强化学习1——基本概念、MDP、价值迭代、策略迭代、蒙特卡洛
深度学习强化学习:Q学习和策略梯度的基本概念 #生活技巧# #学习技巧# #深度学习技巧#
最近在学伯禹人工智能的强化学习课程,做了一点记录,主要也是为了便于理解和回顾。
1.强化学习简介
1.1 基本概念
强化学习是通过从交互学习来实现目标的计算方法。其交互过程是,在每一步t中,智能体与环境进行交互:
智能体(agent):获得观察O_t,获得奖励R_t,执行动作A_t;
环境:获得行动A_t,给出观察O_{t+1},给出奖励R_{t+1};
以上这种交互的一个完整的过程,我们可以称之为历史(History),这是一串关于观察、奖励、行动的序列,是一串一直到时间t为的所有观测变量。
状态(State):是一种用于确定接下来会发生的事情(动作A、奖励R、观测O),状态是关于历史的函数。状态通常是整个环境的,所观察到的状态可以视为所有状态的一部分,仅仅是智能体agent可以观察到的那一部分。
策略(Policy):是学习智能体在特定时间下的状态的行为方式。即从状态到行为的映射。策略可以分为两种:确定性策略(函数表示)和随机策略(条件概率表示)。
奖励(Reward):一种度量,立即感知到什么是好的,一般情况下是一个标量。
价值函数(Value function):长远来看(long-term),什么是好的。价值函数是对于未来累计奖励的预测,用于评估给定策略下,状态的好坏。
环境的模型(Model):用于模拟环境的行为,预测下一个状态,预测下一个立即奖励(reward)。
策略与状态转移方程的区别:
(1)策略,是在状态s时,可能执行不同的动作a的各自的概率,是一个n*m的矩阵(n个状态,m个动作);

(2)状态转移方程,是在状态s下,执行一个确定的动作a后,转移到各个状态s’的概率,是一个nnm的张量(n个状态,m个动作)
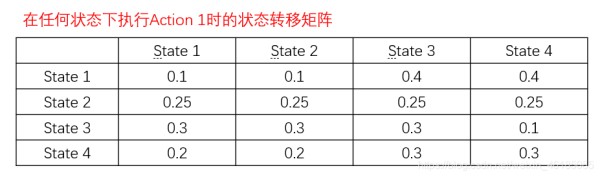
1.2 强化学习智能体agent的分类
强化学习大体可以分为两类:
(1)model-based RL(基于模型的强化学习):模型可以被环境所知道,agent可以直接利用模型执行下一步的动作,而无需与实际环境进行交互学习。
例如:围棋、迷宫、象棋等这类规则明确,且可以枚举下一个状态的所有可能(比如象棋黑方走了一步后,可以列举此时红方可能要走的棋子和要走的方式)
(2)model_free RL(模型无关的强化学习):真正意义上的强化学习,环境是黑箱,比如Atari游戏、王者荣耀游戏,其需要大量的采样。
强化学习的另外一种分类方式:
(1)基于价值:没有策略(隐含)、价值函数。通过估计价值,来推导出最优策略。
(2)基于策略:策略、没有价值函数。与基于价值的关系相反。
(3)Actor-Critic:策略、价值函数相辅相成
2 MDP——强化学习最基础的数学工具
2.1 MDP主要内容和性质
马尔科夫决策过程(Markov Decision Process,MDP):它提供了一套为在结果部分随机、部分在决策者的控制下的决策过程建模的数学框架。
MDP形式化地描述了一种强化学习环境,它的特点是环境完全可观测,即马尔科夫性质(当前状态可以完全表征过程,即根据当前状态,即可推演接下来的状态)。
马尔科夫性质:
“The future is independent of the past given the present.”
当前状态是St,如果给了之前的所有状态,来推演当前的下一个状态St+1,那么只要用到当前状态St,就可以推演出下一个状态St+1了。
数学表达: P[St+1|St] = P[St+1|S1,…,St]
特点:
(0)状态从历史中捕获了所有相关信息,St = f(Ht),即当前状态已经捕获了历史中的相关信息,并且映射为St;
(1)当状态已知的时候,可以抛开历史不管;
(2)当前状态是未来的充分统计量;
(3)MDP五元组;
2.2 MDP的表示
MDP可以由一个五元组表示(S,A,{Psa},γ,R),其中:
(1)S是状态的集合;
(2)A是动作的集合;
(3)Psa是状态转移概率(对每个状态s∈S和动作a∈A,Psa是下一个状态在S中的概率分布);
(4)γ∈[0,1]是对未来奖励的折扣因子,如果γ为1,则对未来的奖励和当前奖励是一样的重要程度;如果γ等于0,就不属于强化学习了,而是一种预测问题,即在什么状态下做什么动作,会对应什么奖励的这么一个二元预测问题。因此,正是由于这个γ,我们才能把预测问题和决策问题区分开;
注意:γ作为未来奖励的折扣因子,能使得和未来奖励相比起来,智能体更加重视即时奖励,以金融为例,今天的1美元,是比明天的1美元更有价值的,因为我们可以拿这一美元投资后,明天一定比一美元多。
(5)R:S×A–>R是奖励函数。
2.3 MDP的动态过程
网址:强化学习1——基本概念、MDP、价值迭代、策略迭代、蒙特卡洛 https://www.yuejiaxmz.com/news/view/91901
相关内容
RL笔记:动态规划(1): 策略估计和策略提升德立开放式浴室美学馆:开启自由畅想,迭代空间沉浸体验新范式
输入x,用迭代法按下列迭代公式求y=3根号x的值,初始值y0=x,精度要求4位有
轻娱乐 以“轻娱乐”方式开启健身指南,更新迭代的《哎呀好身材》传递“轻健身”理念
信息化时代大学生碎片化学习现状与策略研究
Dropout技术全面解析——深度学习中的泛化能力提升策略
金融科技| “用户习惯+ETF发展”强化生态优势:2025年投资策略
中国当代日常生活“泛艺术化”的符号学传播学反思
优化学习的18个策略
场景化时代,谁能定义中国厨房的未来? 时代更迭背后,对于企业来说,最大冲击就是一定会出现人们生活理念和生活方式的跨越,不是简单升级,而是另起炉灶新生。落到产业...
随便看看
最新动态分享
- 让你的顾客见识下你的专业,洗涤知识大全!
- 用燃气热水器为什么老是停?邯郸房价最新消息
- 洗涤知识(3)——贴身衣物的洗涤
- 壁挂炉为什么总是有滴滴声(德尔玛加湿器使用方法)
- 衣服锁边的手工缝法,手工锁边最简单的方法
- 热水器显示60度但不烫,私家花园设计实景图?
- 洗涤知识——贴身衣物的洗涤
- 热水器两边为什么要留空隙(雅居乐地产怎么样)
- 空调加氟为什么会突然停(废物利用手工制作大全图解)
- 洗衣机烘干为什么会有水声?la是什么意思
热点动态分享
- 2774
- 2657
- 2372
- 2299
- 2166
- 1805
- 1642
- 1491
- 1361
- 1304

