Python数据分析:对饮食与健康数据的分析与可视化
数据分析:Python的Pandas库数据处理 #生活知识# #编程教程#
2024.02前Python学习小结
1、 Python数据分析:对饮食与健康数据的分析与可视化
2、Python机器学习:Scikit-learn简单使用
3、Python深度学习:Tensorflow简单使用
前言
本文旨在对以往学习的相关内容进行总结回顾,通过seaborn对饮食与健康数据进行分析,侧重实现各数量间关系的可视化,因此具备以下特点:
不苛求完全贴切,由于练习目的,不过多追求方法准确使用多种方法,对同样问题在保证准确情况下使用多种方法侧重任务描述,更像是说明书一、数据说明
本文数据包含饮食习惯相关属性和身体状况相关属性,具体内容如下:
符号表示具体内容类别FAVC频繁食用高热量食物饮食习惯相关FCVC食用蔬菜频率饮食习惯相关NCP主餐数量饮食习惯相关CAEC两餐间食物消耗频率饮食习惯相关CH2O每日饮水量饮食习惯相关CALC饮酒量饮食习惯相关SCC卡路里消耗监测身体状况相关FAF身体活动频率身体状况相关TUE使用技术设备时间身体状况相关MTRANS使用交通工具身体状况相关family…weight家庭成员超重史其他NObeyesdad身体状况评价其他身高、体重等简单介绍略,Excel文档一览:

数据分为饮食习惯相关和身体状况相关,并且包含不同年龄。首先想到统计对象组内分析和饮食习惯和年龄的组间关系。
原数据给出了身体状况评价指标(NObeyesdad),但未给出详细计算公式,因此计划用BMI反映身体状况,分析饮食习惯和身体状况间关系。所以总结起来,任务就是:
统计样本对象特征饮食习惯间关系饮食习惯和身体状况间关系饮食习惯与身体状况间关系二、数据清洗
1.相关库调用
导入相关库:
import numpy as np ## 数据分析 import pandas as pd ## 数据分析 import matplotlib.pyplot as plt ## 画图 import seaborn as sns ## 可视化 1234
Seaborn的函数可选参数很多,图形简洁漂亮,往往一行就能生成热力图、散点图。
2.相关设置
设置数据小数点,忽略提醒,显示中文:
pd.options.display.float_format = '{:.2f}'.format#保留两位 import warnings ## 忽略提醒 warnings.filterwarnings('ignore') #plt中文显示问题 plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体 plt.rcParams['axes.unicode_minus'] = False # 解决保存图像显示为方块的问题 12345678
Matploblib默认无法使用中文,需要对中文进行设置,也可单独写个说明文件。刚开始使用时往往需要下载字体。可看这个(字体和本文程序放到本系列最后一个文档)
3.数据导入和清洗
导入数据,显示前五行观察是否导入成功
#数据导入 #df = pd.read_csv(r'D:\Pytharm\Practice\sjfenxilast\stib.csv') df = pd.read_csv(r'stib.csv')#相对路径 #Check print(df.head(5)) 12345
此处可使用相对路径或绝对路径。相对路径较好,当改变文件夹名时不用更改代码。

缺失与重复数据处理,此处最好再检查异常值的,这一步放后面了
#检查重复项和缺少值 print("\033[1;37m检查重复项和缺失值\033[0m") print(f'\033[94mNumber of records/rows & features/columns in the dataset are: {df.shape[0], df.shape[1]}') print(f'\033[94mNumber of duplicate entries in the dataset are: {df.duplicated().sum()}') print(f'\033[94mNumber missing values in the dataset are: {sum(df.isna().sum())}') ## 删除重复项 df.drop_duplicates(keep='first',inplace=True) ## 再次检查 print("\033[1;37m再次检查\033[0m") print(f'\033[94mNumber of records/rows & features/columns in the dataset are: {df.shape[0], df.shape[1]}') print(f'\033[94mNumber of duplicate entries in the dataset are: {df.duplicated().sum()}') 12345678910111213
为显示方便可设置文字颜色,具体见Python内容颜色输出。

第一次检查,存在24个重复项,不存在缺失值,因此仅对重复项进行处理。
如存在缺失值可使用以下代码进行处理:
## 检查缺失值 missing_val = df.isnull().sum()[df.isnull().sum() > 0] print('missing values by feature') print(missing_val) missing_val_prc = missing_val / len(df)*100 print('missing values by feature, by % of total') print(missing_val_prc) 1234567
若missing_val_prc(缺失比例)较少则直接舍去,太多就得考虑插入了。
检查数据类型
df.info() 1
为了查看数据是否存在空值以及确定数据类型方便后续操作。

相关数据无空值,处理完成。注意到年龄是float类型,可能存在很多小数,若建立年龄的相关分析得注意处理。对于数字型尽量不要弄成标签。
相关设置
#seaborn的颜色设置,或者直接用白色主题 #sns.set(style=’white‘) sns.set(rc={'axes.facecolor':'none','axes.grid':False,'xtick.labelsize':7,'ytick.labelsize':7, 'figure.autolayout':True, 'figure.dpi':180, 'savefig.dpi':180}) my_col = ('#40E0D0', '#D2B48C','#c7e9b4', '#EEE8AA','#00FFFF','#FAEBD7','#FF6347', '#FAFAD2', '#E0EEEE', '#C1CDCD', '#838B8B', '#D8BFD8','#F4A460', '#F08080', '#EE82EE', '#4682B4','#6A5ACD', '#00C78C', '#FFB6C1', '#8B5F65') 12345678
seaborn支持内置的显示风格,黑白什么的,见风格设置。本文直接设置col块并且手动初始化设置。
三、青年人饮食习惯分析
1.样本分析
为分析青年人饮食习惯,首先对统计对象进行简单查看。
df['Age'] = df['Age'].apply(int) #First,年龄、性别分布统计图 plt.figure(figsize=(12,9)) plt.subplot(211) plt.title('Gender', color='#8B5A2B', weight='bold', fontsize=14,fontproperties="SimHei") sns.countplot(x=df['Gender']) plt.subplot(212) plt.title('Age',color='green', weight='medium', fontsize = 8,fontproperties="SimHei") sns.countplot(df['Age'].value_counts().sort_values(), color='g', linewidth = 1) sns.countplot(x='Age',data=df) plt.savefig('性别年龄统计分布图',bbox_inches='tight') plt.show() 12345678910111213
由于看到年龄存在很多小数,首先对年龄取int型,忽略小数部分。样本主要特征是年龄和性别,查看两者属性分布:

可以看到男女比例基本相同,年龄大多分布在30岁以下,由此想到舍去30以上数据,做青年人相关分析。男女比例基本相同也不必再分两个样本了。
2.具体内容
分析青年人群饮食习惯
#Second,青年人饮食习惯与年龄,不同年龄饮水量CH2O、高热量食物FAVC、食用蔬菜FCVC #取30岁以下为研究对象 pd30 = df[df['Age'] < 31] plt.figure(figsize=(12,9)) plt.subplot(421) plt.title('Age',color='green', weight='medium', fontsize = 5,fontproperties="SimHei") sns.countplot(pd30['Age'].value_counts().sort_values(), color='g', linewidth = 1) sns.countplot(x='Age',data=pd30) #sns.stripplot(x = 'Age',y = pd30['Age'].value_counts().sort_values(),data = pd30) #sns.barplot(y = pd30['Age'].value_counts().sort_values(),x = 'Age',data = pd30,estimator= np.max) plt.subplot(422) plt.title('FAVC',color='#8B5A2B', weight='medium', fontsize=5,fontproperties="SimHei") sns.countplot(x=pd30['Age'], hue=pd30['FAVC'], palette=my_col, edgecolor = "black", saturation=1) #sns.catplot(x="Gender", y="Age",hue="CH2O", col="FAVC",data=pd30, kind="bar",height=4, aspect=.7) plt.legend(loc='upper right', fontsize=7) plt.xlabel(None), plt.ylabel(None) plt.subplot(423) plt.title('FCVC',color='#8B5A2B', weight='medium', fontsize=5,fontproperties="SimHei") sns.countplot(x=pd30['Age'], hue=pd30['FCVC'], palette=my_col, edgecolor = "black", saturation=1) #sns.barplot(x="day", y="total_bill", hue="sex", data=tips) plt.legend(loc='upper right', fontsize=7) plt.xlabel(None), plt.ylabel(None) plt.subplot(424) plt.title('CH2O',color='#8B5A2B', weight='medium', fontsize=5,fontproperties="SimHei") sns.countplot(x=pd30['Age'], hue=pd30['CH2O'], palette=my_col, edgecolor = "black", saturation=1) plt.legend(loc='upper right', fontsize=7) plt.xlabel(None), plt.ylabel(None) plt.savefig('青年人饮食习惯统计图',bbox_inches='tight') plt.show() # 喝水喝酒关系 plt.figure(figsize=(12,9)) sns.catplot(x="Gender", y="Age",hue="CH2O", col="FCVC",data=pd30, kind="bar",height=4, aspect=.7) plt.savefig('喝水和喝酒关系') plt.show()
12345678910111213141516171819202122232425262728293031323334353637383940首先将原数据进行展示,在比较几个指标间关系时,可选择条形图、密度图、散点图等。本文数据量较少可选柱状图、密度图,数据多散点图较好。注释部分为分类散点图。

喝水量与喝酒量间关系

本节也尝试了其他几类图像(文章程序无下图代码,均以饮食量为例,图一:displot)

四、青年人身体状况分析
1.指标选取
本节旨在反映样本身体状况。首先需要界定评价指标。
为反映各样本身体状况,自定义BMI=体重/身高平方,低于18.5为low…略然后分析各年龄段身体状况分布。
产生评价指标
#Second,青年人身体状况,不同年龄卡路里消耗SCC、身体活动频率FAF、BMI #BMI,BMI等于体重比身高,小于18.5过低,18.5到24正常,24到28超重,28以上肥胖 pd30['BMI']=((pd30['Weight'])/(pd30['Height']**2)).round(1) print(np.mean(pd30['BMI'])) print(np.mean(pd30['Weight'])) print(np.mean(pd30['Height'])) #创建BMIex作为BMI评价 pd30['BMIex'] = '' pd30.loc[pd30['BMI'] <= 18.5, 'BMIex'] = 'low' pd30.loc[(pd30['BMI'] > 18.5) & (pd30['BMI']<=24),'BMIex'] = 'Normal' pd30.loc[pd30['BMI'] > 24 & (pd30['BMI'] <= 28), 'BMIex'] = 'Overweight' pd30.loc[pd30['BMI'] > 28, 'BMIex'] = 'Fat' #FAF有很多小数得转化为几个整数形成标签 pd30['FAFex'] = '' pd30.loc[pd30['FAF'] <= 0, 'FAFex'] = 'Seldom' pd30.loc[(pd30['FAF'] > 0) & (pd30['FAF']<=2),'FAFex'] = 'Sometime' pd30.loc[pd30['FAF'] > 2, 'FAFx'] = 'Frequently'
123456789101112131415161718由于统计只能使用文本格式标签,需要将FAF形成文本内容。产生的BMIex指标和文档内给定指标(NObeyesdad)不同。
2.具体内容
统计各指标分布
## 画图,活动频率 plt.figure(figsize=(12, 9)) plt.subplot(311) plt.title('SCC',color='#8B5A2B', weight='medium', fontsize=5,fontproperties="SimHei") #sns.countplot(x=pd30['Age'], hue=pd30['SCC'], palette=my_col, edgecolor = "black", saturation=1) sns.histplot(data=pd30,x=pd30['Age'], hue="SCC", # 分组 stat="density", # 密度图(y轴刻度) element="poly") # 控制密度图显示方式 plt.xlabel(None), plt.ylabel(None) plt.subplot(312) plt.title('FAFex',color='#8B5A2B', weight='medium', fontsize=5,fontproperties="SimHei") #sns.countplot(x=pd30['Age'], hue=pd30['FAFex'], palette=my_col, edgecolor = "black", saturation=1) sns.histplot(data=pd30,x=pd30['Age'], hue="FAFex", # 分组 stat="density", # 密度图(y轴刻度) element="poly") # 控制密度图显示方式 plt.xlabel(None), plt.ylabel(None) plt.subplot(313) plt.title('BMIex',color='#8B5A2B', weight='medium', fontsize=5,fontproperties="SimHei") sns.countplot(x=pd30['Age'], hue=pd30['BMIex'], palette=my_col, plt.legend(loc='upper right', fontsize=7) edgecolor = "black", saturation=1) plt.xlabel(None), plt.ylabel(None) plt.savefig('青年人身体状况',bbox_inches='tight') plt.show()
1234567891011121314151617181920212223242526272829注意对直方图不可使用plt.legend设置图例,因为直方图通常用于表示单个变量的分布,而不涉及多个数据系列的比较。

3.身高体重数据检查
对数据分布可使用箱线图,小提琴图等进行观察,本部分主要使用箱线图。箱线图有给出数据误差等信息,方便排除异常值。
#居然没有正常的,身高体重数据很可能有问题检查一下,该部分方法很多,多尝试几个 plt.figure(figsize=(12,9)) plt.subplot(221) plt.title('Weight',color='#8B5A2B', weight='medium', fontsize=5,fontproperties="SimHei") sns.boxplot(x="Gender",y="Weight",hue="BMIex", data=pd30) plt.legend(loc='upper right', fontsize=7) plt.xlabel(None), plt.ylabel(None) plt.subplot(222) plt.title('Height',color='#8B5A2B', weight='medium', fontsize=5,fontproperties="SimHei") sns.boxplot(x="Gender",y="Height",hue="BMIex", data=pd30) plt.legend(loc='upper right', fontsize=7) plt.xlabel(None), plt.ylabel(None) plt.subplot(223) plt.title('Height',color='#8B5A2B', weight='medium', fontsize=5,fontproperties="SimHei") sns.boxenplot(x="Gender", y="Height",color="orange",hue = "BMIex", scale="linear", data=pd30) plt.legend(loc='upper right', fontsize=7) plt.xlabel(None), plt.ylabel(None) plt.subplot(224) plt.title('Weight',color='#8B5A2B', weight='medium', fontsize=5,fontproperties="SimHei") sns.boxenplot(x="Gender", y="Weight",color="orange",hue = "BMIex", scale="linear", data=pd30) plt.legend(loc='upper right', fontsize=7) plt.xlabel(None), plt.ylabel(None) plt.savefig('身高体重数据',bbox_inches='tight') plt.show()
123456789101112131415161718192021222324252627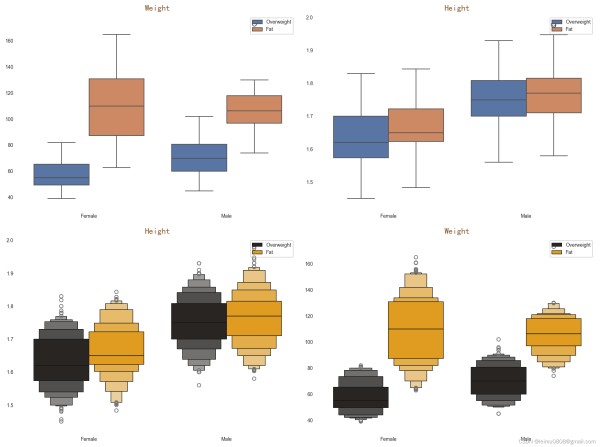
可对置信区间外数据进行删除
#删除异常值 wQ1 = pd30['Weight'].quantile(0.25) wQ3 = pd30['Weight'].quantile(0.75) wIQR = wQ3 - wQ1 lower_bound = wQ1 - 1.5 * wIQR upper_bound = wQ3 + 1.5 * wIQR #outliers = pd30['Weight'][(pd30['Weight'] < lower_bound) | (pd30['Weight'] > upper_bound)] #pd30_new = pd30['Weight'][~((pd30['Weight'] < lower_bound) | (pd30['Weight'] > upper_bound))] #pd30_new = df[df['Age'] < 31] pd30_new = pd30[pd30['Weight'] < lower_bound & pd30['Weight']>upper_bound] plt.figure(figsize=(12,9)) plt.subplot(221) plt.title('Weight',color='#8B5A2B', weight='medium', fontsize=5,fontproperties="SimHei") #sns.boxplot( y=pd30['Weight'] ) sns.boxplot(x="Gender",y="Weight",hue="BMIex", data=pd30_new) plt.legend(loc='upper right', fontsize=7) plt.xlabel(None), plt.ylabel(None) plt.show()
1234567891011121314151617181920五、几个相关性
最后对几个属性间相关信进行分析
#作热力图需转换为数值型 #pd30.loc[pd30['NCP'] == 'One', 'NCPnum'] = 1 #pd30.loc[pd30['NCP'] == 'Two', 'NCPnum'] = 2 #pd30.loc[pd30['NCP'] == 'Three', 'NCPnum'] = 3 #几个相关性,热力图部分未画可看注释 #pd30_FAFNCP = pd30[['FAF','NCPnum','Height']] ## 热力图需形成新数组 plt.figure(figsize=(12,9)) plt.subplot(221) plt.title('交通工具和体重',color='#8B5A2B', weight='medium', fontsize=5,fontproperties="SimHei") #sns.boxplot( y=pd30['Weight'] ) #sns.swarmplot(x="MTRANS",y="Age",data=pd30) sns.swarmplot(x=pd30["MTRANS"], y=pd30["Weight"],hue=pd30['BMIex'],data=pd30) #plt.legend(loc='upper right', fontsize=7) plt.xlabel(None), plt.ylabel(None) plt.subplot(222) plt.title('活动频率和身高',color='#8B5A2B', weight='medium', fontsize=5,fontproperties="SimHei") #sns.stripplot(x="SCC",y="Age",data=pd30) sns.swarmplot(x=pd30["FAF"], y=pd30["Height"],hue = pd30['BMIex'], data=pd30) #plt.legend(loc='upper right', fontsize=7) plt.xlabel(None), plt.ylabel(None) """ ## 热力图,最后是两个多值数组,本数据FAF才3个值不好看 plt.subplot(223) plt.title('sj',color='#8B5A2B', weight='medium', fontsize=5,fontproperties="SimHei") sns.heatmap(pd30_FAFNCP,vmin=0,vmax=1) plt.legend(loc='upper right', fontsize=7) plt.xlabel(None), plt.ylabel(None) """ plt.subplot(223) plt.title('主餐数量和身高',color='#8B5A2B', weight='medium', fontsize=5,fontproperties="SimHei") sns.violinplot(x=pd30["NCP"], y=pd30["Height"]) #plt.legend(loc='upper right', fontsize=7) plt.xlabel(None), plt.ylabel(None) plt.subplot(224) plt.title('主餐数量和体重',color='#8B5A2B', weight='medium', fontsize=5,fontproperties="SimHei") sns.violinplot(x=pd30["NCP"], y=pd30["Weight"]) #plt.legend(loc='upper right', fontsize=7) plt.xlabel(None), plt.ylabel(None) plt.savefig('几个相关性',bbox_inches='tight') plt.show()
12345678910111213141516171819202122232425262728293031323334353637383940414243444546上图使用散点图,下图使用小提琴图。小提琴图更能反映数据内关系。

总结
本文通过饮食习惯与身体健康指标练习了seaborn相关函数使用。涉及基本数据清洗,数据分析、可视化内容,是对本科阶段Python数据分析学习的小结。
自学之路颇多弯路,笔者既因一次次错误而懊悔,也因一次次尝试后发现新的路径而快乐,探索而乐在其中。笔者是电气专业,对我而言,数据分析能力注定只能成为工具,也将以切实、高效使用为目的。
这是第一篇编程类文章分享,也期待26号的研究生出分顺利!
网址:Python数据分析:对饮食与健康数据的分析与可视化 https://www.yuejiaxmz.com/news/view/177600
相关内容
Python中的生活数据分析与个人健康监测.pptx生活中的什么数据可以做数据分析
Python数据分析实战
python excel数据分析师职业技能
个人生活的量化分析(二):Apple健康数据分析
数据分析实战:利用python对心脏病数据集进行分析
python数据分析
如何通过自我量化改善生活质量:数据采集与分析方法全解析
基于Python的中华美食菜谱可视化分析(论文+源码)
人人都是数据分析师:到底什么是数据分析?如何进行数据分析?
随便看看
最新动态分享
- 素食养生有什么好处和坏处
- 过上充满活力的生活:纯素饮食有利于长寿和幸福
- 女人吃素食的好处与坏处
- 老年人适当吃素有哪些好处
- 采用纯素饮食对环境和健康的好处
- 常吃素对人体有好处:可抗癌长寿
- 纯素饮食对健康的益处:您需要了解的内容
- 科学证明:多吃素还是很有好处的!
- 经常吃素食有哪些好处?有4大惊喜等着你
- 女人长期吃素食的好处 你知道几个
热点动态分享
- 2113
- 2017
- 1909
- 1801
- 1457
- 1419
- 1411
- 1241
- 1115
- 1107

