企研数据工作论文系列
论文附录:详细列出所有数据和方法,供读者查阅 #生活技巧# #学习技巧# #学术论文写作#
更多详情请点击查看原文:企研数据工作论文系列 | 中国绿色低碳技术专利数据清洗与质量分析报告
目录
一、引言
二、专利数据简介
三、绿色低碳专利清洗依据与基本思路
(一)参考文件
(二)清洗目标
(三)数据预处理
1. 规范化表达
2. 处理IPC分类号
3. 处理参考检索式
(四)数据清洗思路
四、数据整合
五、结论和进一步讨论
参考文献
附录
本报告篇幅较长,如您需阅览 PDF 版请在公众号后台回复关键词 “WP0008” 获取。
中国绿色低碳技术专利数据清洗与质量分析报告
摘要:本文对中国绿色低碳技术专利数据的清洗过程进行了详细阐述,包括原始专利数据来源、清洗参考文件、数据预处理的方法和数据处理的详细步骤。特别强调了不能仅根据国家知识产权局公布的《绿色低碳技术专利分类体系》中提供的IPC分类号识别绿色低碳技术专利,必须要考虑参考检索式的限制条件。利用更新到2022年底的专利数据分析发现,中国绿色低碳技术专利的申请数量约为134万条,并且在1985-2022年整体呈上升趋势。
关键词:绿色低碳技术专利;数据清洗;IPC分类号;参考检索式
一、引言
在经济学实证研究中,研究数据的质量是保证分析结果可信从而有意义的基础。然而,经济学界,乃至整个社科领域,研究结果的可信性常常因为实证结果无法复现而频受质疑。造成这一问题的原因之一是数据问题,包括数据来源的不统一和清洗处理过程的不公开不透明。为提高经济学实证研究论文结果的公信力,近年来国内各大经济学期刊也都开始推动数据资源、数据处理过程和实证分析代码的对外公开。截止至2023年12月,国内已有《中国工业经济》《经济学季刊》《世界经济》《管理世界》《财贸经济》以及农经“四大刊”等20本左右的国内核心期刊先后要求或鼓励投稿人公布论文原始数据及代码[1],这既是经济学研究可信性革命的必由之路,也是营造公开、透明的学术研究环境的关键要求。
[1] 以《财贸经济》为例,要求公开的实证论文原始数据包括:①使用国家统计局、国际组织、已出版统计资料等公开数据(包括由第三方数据库检索导出,但以公开数据为来源的格式化数据)的,要求至少提交能与程序代码匹配,能够得到文中报告结果(含图表、注释、附录)的变量名称及说明。②倡导和鼓励提供经过整理并能够直接用于程序运行的数据集。③使用收费数据、非公开数据、作者自采数据等其他情形的,要求至少提交用以得到本文报告的必要变量名称说明、数据获取过程。④倡导和鼓励提交经脱敏处理或保留少量样本(不至于引起版权纠纷、无泄密风险)的数据集,用以帮助理解代码。
近年来,随着科研领域数据服务行业的兴起,各类行政大数据、互联网大数据获得成本大幅度下降,许多研究开始大量使用行政大数据或互联网大数据等非标准化数据(标准化数据的典型代表是官方公布的统计数据),但由于大量(廉价)购买到的科研数据来源不明,也并未提供详细的数据处理过程说明,或只提供简单说明,特别是对来源和具体的处理过程语焉不详或一笔带过,这使得直接购买、使用处理好的数据集的学者,无法在投稿的论文中提供这些数据集来源可靠性和处理过程合理性的强有力的说明,从而大大削弱了其研究成果的说服力,降低了论文被接受的概率。
更令人遗憾的是,大量最后被接受并发表的论文,因为数据本身的处理过程受到质疑而使其已经发表的研究成果仍然缺乏公信力。甚至我们会发现有些相同主题的研究尽管从名称上看用的是同一套原始数据,但具体来源不同(从而无法保证数据处理过程的一致性),可能会得出不同的研究结果。这会导致学者大量精力的浪费,以及中国社科领域科研成果整体公信力的损失。这种情况在发表的期刊论文中并不少见,大量本硕博学位论文所采用数据的可靠性更是无法得到保证,其所带来的损失更是不可估量。
基于上述分析,我们认为,学者使用一份高质量的研究数据集方能形成稳定可靠的研究结果。而这样的数据集至少要在数据采集、数据清洗、数据整合等多个方面完成科学、完整和准确的系列操作,并且保证处理过程的可追溯、可复现。本文接下来将以基于2022年12月国家知识产权局公布的《绿色低碳技术专利分类体系》(以下简称“《分类体系》”)[2]加工出的中国绿色低碳专利微观数据集为例,从数据来源、数据清洗、数据整合三个方面介绍一份干净、精准的绿色低碳技术专利数据集是如何产生的,以期为促进科研领域研究数据处理的规范化提供参考。
[2] 参见https://www.gov.cn/zhengce/zhengceku/2022-12/28/content_5733911.htm。
二、专利数据简介
以上文提到的《分类体系》为依据,本文试图从中国全量专利微观数据库中识别并提取出绿色低碳技术专利,前者来源于国家知识产权局。专利分为发明、实用新型和外观设计。依据《专利法》的规定,如图1所示,获得专利一般分为申请和授权两个步骤,实用新型和外观设计在初步审查后符合条件的,自申请日起满十八个月可公开,且公开即授权。而发明专利自申请日起首先通过十八个月的初步审查后可公开,再经过三年实质审查,方可正式确认是否最终授予其专利权。

图1 中国专利申请与授权流程
本文采用的中国全量专利数据库更新截止到2022年12月26日,时间区间为1985-2022年,仅包含申请且已公开的那部分专利[3]。原始的数据量为4126.3万条,其中发明专利(未授权)为990.07万,发明授权为558.38万,实用新型为1804.76万,外观设计为773.09万。
[3] 尽管我们采用了更新到2022年底的数据,但由于十八个月初步审查期的存在,2021、2022年度的数据仍可能并不完整。例如,2021年底申请的专利,原则上最晚公开的时间是2023年6月。
由于不包括申请了但未公开的那部分专利,理论上国家知识产权局统计的专利申请数应大于我们根据公开渠道采集到的专利记录所统计的申请数[4],但专利授权数量应该保持一致。从专利授权上看:(1)截止至2022年底,国家知识产权局实际上公布的数据量为2731.76w,本文的基础授权数据量为2724.26w,相差仅为0.27%左右;(2)数据量相差最大的年份为2011年,比例约为4.3%左右;(3)最近年份的数据差异更小。2017-2021年国家知识产权局公布的统计数据和本文所用数据量相差个位数,精准度高达99.99%。可见,以国家知识产权局公布的权威统计数据为基准,本文所用专利原始数据存在的偏差至少在科研领域属于可接受的数据误差范围。
[4] 除了《专利法》中规定的三年实质性审查对发明专利申请数量的影响外,造成国家知识产权局和本文基础数据差异的可能原因有:①保密专利的再公开。②1993年前三个月异议期的存在。但以上的原因对于总体数据量的影响较小,且由于数据的不可得性,本文不予以讨论。
三、绿色低碳专利清洗依据与基本思路
数据清洗是得到一份高质量研究数据的重要步骤,科学的数据清洗过程应该具有可溯源、逻辑清晰、说明详实等特征。然而,与数据采集往往都基于官方网站,从而具有较强的客观性不同,数据清洗往往是“千人千面”,具有明显的主观性。以绿色低碳技术专利的清洗为例,尽管“处理的标准”参考的是同一份政策文件,但是由于对文件的理解存在差异,以及处理技术的难易程度不同,经过清洗得到的数据可能也是“天差地别”,基于此开展的一系列研究结论的可靠性和可比性也存疑。
接下来,我们将从参考文件、清洗目标、数据预处理、数据处理四个方面介绍中国绿色低碳技术专利微观数据集获取依据和清洗思路。
(一)参考文件
正如引言所提及,2022年12月,国家知识产权局公布了《绿色低碳技术专利分类体系》,至此,我国对于绿色低碳技术专利有了比较明确的界定范围和评价标准(严索等,2023)。本次清洗以该《分类体系》为依据,旨在从中国全量专利微观数据集中筛选出符合《分类体系》定义的绿色低碳技术专利。
该《分类体系》将绿色低碳技术分为四级技术分支,部分信息如附录表A1所示。一级技术分支包括化石能源降碳技术、节能与能量回收利用、清洁能源、储能技术、温室气体捕集利用封存等5个技术分支,二级技术分支包括石油及天然气清洁化、节油技术、节气技术等19个技术分支,三级技术分支包括煤炭低碳开采、工业用煤等56个技术分支,四级分支包括保水开采技术、地下气化技术等62个四级分支。
除了公布的绿色技术分支外,该份标准文件还提供了每一类绿色低碳技术专利相对应的IPC分类、参考关键词、参考检索式和补充检索用CPC。本文认为,应该基于参考检索式设定正则表达式,通过设定函数和循环,更精准、详尽地提取出真正符合标准的绿色低碳技术专利。而当前公开的一些专利清洗工作,仅简单采用IPC分类号来识别绿色低碳技术专利,这会纳入许多不属于绿色低碳技术的专利,下文我们会对此给出示例。
(二)清洗目标
明确清洗目标也是数据清洗中必不可少的一环。通过爬虫等途径采集得来的原始数据可能非常庞大和杂乱,明确清洗的目标,可以帮助我们集中精力从中提取出需要的信息和字段。
以绿色低碳技术专利为例,国家知识产权局公布的专利数据如图2所示,数据杂乱且没有统一的标准。通过对《分类体系》的解读,我们计划从中筛选出清洗所需要的字段,即专利申请号(APPNO)、国际专利分类号IPC(CLASSNO)、专利标题(PATNAME)、专利摘要(SUMMARY)、专利权利要求书(PRINCIPAL_CLAIM)等。从中,可以提取出用于识别绿色低碳技术专利的字段,包括专利申请号(APPNO)、一级技术分支(FIRST_LEVEL)、二级技术分支(SECOND_LEVEL)、三级技术分支(THIRD_LEVEL)、四级技术分支(FOURTH_LEVEL)。最后,根据以上字段,再进一步处理得到数据如图3所示。

图2 原始专利数据(样例)

图3 绿色低碳技术专利数据(样例)
(三)数据预处理
数据预处理工作是为了清理出如上可识别绿色低碳技术专利数据的字段,具体可分为如下三个步骤:
1.规范化表达首先,我们需要清洗专利数据,对专利数据表中专利摘要(SUMMARY)和专利权利要求书(PRINCIPAL_CLAIM)中可能包含一些化学表达式等非常规符号进行规范化表达,并且根据专利申请号对专利数据进行去重。
2.处理IPC分类号为正确使用参考检索式中的IPC分类号,我们参考国际专利分类表[5]的层级关系,获取了每个IPC分类号对应层级及其所有子层级的IPC,然后,将这些IPC分类号作为参考检索式中IPC的正则匹配条件。
[5] 国际专利分类表(IPC分类)是一个通用的专利文献分类和检索工具,其根据1971年签订的《国际专利分类斯特拉斯堡协定》编制的,包含A部-H部。用国际专利分类法分类专利文献(说明书、权力要求等)而得到的分类号,称为国际专利分类号,通常简称为IPC号,为专利申请人和专利审查人员提供了一种标准化的方式来描述和探索发明。具体参见https://www.cnipa.gov.cn/col/col2152/index.html。
在这里,我们要着重讨论一个上文已提及的问题,采用正则匹配条件如此复杂,为什么不直接用IPC分类号或主分类号对专利数据进行简单筛选呢?原因在于,一些属于文件中提到分类号或主分类号的专利,如果无法通过参考检索式的正则判断,就不是绿色低碳技术专利。我们将给出相关实例来说明,不能仅根据分类号或主分类号简单判断是否属于绿色低碳技术专利,否则会夸大绿色低碳技术专利的范围和整体数据量。[6]。
[6] 我们在互联网上获得了一份绿色低碳技术专利数据,并研究了其处理过程。该数据的开发者明确指出仅根据专利分类号或主分类号进行筛选。从结果来看,该数据的年份覆盖也是1985-2022年,数据量为500w左右。这与我们通过参考检索式和正则匹配条件的绿色低碳技术专利的数据量差异巨大,因为大量非绿色低碳技术专利被错误界定为绿色低碳技术专利。
下面我们给出几个根据IPC分类号判断属于绿色低碳技术专利,但通不过参考检索式正则匹配条件的专利,读者亦可自行判断其是否属于绿色低碳技术专利?如附录中图A1a所示,实用新型专利“一种便于清理的脱硫塔”的专利申请号为CN202122958195.9,其IPC分类号为B01D53/50,对应于绿色技术分支中的1.1.3.4烟气处理技术,若只简单根据IPC分类号,应确认为绿色低碳技术专利,但细看专利摘要可知其并非绿色低碳技术专利。
同理,附录中图A1b发明专利“钻井参数采集及处理方法”的专利申请号为CN02128739.2,对应的IPC分类号为H02J1/00,对应于技术分支中的1.1.1.6智能控制技术,但由于其无法通过正则判断,故不属于绿色低碳技术专利。图A1c发明授权“聚合物多层分注井下流量控制装置”的专利申请号为CN00102551.1,对应的IPC分类号为E21B43/22,对应于技术分支中的1.2.1.2驱油技术,同样由于无法通过正则判断,不能将其纳入绿色低碳技术专利范畴。
总结一下,上述三个专利若简单以IPC分类号作为筛选条件,均可被视为绿色低碳技术专利,但根据《分类体系》中的参考检索式,其并不属于绿色低碳技术专利。而我们通过阅读这三个专利的摘要可知,它们都与绿色低碳技术相差甚远。
作为比较,如果我们加上参考检索式,在同样的IPC分类号下,筛选出来的就是绿色低碳专利。例如,附录中图A2a中的发明授权专利“一种二氧化硫烟气的治理方法”的专利申请号为CN200710035059.4,其IPC分类号为B01D53/50,属于绿色技术分支中的1.1.3.4烟气处理技术;图A2b中的实用新型专利“一种新型能源切换装置”的专利申请号为CN202120652189.8,其IPC分类号为H02J1/00,属于绿色技术分支中的1.1.1.6智能控制技术;图A2c中的实用新型专利“一种环保型开采天然气水合物的装置”的专利申请号为CN201620077337.7,其IPC分类号为E21B43/22,属于绿色技术分支中的1.2.1.2驱油技术。
3.处理参考检索式最后,我们根据参考检索式的检索条件,对绿色低碳专利分类体系中的128组参考检索式(含技术分支名称)进行分类,可大致分为五类[7]。至此,我们完成了数据预处理的工作,也完成了绿色低碳技术专利数据处理70%的工作。
[7] 在根据《绿色低碳技术专利分类体系》获取所有技术分支编号及对应技术分支名称后,我们可以定义获取技术分支名称的函数,当专利数据满足某个参考检索式条件时,函数会提取出这条检索式对应的技术分支编号,并获取该编号对应的所有级别的技术分支名称作为标签。
(四)数据清洗思路
基于以上分析,我们认为需要对原始专利数据的每一条都进行所有参考检索式的正则判断。具体步骤为:①完成128组参考检索式的正则表达式,将其按照数据预处理的第三个步骤分为五类。②定义五个函数,分别对应五类参考检索式条件。③程序将循环遍历所有专利数据,并依次应用五个函数[8]。详细数据处理思路见图4。
[8] 在每个函数中,程序将逐个遍历其中的参考检索式,若专利数据符合某个检索式的正则表达式条件,程序将返回标签;否则,继续下一次循环。
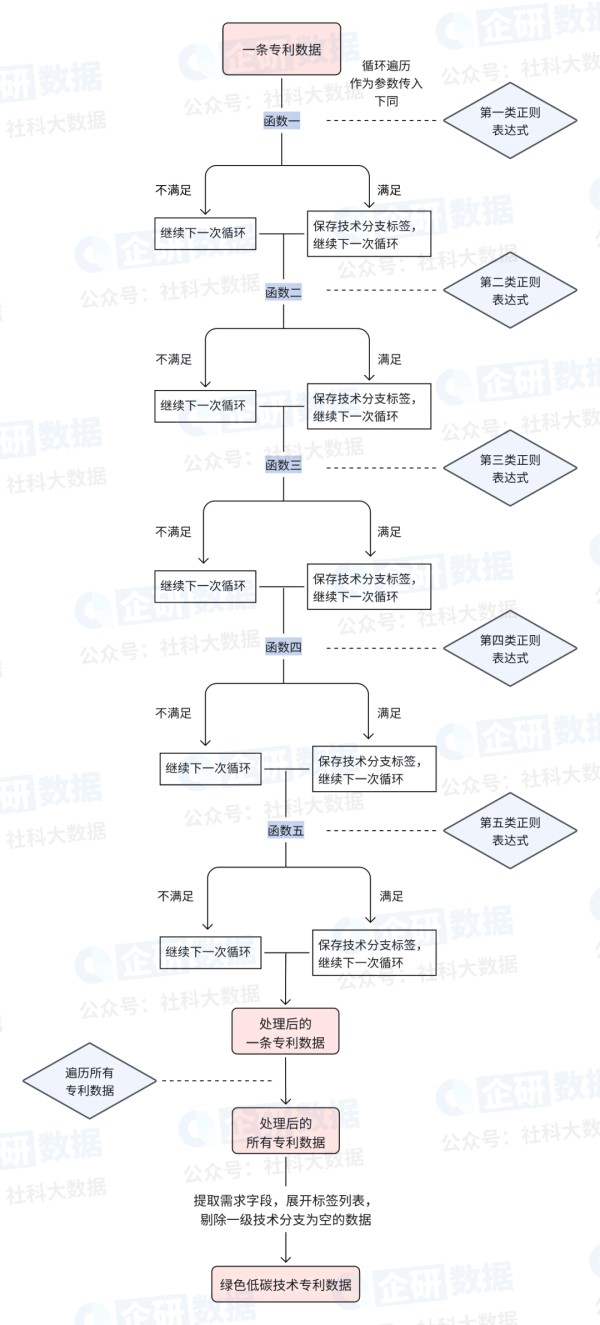
图4 专利数据处理技术路线图
在经过以上的数据清洗过程后,我们完成了对绿色低碳技术专利的清洗和处理工作,数据处理的结果是,截止到2022年底,中国绿色低碳技术专利的申请数量约为134万件,约占专利申请总数的3.3%。
如图5所示,中国绿色低碳技术专利申请量整体呈上升趋势,2020年达到最高值,约17.92万件。当然,前文已经提及,由于本文所用原始专利数据更新至2022年底,而专利从申请到公开基本需要18个月时间,因此2021和2022年专利实际申请量是被低估的。发明类专利总数量72.58万件,占全部绿色低碳技术专利的53.99%,可见专利“含金量”较高。

图5 1985-2022年绿色低碳技术专利申请情况(单位:件)
按照技术分支来看(5个一级技术分支[9]),如图6所示,节能与能量回收利用的专利申请量最多,清洁能源和储能技术相对而言也较多,这三者约占绿色低碳技术专利的88.81%左右,而温室气体捕集利用封存的专利申请量最少,反映出绿色低碳不同技术方向的发展是不均衡的。
[9] 存在一条专利对应多个技术分支的情况。

图6 绿色低碳技术专利一级技术分支分布情况(单位:万件)
四、数据整合
在当前科研领域,学者可以通过各类数据的整合和横向匹配,关联起两个不同的研究领域,将一份简单的微观数据延伸至多个研究层面。
本文以A股上市公司为例,说明如何将绿色技术专利与企业层面数据结合。首先,我们从企研“全量企业工商注册数据库”中筛选出A股上市公司的数据;其次,根据企业唯一识别码(SAMPLE_ID)将A股上市公司的基本信息[10]和绿色低碳技术专利信息进行横向匹配;最后,统计匹配结果,检查是否有重复或遗漏。
[10] 中国专利数据库与全量企业工商注册数据库的匹配报告见施丹燕和杨奇明(2022),本文从中筛选出了A股上市公司部分的数据,作为A股上市公司的专利数据基本信息库。
匹配结果为:中国A股上市公司所申请绿色低碳技术专利占全部绿色低碳技术专利数比重并不高,数据量约7.9万条,其中发明申请(未授权)的数量为2.61万条,发明授权专利数为2.24万条,实用新型的数量为3.05万条;年份跨度为1995-2022年,涉及到的A股上市公司共2160家。如图7所示,绿色低碳专利技术申请数和授权数整体呈现上升趋势[11]。
[11] 1995年专利申请号为CN95242977.2的绿色低碳技术专利——节能燃烧器(实用新型),在1996年1月31日才授权,所以1995年A股上市公司绿色低碳技术专利授权数量为0,该专利的具体信息如附录图A3所示。

注:上文已提及,2021年和2022年绿色低碳技术专利申请数量是被低估的。
图7 1995-2022年上市公司绿色低碳技术专利申请、授权数量(单位:件)
除A股上市公司外,绿色低碳技术专利还可以与其他企业数据进行匹配和整合,例如新三板企业基本信息、工业企业数据库等,依研究主题和目的而定,只要遵循数据整合的原则,即合理的匹配变量、正确的空值处理方式、对处理结果的描述性统计符合事实等,就能得到一份符合研究主题的、完整、高质量的面板数据。
五、结论和进一步讨论
尽管目前科研数据服务市场上有众多进行数据清洗和整合的机构,但研究数据的质量仍然无法得到保证,主要可能有以下几个原因:①底层数据缺失或错误。在数据收集或爬取的过程中,底层数据可能漏采或误采,而在事后又没有与官方数据进行比对分析,导致“一步错步步错”。②数据处理技术不完善。在数据筛选或处理时,部分机构可能出于时间、人力成本的考虑,或者对处理难度过大的清洗只进行了简单的技术处理,严重降低了最终数据的质量。③低成本数据传播和共享。由于互联网的普及,信息传播变得非常方便,几乎零成本,导致市场上低质量的数据“大行其道”,严重损害了学术研究的严肃性、科学性和权威性。
本文以较为可靠的专利原始数据为基础,依据国家知识产权局等权威部门公布的文件,经过一系列数据处理,获得了包含申请与授权信息的绿色低碳技术专利研究数据集,为广大社科领域学者研究绿色创新的变化趋势和发展规律提供了数据基础。
一份高质量的数据是学术研究的基础,是决定研究结论是否有意义的重要环节。以绿色低碳技术专利数据清洗与质量核验为例,本文也总结出了获得一份可靠微观科研数据的两大关键:①可靠的数据来源和权威的参考文件。②科学、可追溯的数据清洗流程。
尽管数据清洗看似是一项难度并不高的工作,但在实操中,其包含的内容和方法是十分庞大且复杂的。因此,本文也存在如下不足:第一,由于数据更新的原因,本文所用中国全量专利数据只更新至2022年底,后期随着数据的更新,2021和2022年专利申请及相关统计数据可能会发生变动;第二,局限于篇幅和示例,本文可能还有其他未尽之处,也待后续研究进行补充和改进。
参考文献[1] 严索,高婷,金海. 基于专利分类体系我国绿色低碳技术专利布局状况研究[J]. 中国发明与专利,2023,20(06):30-37.
[2] 施丹燕, 杨奇明. 中国专利数据库与全量企业工商注册数据库匹配报告, 2022,企研数据处理工作论文系列,No.WP0007.
附录表A1 《分类体系》部分参考检索式信息

来源:《绿色低碳技术专利分类体系》
图A1为IPC分类号判断属于绿色低碳技术专利,但通不过参考检索式正则匹配条件的专利示例。(图片来源于“专利检索及分析”网站:https://pss-system.cponline.cnipa.gov.cn)

图A1a 一种便于清理的脱硫塔(实用新型)

图A1b 钻井参数采集及处理方法(发明专利)

图A1c 聚合物多层分注井下流量控制装置(发明授权)
图A2为同A1中的IPC分类号,且可以通过参考检索式正则匹配条件的绿色低碳技术专利示例。(图片来源于“专利检索及分析”网站:https://pss-system.cponline.cnipa.gov.cn)

图A2a 一种二氧化硫烟气的治理方法(发明授权)

图A2b 一种新型能源切换装置(实用新型)

图A2c 一种环保型开采天然气水合物的装置(实用新型)
图A3为第一份申请的绿色低碳技术专利信息。(图片来源于“专利检索及分析”网站:https://pss-system.cponline.cnipa.gov.cn)

图A3 节能燃烧器(实用新型)
相关内容推荐数据质量检测系列推文
数据质量检测 | 对一份中国工商企业注册数据库的质量考察
数据质量检测|论数据质量差异的显著性
工作论文系列推文
企业数据库匹配系列(一)| 工企库与工商库匹配报告(上)
企业数据库匹配系列(一)| 工企库与工商库匹配报告(下)
企业数据库匹配系列(二)| 用文本相似度算法为中国工业企业数据库筛选重复样本
企业数据库匹配系列(三)|专利库与工企库匹配报告(上)
企业数据库匹配系列(三)|专利库与工企库匹配报告(下)
企业数据库匹配系列(四)|海关库与工商库匹配报告(上)
企业数据库匹配系列(四)|海关库与工商库匹配报告(下)
企业数据库匹配系列(五)|海关库与工企库匹配报告
企研数据处理工作论文系列 | 专利库与工商库匹配报告(上)
企研数据处理工作论文系列 | 专利库与工商库匹配报告(下)
学术RA丨如何用机构代码唯一识别企业(科普篇)
学术RA | 如何用机构代码唯一识别企业(实践篇)
网址:企研数据工作论文系列 https://www.yuejiaxmz.com/news/view/449242
相关内容
论文开题报告:对工作压力的研究工作报告数据分析.docx
论文范文—企业员工的工作压力管理
构建基于大数据的决策支持系统:研究与实践
数据弄潮,百分点“数据管家”问世
大数据安全的一系列挑战
基于大数据的学习资源推荐系统的设计与实现(论文+源码)
数据驱动服务运营的理论与实务
人民数据研究院发布《二手交易与低碳生活研究报告》胖虎科技集团入选行业代表企业
企业社会工作介入员工压力管理问题研究
随便看看
最新动态分享
- “智慧社区+全屋智能”一体化联动
- 澄澜筑景智慧家居:科技与舒适的完美结合
- 共建共享高品质生活智慧家居
- 泛海物业
- 科學生活:居家智慧時代就要來了嗎?
- 智能家居会给生活带来哪一些智慧
- 居家必看9招生活诀窍
- 中国智慧社区居家养老(智慧科技助力老年人健康生活)
- 如何让智慧生活走进现实中,走到家中?
- 智慧生活作文(实用9篇)
热点动态分享
- 2114
- 2022
- 1909
- 1802
- 1457
- 1421
- 1411
- 1241
- 1115
- 1107

