这是我以前的一篇博文:数学建模用/Python爬虫实战——爬取Kelley Blue Book(KBB二手车交易网站)的交易信息
这是我在去年数学建模校赛时候写的一个爬虫,用来获得数据分析需要的数据信息。这一次不同与上一次,上一次使用的beautifulsoup和正则匹配来获取数据,这一次使用的是css和xpath选择器,且是基于scrapy框架的。这是爬取的要求:
这一次实现了翻页功能,代码如下所示:
items.py:
from scrapy import Item, Field
class CarItem(Item):
name = Field()
price = Field()
mile = Field()
spider/cars_spinder.py
import scrapy
from ..items import CarItem
class CarSpider(scrapy.Spider):
name = 'car'
start_urls = ['https://www.kbb.com/cars-for-sale/used?listingTypes=USED&searchRadius=0&marketExtension=include&isNewSearch=false&sortBy=derivedpriceDESC&numRecords=25&firstRecord=0']
def parse(self, response):
i = 0
url = "https://www.kbb.com/cars-for-sale/used?listingTypes=USED&searchRadius=0&marketExtension=include&isNewSearch=false&sortBy=derivedpriceDESC&numRecords=25&firstRecord="
for cars in response.css('div.padding-left-3.inventory-listing-body.padding-top-3.padding-right-3.margin-bottom-2'):
car = CarItem()
car['name'] = cars.xpath('./div/div/div/a/h2/text()').extract_first()
car['price'] = cars.xpath('./div/div/div/span/text()').extract_first()
car['mile'] = cars.css('div.text-bold::text').extract_first()
yield car
while i <= 13:
i += 1
temp = i * 25
next_url = url + str(temp)
print(next_url)
next_url = response.urljoin(next_url)
yield scrapy.Request(next_url, callback=self.parse)
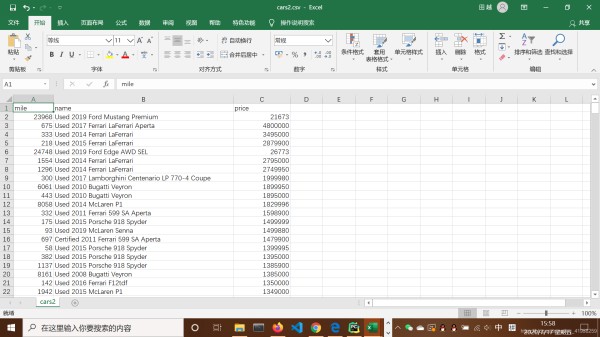
这是爬取的结果:

可以看到,这个csv文件暂时还不能直接使用,应为mile和price都还不是数字而是字符串,于是还要在pipelines.py文件里编辑如下的代码作为数据清洗的过程,同时不要忘记在settings.py文件中添加这个类:
class DropCarMile(object):
def process_item(self, item, spider):
item['mile'] = float(item['mile'][:-6].replace(',', ''))
item['price'] = float(item['price'].replace(',', ''))
return item
这就是最后的结果: