中的创新性和实用性,为未来更加智能的自动化执行任务提供了新思路。
END
网址:mobile task automation using vision https://www.yuejiaxmz.com/news/view/764312
相关内容
consider using the replace, lineinfileOmni Automation 的出现,让 iOS 版 OmniFocus 和 Mac 版一样强大
推荐几个免费自动化工具 · 测试之家
No CUDA runtime is found, using CUDA
家庭自动化系统的研究与实现
Aluminum Panel Wall Switch And Tuya Smartlife App Wifi Lights Smart Touch Switch For Smart Home Automation
Home Automation System
Vision Pro将成生产力工具
【Mobile Push
自动化维护任务 – Automated Maintenance Task (转)
随便看看
最新动态分享
- 家庭卫生大扫除的手抄报 家庭手抄报
- 周末居家大扫除必备好物!祛味抑菌,打造健康舒适家居环境!
- 家政市场万亿蓝图 轻喜到家双十二全新服务只为国人美好生活
- 正月初四要“扔穷”,要怎么扔?2清1整1洗1忌,送走贫穷与晦气
- 溧阳保洁公司:打造家居清新环境的秘密武器 – 58同城
- 加强常态化疫情防控环境卫生管理 上海各类市场每周四“大扫除”!
- 春季大扫除 让家居焕然一新
- 你的家居环境,可能正在影响你的人生轨迹!
- 【魅力巾帼】大五里镇开展“爱国卫生月,家居大扫除 ”——美丽庭院靓起来实践活动
- 2024年年底大扫除:转运吉日与家居风水的全攻略
热点动态分享
- 3170
- 2930
- 2922
- 2669
- 2507
- 1971
- 1695
- 1609
- 1593
- 1503

