基于深度学习的盲人行路辅助软件设计
利用科技辅助,如编程、设计软件等 #生活技巧# #学习技巧# #创造力培养#
基于深度学习的盲人行路辅助软件设计
Design of Walking Assistance Software for Blind People Based on Deep Learning
1. 引言
在当代社会,盲人很难在没有辅助的情况下生活出行,而中国视障人数约占世界视障人数的20% [1]。随着科技的发展,各国都致力于增强盲人与世界的互动,各种智能辅具层出不穷 [2] [3] [4],让盲人的出行有了多种选择。但普通的导盲杖智能化低,获取信息的范围和广度存在限制,不能达到全面的导盲需求;传统的RFID导盲技术 [5] 识别精度不高,普及性差;一些智能导盲辅具造价高,往往难以大规模投入使用,且大多设备只能对静态障碍示警,无法分析动态障碍的运动趋势,难以实现实时警报,盲人出行仍存有安全隐患。因此,开发低成本、实时性、高便携和高精度的盲人辅助行路系统有很高的现实意义。
为了关爱盲人群体,改善目前导盲工具落后的欠缺,本文提出了一种结合计算机视觉(Computer Vision, CV)和自然语言处理(Natural Language Processing, NLP)的盲人辅助行路的软件设计方案,利用视频检测技术实现实时检测过往车辆、行人以及障碍物,分析其所处位置,并对检测出的目标进行话术丰富,再基于语音合成技术将检测到的周围目标进行实时播报,为盲人提供相应的语音辅助指导,测试结果表明,上述系统能够以低成本的方法实现提高实用性、保障用户安全并且增加测障精度,使得盲人出行与生活更加方便。
2. 软件整体设计思路
2.1. 设计思路
针对目前导盲设备存在的问题,本系统主要从目标检测和语音合成两个方面进行设计。
环境信息获取的方式包括视觉感知和声音感知。视觉感知用于识别物体和获取物体位置,它依赖于物体检测。而视觉目标跟踪算法中的基于孪生网络(Siamese) [6] 系列的跟踪方法主要应用于单目标跟踪,并且多目标跟踪的深度学习网络在成熟度和实时性上都难以达到“导盲”所需的标准,因此目标检测技术相较于目标跟踪技术更适用于“导盲”领域。随着算法的成熟,出现了RCNN [7]、Faster R-CNN [8]、SSD [9]、Yolo [10] 等主流算法,其中Yolov3 [11] 在识别精度和速度方面都有着优秀的表现,对小目标的检测尤为精确,处理器和GPU并行运算更是加快了检测速度,实时性满足本设计的需求。并且通过在Yolov3中加入空洞卷积(Dilated/Atrous Convolution) [12] 来改进网络结构,代替下采样/上采样,在扩大感受野的同时保留输出特征图分辨率。
声音感知主要基于语音合成播报,选用端到端的Tacotron神经网络模型 [13],采用seq2seq + attention结构,以字符作为输入,将输入的文本输出为音频波形。通过两者结合实现通过实时视频输入来检测周围环境,并经过检测到的周围目标以语音播报的形式对盲人做出引导,提供语音辅助。
2.2. 软件设计流程
软件设计流程主要分为三个部分:1) 目标检测,2) 文本丰富,3) 语音合成。前期数据预处理主要包含视频流的帧抓取,经过Yolov3检测后的信息通过筛选和小目标抑制操作后,将清洗过的数据凝练成关键词送入文本丰富模块,经过时间间隔重复操作达到实时检测播报的效果。经过模拟盲人测试,得到每5秒钟截取一帧视频数据作为输入为宜,首先,因为盲人的行进速度较慢,场景内的目标变化不会产生十分剧烈的情况;其次,每句语音播报需要一定时间,五秒的间隔足以完成“目标识别–文本丰富–语音播报”的多模态流程。详细流程如图1软件结构所示。
3. 关键技术研究
3.1. 目标检测模块
为了契合本设计对于实时性和多目标检测的要求,本设计采用Yolov3算法,将检测问题转化为识别与回归问题。下面通过三个方面介绍Yolov3算法的核心思想:
1) 特征提取方式
相较于Faster R-CNN模型使用候选区域来提取特征,Yolov3则选用整图进行训练,这样能够在速度加快的同时,更好的区分背景区域和目标。本设计还使用空洞卷积代替下采样/上采样,引入超参数扩张率(dilation rate)来定义卷积核处理数据时各值的间距,不仅保留了图像的空间信息,还避免了下采样那样造成信息损失,改善了网络结构。
2) 网络预测方式
Yolov3以端到端的检测来预测图像,将输入图像分为S * S个网格,相应网络会对中心落在该格内的目标进行检测,每个单元格为每个bounding box (预测区域)预测四个参数:中心偏移量(xi, yi),宽高缩放比(tw, th),根据Yolo模型训练完成后给出的一组标签来判断需要播报的目标及其位置信息通过逻辑回归得到置信度,用来反映当前边界框存在目标的可能性和准确度,如果当前区域有对象存在时,预测目标类别并打上标签。
3) 网络模型
Yolov3作为一个大型的深度卷积神经网络模型,遵循GoogleNet [14] 思想,但区别在于采用了更快速精准的Darknet-53网络结构(包含53个全连接层)。当输入为一张256 * 256大小的图片,则在32、16和8维降采样时进行检测,使用1 * 1和3 * 3的卷积核分别用于降维和特征提取,最终输出大、中、小三个尺度,且三个尺度间存在联系。最后通过置信度大小做逻辑回归,得到预测结果。整体网络结构如图2。
最后根据模型训练完成后给出的一组标签来判断需要播报的目标及其位置信息,首先对于视频流进行帧抓取,再通过位置信息与抓取帧宽度,判断目标分区,由目标大小辨别目标远近,并在判断过程加入对应识别物的标签作为权重。
3.2. 语音合成模块
选用端到端的Tacotron神经网络模型,它包含一个编码器,一个含注意力机制的解码器 [15] 和一个后处理器,核心是seq2seq + attention结构,它以字符作为输入,生成频谱图,并将其转换为波形,而后使用Griffin-Lim算法生成对应音频,将文本合成语音,可以仅通过< 文本,声谱 >数据对随机开始训练。模型结构如图3。
其中CBHG模块用于提取文本特征,包含一维卷积滤波器、一个Highway Networks和一个双向GRU。输入序列先经过卷积层,它有K个一维卷积核,卷积核个数分别为C1 − CK,宽度分别为1 − K,对本身以及上下文信息进行有效建模,再将结果堆叠,沿时轴做最大池化以增加局部不变性,使用stride = 1来保留时间上的分辨率。后经由两个一维卷积层,输出通过残差连接与原始输入序列求和,卷积后的结果经过高速网络中提取高维特征,最后在顶部加入双向GRU,得到最终序列特征。
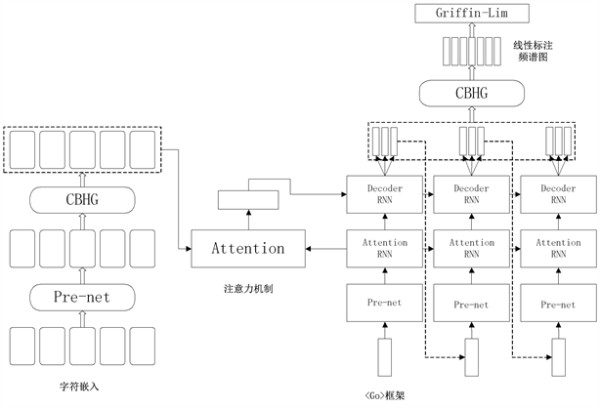
Figure 3. Tacotron model architecture
图3. Tacotron模型结构
编码器对输入进行非线性变换。输入是用独热向量编码后嵌入至一个连续向量中的字符序列,通过由全连接层和dropout组成的pre-net进行预处理,可加速收敛并提高泛化能力。然后将输出的连续向量送入CBHG子网络,得到注意模块的最终编码器表示。
解码器主要有两个模块,Attention-RNN包含256个GRU,使用Bahdanau attention机制,生成查询向量,做为输入经过attention模块生成文本向量,Decoder-RNN为两层residual GRU,它将前一阶段产生的查询向量和文本向量拼接作为输入,输出为输入与经过GRU单元输出的和。为了加快收敛速度,还通过生成80波段的梅尔频谱图代替直接生成语谱图,在减少计算量的同时保证了最终波形的质量。
后处理网络将seq2seq目标转换为可以合成为波形的目标。先由CBHG模块将上一层产生的梅尔频谱图转换为线性频谱图,然后利用Griffin-Lim算法在不改变左右和相邻的幅度谱的情况下,在一个线性频率范围内预测频谱幅度,将后处理网络的输出合成为时域语音信号。
4. 技术实现
4.1. 视频数据提取关键目标信息
首先是数据预处理过程,为了方便测试,本设计了两种输入方式:摄像头输入和mp4视频输入。首先将输入的视频数据赋给变量“video”;通过video.read()将视频数据读取为一帧图片并赋值给变量“frame”;然后转变其格式(BGRtoRGB),从而完成视频数据处理。
Yolov3经过特征提取网络以及预选框操作等,得到一个回归框,每个回归框由5个预测值组成:中心偏移量(xi, yi),宽高缩放比(tw, th)和置信度,可以通过感受野映射回原图从而找到目标。
当前帧“frame”包含的信息会以图4的形式被提取。包含其标签和4个位置信息,而后通过位置信息xi、yi与抓取帧宽度的一半做差,得到方位值Z,若Z值小于零则代表目标物位于视角的左半区;反之则代表目标位于右半区。接着通过目标大小tw * th来判断目标物距离视角的远近,在判断过程中会加入对应识别物的标签作为权重,如car的权重为0.5,person的权重为1,dog的权重为2。
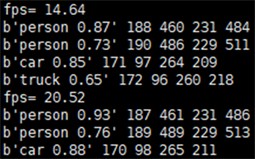
Figure 4. Yolov3 information extraction display
图4. Yolov3信息提取展示
4.2. 文本丰富及语音合成
在文本丰富模块中,采用由代码生成固定句式,自动填充经过视频检测模块识别出的标签以及位置信息,然后保存到txt文档中。
在语音合成模块中,使用THCHS-30数据集,对其进行预处理,生成各个音频文件的梅尔频谱和线性频谱,其中train.txt文件中存放有csv格式的声谱与拼音标注对。npy文件使用numpy库加载后能够得到数个多维矩阵,用于提取语音的声学特征。
最后的训练效果可以通过观察alignment图中的编解码器序列对齐情况,来判断学习是否收敛。
在测试环节中,由于无法直接输入汉字文本,且经由文本生成模块中生成的话术格式为txt格式,所以需要使用python-pinyin将汉字文本转换为拼音标注,然后拷贝到eval.py生成后缀为wav的音频,最后使用python-pydub进行音频播放。
5. 模型训练
本实验的操作系统为Ubuntu 18.04.1,使用NVIDIA GeForce v100 32G GPU进行训练,程序运行框架为tensorflow1.14.0平台。首先使用VOC数据集对Yolov3网络进行预训练,在V100上经过500轮的迭代后保留其权重。
通过Yolo-mark 工具标注部分针对性数据,用矩形框标记数据集图片上的物体,完成后在img文件夹下会生成与jpg文件同名的txt文件,里面每一行代表一个物体的类的编号,以及标记物体的坐标。如图5 (其中每一行的数据分别代表了:< 物体类的编号 > < x_center > < y_center > < width > < height >)。
对于Tacotron模型的训练,语料库采用由清华大学开放的THCHS-30汉语普通话语料,数据采样率为16 KHz,样本宽度为16-bit,单声道。在该语料库中每条音频都有对应的两个文件,分别是后缀为wav的音频文件以及后缀为trn的标注文件。其中,不同的语言标注方法不同,如英文标注可以直接使用自己本身加标点符号,而由于中文的多样性,通常使用拼音做标注,如图6所示。
在训练之前,对数据进行预处理,生成各个音频文件的梅尔频谱和线性频谱,其中的npy文件使用numpy库加载,得到数个多维矩阵,用于提取语音的声学特征。得到< 文本,声谱 >数据对形式后开始训练。训练中解码步骤使用真实的梅尔谱图,并使用Teacher Forcing的方式来减少误差。

Figure 5. Labeling part of the targeted data display
图5. 标注部分针对性数据展示

Figure 6. Character annotation display
图6. 字符标注展示
经过92,000次迭代,生成的alignment图如图7所示,图中对齐情况较好,训练基本符合预期。
6. 系统演示
训练结束后,在动态视频中显示对于多目标判断的标签以及准确率。每隔五秒抓取一帧进行目标识别,提取标签以及目标位置信息,当(目标尺寸 * 对应标签的权值)小于600时系统判定该目标过小,转换文本过程会忽略过小的目标,每次抓取帧经过判断转换操作会以覆盖的形式生成test.txt文本并由语音转换程序不断播报。经过测试,该系统能够实时检测静态和动态障碍物,提高佩戴者的环境感知能力,另一方面,能够对出现的障碍物等目标进行话术丰富,通过语音实时播报障碍物及其位置进行语音预警,实现人机交互。使佩戴者能够在无人引导的情况下了解环境,安全出行。
系统软件演示如图8所示。
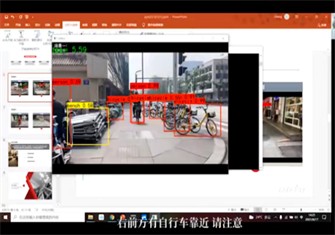
Figure 8. System software display
图8. 系统软件显示
其中,图9展示了视角中出现车辆和行人的情况和其对应的转换文本。

Figure 9. Video detection block diagram and corresponding converted text
图9. 视频检测框图与对应转换文本
图10展示了视角中出现车辆靠近的情况(行人目标过小被忽略)和其对应的转换文本。

Figure 10. Video detection block diagram and corresponding converted text
图10. 视频检测框图与对应转换文本
图11展示了视角中出现狗的情况和其对应的转换文本。
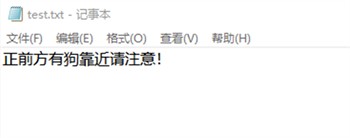
Figure 11. Video detection block diagram and corresponding converted text
图11. 视频检测框图与对应转换文本
7. 总结
本文提出了一种结合计算机视觉和自然语言处理的盲人辅助行路的软件设计,从视频检测算法、文本丰富、语音合成三个方面进行方案设计,利用Yolov3算法实现实时检测过往车辆、行人以及障碍物的功能,使用文本丰富模块对检测出的车辆等目标进行话术丰富,再使用基于Tacotron模型的语音合成技术对周围目标进行语音播报。三者结合,构成了盲人辅助行路系统的框架,经过测试表明,本设计方案符合低成本、实时性、高精度要求,已在第16届研究生电子设计竞赛中获奖,有一定的应用价值与参考意义。
NOTES
*通讯作者。
网址:基于深度学习的盲人行路辅助软件设计 https://www.yuejiaxmz.com/news/view/328478
相关内容
Dew./盲人出行辅助系统激光雷达辅助导航:科技赋能,盲人独立出行新篇章
盲人出行挑战与曙光:“盲人视觉辅助技术研发”助力无障碍生活
老年人无障碍设计现状与前景分析——基于生活辅助产品
【教育学习软件大全】教育学习软件排行榜
毕业设计:基于深度学习的商品个性化推荐系统
有哪些自律辅助生活软件
盲人如何使用手机:实用技巧与辅助工具指南
盲人出行助手:帮助盲人解决通勤路上的问题
盲人辅助设备赋能视障人士,实时导航与避障打造无障碍生活
随便看看
最新动态分享
- 老年人营养品排名前十名
- 形容简单生活的句子(通用330句)
- 简单的日子,简单过
- 什么是简单生活
- 简单的生活作文
- 简单生活作文 简单生活作文(模板十一篇)
- 简单的生活的句子集合55条
- 简单生活作文(推荐16篇)
- 有关简单生活的作文五篇
- 简单的生活的句子汇编39条
热点动态分享
- 452
- 291
- 273
- 217
- 202
- 178
- 158
- 141
- 117
- 106

