语音识别(一):介绍和简单实现
科技产品语音助手的实用功能介绍 #生活技巧# #创意技巧# #科技产品使用技巧#
1. 语音识别介绍
语音识别的最主要过程是:
特征提取:从声音波形中提取声学特征;声学模型(语音模型):将声学特征转换成发音的音素;语言模型使用语言模型等解码技术转变成我们能读懂的文本。语音识别系统的典型结构如图1所示:
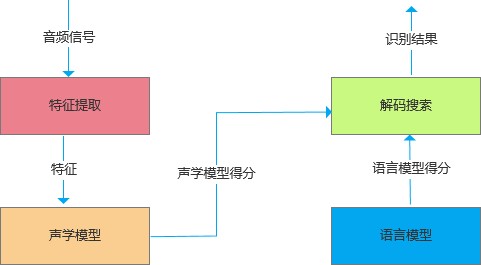 图1 语音识别结构
图1 语音识别结构 1.1 声学特征提取
声音实际上一种波,原始的音频文件叫WAV文件,WAV文件中存储的除了一个文件头以外,就是声音波形的一个个点。如图2所示:
 图2 声音波形示意图
图2 声音波形示意图 要对声音进行分析,首先对声音进行分帧,把声音切分成很多小的片段,帧与帧之间有一定的交叠,如图3,每一帧长度是25ms,帧移是10ms,两帧之间有25-10=15ms的交叠。
 图3 帧切割图
图3 帧切割图 分帧后,音频数据就变成了很多小的片段,然后针对小片段进行特征提取,常见的提取特征的方法有:线性预测编码(Linear Predictive Coding,LPC),梅尔频率倒谱系数(Mel-frequency Cepstrum),把一帧波形变成一个多维向量的过程就是声学特征提取。
1.2. 声学特征转换成音素(声学模型)
音素是人发音的基本单位。对于英文,常用的音素是一套39个音素组成的集合。对于汉语,基本就是汉语拼音的生母和韵母组成的音素集合,大概200多个。本文例子中LSTM+CTC神经网络就是声学特征转换成音素这个阶段,该阶段的模型被称为声学模型。
1.3. 音素转文本(语言模型+解码)
得到声音的音素序列后,就可以使用语言模型等解码技术将音素序列转换成我们可以读懂的文本。解码过程对给定的音素序列和若干假设词序列计算声学模型和语言模型分数,将总体输出分数最高的序列作为识别的结果。
2. 语音识别简单实现
本文通过一个简单的例子演示如何用tensorflow的LSTM+CTC完成一个端到端的语音识别,为了简化操作,本例子中的语音识别只训练一句话,这句话中的音素分类也简化成对应的字母(与真实因素的训练过程原理一致)。计算过程如下图所示:
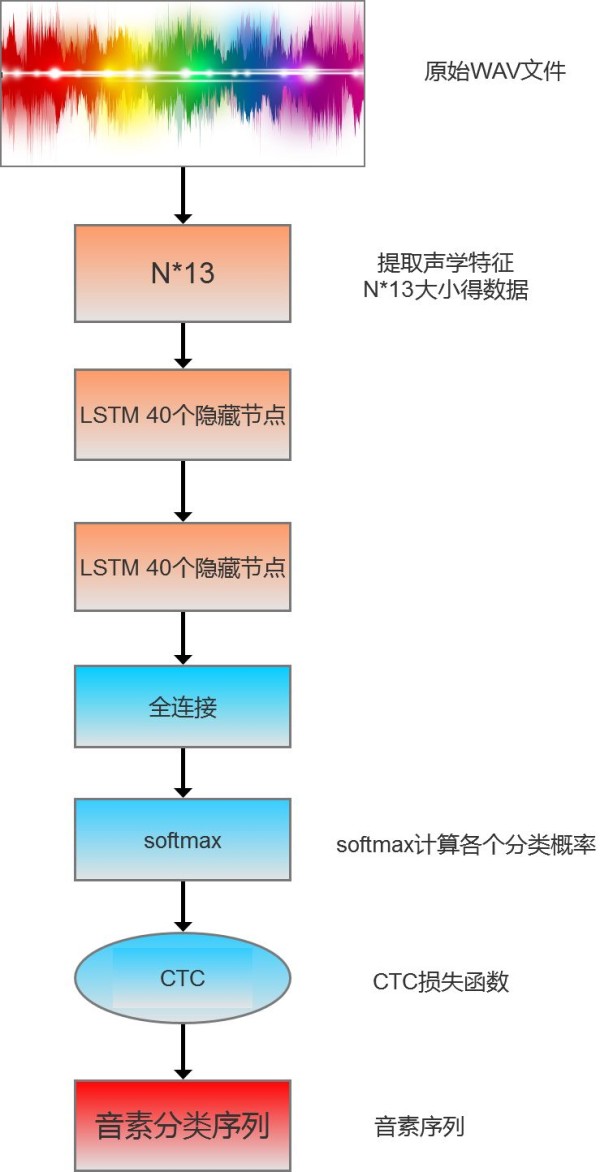
2.1 提取WAV文件中特征
首先读者肯定会有疑问?什么是WAV文件?笔者在此简单的介绍一下,WAV格式是微软公司开发的一种声音文件格式,也叫波形声音文件,是最早的数字音频格式,被Windows平台及其应用程序广泛支持,是一种无损的音频数据存放格式。
本文在读取WAV的特征数据后,采用python_speech_features包中的方法来读取文件的MFCC特征,详细代码如下:
def get_audio_feature():
'''
获取wav文件提取mfcc特征之后的数据
'''
audio_filename = "audio.wav"
fs, audio = wav.read(audio_filename)
inputs = mfcc(audio, samplerate=fs)
feature_inputs = np.asarray(inputs[np.newaxis, :])
feature_inputs = (feature_inputs - np.mean(feature_inputs))/np.std(feature_inputs)
feature_seq_len = [feature_inputs.shape[1]]
return feature_inputs, feature_seq_len
函数的返回值feature_seq_len表示这段语音被分割成了多少帧,一帧数据计算出一个13维长度的特征值。返回值feature_inputs是一个二维矩阵,矩阵行数是feature_seq_len长度,列数是13。
2.2 将WAV文件对应的文本文件转换成音素分类
本文音素的数量是28,分别对应26个英文字母、空白符和没有分到类情况。WAV文件对应的文本文件的内容是she had your dark suit in greasy wash water all year。现在把这句话转换成整数表示的序列,空白用0表示,a-z分别用数字1-26表示,则转换的结果为:[19 8 5 0 8 1 4 0 25 15 21 18 0 4 1 18 110 19 21 9 20 0 9 14 0 7 18 5 1 19 25 0 231 19 8 0 23 1 20 5 18 0 1 12 12 0 25 5 118],最后将整个序列转换成稀疏三元组结构,这样就可以直接用在tensorflow的tf.sparse_placeholder上。转换代码如下:
with open(target_filename, 'r') as f:
line = f.readlines()[0].strip()
targets = line.replace(' ', ' ')
targets = targets.split(' ')
targets = np.hstack([SPACE_TOKEN if x == '' else list(x) for x in targets])
targets = np.asarray([SPACE_INDEX if x == SPACE_TOKEN else ord(x) - FIRST_INDEX
for x in targets])
train_targets = sparse_tuple_from([targets])
print(train_targets)
return train_targets
2.3 定义双向LSTM
定义双向LSTM及LSTM之后的特征映射的代码如下:
def inference(inputs, seq_len):
cell_fw = tf.contrib.rnn.LSTMCell(num_hidden,
initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.1),
state_is_tuple=True)
cells_fw = [cell_fw] * num_layers
cell_bw = tf.contrib.rnn.LSTMCell(num_hidden,
initializer=tf.random_normal_initializer(
mean=0.0, stddev=0.1),
state_is_tuple=True)
cells_bw = [cell_bw] * num_layers
outputs, _, _ = tf.contrib.rnn.stack_bidirectional_dynamic_rnn(cells_fw, cells_bw, inputs,
dtype=tf.float32,
sequence_length=seq_len)
shape = tf.shape(inputs)
batch_s, max_timesteps = shape[0], shape[1]
outputs = tf.reshape(outputs, [-1, num_hidden])
W = tf.Variable(tf.truncated_normal([num_hidden,
num_classes],
stddev=0.1))
b = tf.Variable(tf.constant(0., shape=[num_classes]))
logits = tf.matmul(outputs, W) + b
logits = tf.reshape(logits, [batch_s, -1, num_classes])
logits = tf.transpose(logits, (1, 0, 2))
return logits
2.4 模型训练和测试
最后将读取数据、构建LSTM+CTC网络及训练过程结合起来,在完成500次迭代训练后,进行测试,并将结果输出,部分代码如下:
def main():
inputs = tf.placeholder(tf.float32, [None, None, num_features])
targets = tf.sparse_placeholder(tf.int32)
seq_len = tf.placeholder(tf.int32, [None])
logits = inference(inputs, seq_len)
loss = tf.nn.ctc_loss(targets, logits, seq_len)
cost = tf.reduce_mean(loss)
训练过程及结果如下图:

从上图训练结果可以清洗的看出经过500次的迭代训练,语音文件基本已经可以完全识别,本例只演示了一个简单的LSTM+CTC的端到端的训练,实际的语音识别系统还需要大量训练样本以及将音素转换成文本的解码过程。后续文章中,笔者会继续深入语音识别。
网址:语音识别(一):介绍和简单实现 https://www.yuejiaxmz.com/news/view/312178
相关内容
语音识别技术介绍语音识别技术介绍.ppt
《语音识别技术介绍》课件.ppt
语音识别语言模型介绍
语音识别实现
tensorflow 1.9.0 语音识别简单实现
人工智能:语音识别技术介绍
简要介绍语音识别技术在各领域的应用
语音识别与语音助手:机器学习的生活实践1.背景介绍 语音识别和语音助手技术在过去的几年里发生了巨大的变化。从单一功能的应
构建智能语音助手应用:语音识别和语音合成的实践
随便看看
最新动态分享
- 欢乐尽在户外游乐:体验自然,释放心情
- 开展户外幼儿自主性游戏的实践与思考
- 2025宁波春季户外运动嘉年华:你知道会有什么意外惊喜吗?
- 户外精神到底是什么?这8点便是我们的初衷
- 《2022新中产户外生活方式报告》
- 破解青年群体生活方式,《出发!趣野吧》以户外新潮流引领内容创新
- 浅谈户外活动对幼儿健康发展价值
- 探秘户外运动的激情与挑战:活力四射的风景线
- 【大话户外】户外运动与中国传统文化的“山水情结”
- 写在第18个“全民健康生活方式日”——让孩子到户外撒欢去
热点动态分享
- 2815
- 2689
- 2583
- 2349
- 2205
- 1835
- 1651
- 1499
- 1390
- 1312

