
Beatifulsoup中文文档:http://beautifulsoup.readthedocs.io/zh_CN/latest/
Requests官方文档(中文):http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
一、解析网页中的元素
beatifulsoup

右键copy selector或xpath,描述元素在网页中的什么位置什么位置

对xpath的理解
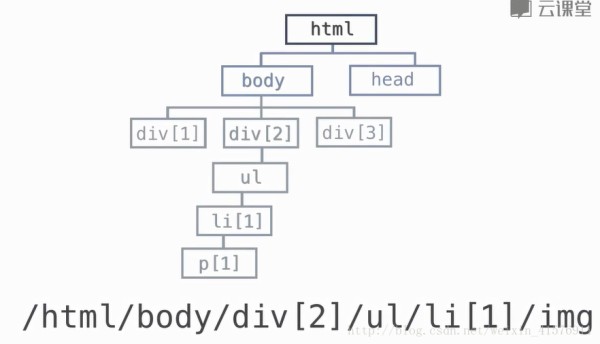
练习1
from bs4 import BeautifulSoup
import urllib
url = "http://www.mmjpg.com/"
html = urllib.request.urlopen(url)
response = html.read()
soup = BeautifulSoup(response,'lxml')
images = soup.select('body > div.main > div.pic > ul > li > a > img')
titles = soup.select('body > div.topbar > div.subnav > a')
for image in images:
print(image.get('src'))
练习2
from bs4 import BeautifulSoup
import requests
import time
url_saves = 'http://www.tripadvisor.com/Saves#37685322'
url = 'https://cn.tripadvisor.com/Attractions-g60763-Activities-New_York_City_New_York.html'
urls = ['https://cn.tripadvisor.com/Attractions-g60763-Activities-oa{}-New_York_City_New_York.html#ATTRACTION_LIST'.format(str(i)) for i in range(30,930,30)]
headers = {
'User-Agent':'',
'Cookie':''
}
def get_attractions(url,data=None):
wb_data = requests.get(url)
time.sleep(4)
soup = BeautifulSoup(wb_data.text,'lxml')
titles = soup.select('div.property_title > a[target="_blank"]')
imgs = soup.select('img[width="160"]')
cates = soup.select('div.p13n_reasoning_v2')
if data == None:
for title,img,cate in zip(titles,imgs,cates):
data = {
'title' :title.get_text(),
'img' :img.get('src'),
'cate' :list(cate.stripped_strings),
}
print(data)
def get_favs(url,data=None):
wb_data = requests.get(url,headers=headers)
soup = BeautifulSoup(wb_data.text,'lxml')
titles = soup.select('a.location-name')
imgs = soup.select('div.photo > div.sizedThumb > img.photo_image')
metas = soup.select('span.format_address')
if data == None:
for title,img,meta in zip(titles,imgs,metas):
data = {
'title' :title.get_text(),
'img' :img.get('src'),
'meta' :list(meta.stripped_strings)
}
print(data)
for single_url in urls:
get_attractions(single_url)
'''
headers = {
'User-Agent':'', #mobile device user agent from chrome
}
mb_data = requests.get(url,headers=headers)
soup = BeautifulSoup(mb_data.text,'lxml')
imgs = soup.select('div.thumb.thumbLLR.soThumb > img')
for i in imgs:
print(i.get('src'))
'''
二、如何获得网页中的异步加载数据
点击XHR,在网页中下拉加载数据


