摩尔线程新方法优化AI交互:显存节省最多82%
利用AI算法推荐行程优化路线 #生活知识# #科技生活# #科技旅行#
摩尔线程新方法优化AI交互:显存节省最多82%

2025-03-04 19:10:19 出处:快科技 作者:上方文Q 编辑:上方文Q 人气: 5291 次 评论()

摩尔线程科研团队近日发布了一项新的研究成果《Round Attention:以轮次块稀疏性开辟多轮对话优化新范式》,使得端到端延迟低于现在主流的Flash Attention推理引擎,kv-cache显存占用节省最多82%。

近年来,AI大型语言模型的进步,推动了语言模型服务在日常问题解决任务中的广泛应用。
然而,长时间的交互暴露出两大显著问题:
首先,上下文长度的快速扩张因自注意力机制的平方级复杂度而导致巨大的计算开销;
其次,尽管键值(KV)缓存技术能缓解冗余计算,但显著增加的GPU内存需求,导致推理批处理规模受限,同时GPU利用率低下。
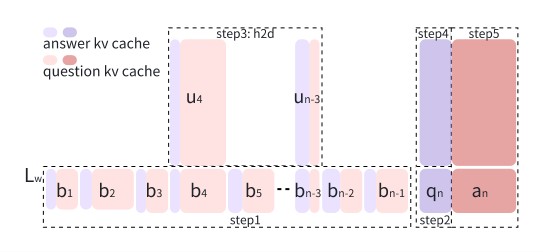
为此,摩尔线程提出了Round Attention,以解决这些问题。
首先,摩尔线程提出以轮次为分析单元研究Attention规律:
Round Attention专为多轮对话场景推理需求设计,以轮次为自然边界划分KV缓存。研究发现,轮次粒度的Attention分布存在两个重要规律。
其次,摩尔线程提出了Round Attention推理流水线;
基于发现的两个规律,将稀疏性从Token级提升至块级,选取最相关的块参与attention计算,减少attention计算耗时,并将不相关的块卸载到CPU内存,以节省显存占用。
这在保持推理精度的情况下,减少了推理耗时,降低了显存占用。
摩尔线程认为,轮次块稀疏性有三大优势:自然边界的语义完整性、分水岭层的注意力稳定性、端到端的存储与传输优化。
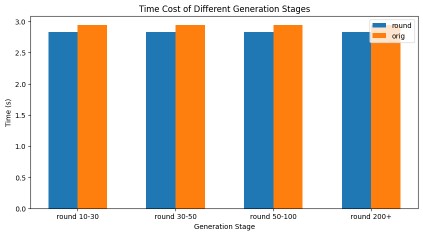
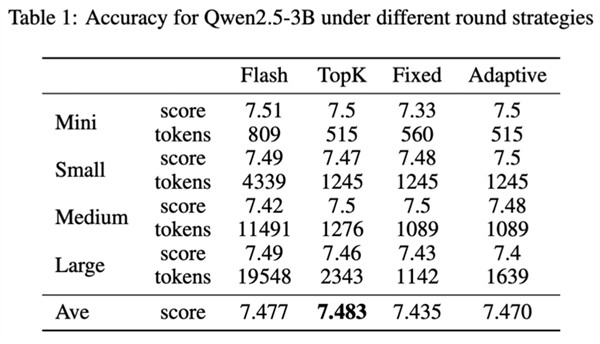
测试显示,Round Attention的端到端延迟低于现在主流的Flash Attention推理引擎, kv-cache显存占用则节省55-82%,并且在主观评测和客观评测两个数据集上,模型推理准确率基本未受影响。
【本文结束】如需转载请务必注明出处:快科技
责任编辑:上方文Q
文章内容举报
相关资讯 日本10亿研发费换来60%错误率AI工具!学习样本仅5000DeepSeek获官方点赞!为世界贡献中国智慧iPhone 15 Pro用户狂喜!iPhone 16独有AI功能将下放体积锐减85%!联想推首款紧凑型AI推理服务器:墙壁、天花板都能挂在欧洲 没人提DeepSeek 支持打赏支持26人
打赏
26 2 70 打赏
网址:摩尔线程新方法优化AI交互:显存节省最多82% https://www.yuejiaxmz.com/news/view/812237
相关内容
阿尔法蛋全网预售AI词典笔D1 Pro,开启中国教育智能化进程新时刻!摩科智能AI虚拟人交互一体机:以AI赋能金融,打造智慧理财助手!
自动化程序最新资讯
微星MEG VISION X AI幻影主机震撼上市:RTX 5080 AI交互革新体验
深入探索 AI 助理设置:优化交互体验
交互商城上线、数字工厂落地,卡泰驰构建二手车交易服务新生态
摩尔线程完成DeepSeek开源库FlashMLA和DeepGEMM的适配
节省显存新思路,在 PyTorch 里使用 2 bit 激活压缩训练神经网络
AI管家配音最新资讯
智能交通流量优化:新时代的解决方案
随便看看
最新动态分享
- 每日卫生清洁检查表.xls
- 保洁日常工作实用清单.doc
- 家庭保洁 钟点工管理 日 常 卫 生和计划卫生一览表
- 一个打扫清单,帮助您在家整理好自己
- 家庭日常清洁清单
- 英国留学生活日常用品清单
- 每天认真做一件家务
- 【物业保洁工作清单
- (参考+感悟)生活必需品清单
- 电梯装潢日常清洁工具推荐清单
热点动态分享
- 3426
- 3355
- 2998
- 2814
- 2704
- 2632
- 2202
- 2026
- 1786
- 1745

