强化学习(3) 蒙特卡罗方法
使用Anki记忆卡片法,强化学习效果 #生活技巧# #工作学习技巧# #知识整理工具#
蒙特卡罗方法
在强化学习(2)我们讲了已知模型时,利用动态规划的方法求解马尔科夫决策问题。然而很多时候,我们无法知道状态转移概率矩阵 P P P,这时动态规划法根本无法使用。这时候我们如何求解强化学习问题呢?
今天我们讲无模型的强化学习算法。无模型的强化学习算法主要包括蒙特卡罗方法和时间差分方法。本文要讨论蒙特卡罗(Monte-Calo, MC)的方法。
在动态规划的方法中,值函数的计算方法为:
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) ( R s a + γ ∑ s ′ ∈ S P s s ′ a v π ( s ′ ) ) v_{\pi}(s)=\sum_{a \in A} \pi(a | s)\left(R_{s}^{a}+\gamma \sum_{s^{\prime} \in S} P_{s s^{\prime}}^{a} v_{\pi}\left(s^{\prime}\right)\right) vπ(s)=∑a∈Aπ(a∣s)(Rsa+γ∑s′∈SPss′avπ(s′))
动态规划方法计算状态处的值函数时利用了模型 P s s ′ a P_{ss'}^{a} Pss′a 而在无模型强化学习中,模型 P s s ′ a P_{ss'}^{a} Pss′a 是未知的。无模型的强化学习算法要想利用策略评估和策略改善的框架,必须采用其它的方法对当前策略进行评估(计算值函数)。
我们回到值函数最原始的定义公式:
v π ( s ) = E π [ G t ∣ S t = s ] = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s ] v_{\pi}(s)=E_{\pi}\left[G_{t} | S_{t}=s\right]=E_{\pi}\left[\sum_{k=0}^{\infty} \gamma^{k} R_{t+k+1} | S_{t}=s\right] vπ(s)=Eπ[Gt∣St=s]=Eπ[∑k=0∞γkRt+k+1∣St=s]
q π ( s ) = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s , A t = a ] q_{\pi}(s)=E_{\pi}\left[\sum_{k=0}^{\infty} \gamma^{k} R_{t+k+1} | S_{t}=s, A_{t}=a\right] qπ(s)=Eπ[∑k=0∞γkRt+k+1∣St=s,At=a]
状态值函数和行为值函数的计算实际上是计算返回值的期望。动态规划的方法是利用模型对该期望进行计算。在没有模型时,我们可以采用蒙特卡罗的方法计算该期望,即利用随机样本来估计期望。在计算值函数时,蒙特卡罗方法是利用经验平均代替随机变量的期望。
策略评估
当要评估智能体的当前策略时,我们可以利用策略产生很多次试验,每次试验都是从任意的初始状态开始直到终止状态,比如一次试验(an episode)为: S 1 , A 1 , R 2 , ⋯   , S T S_1,A_1,R_2,\cdots ,S_T S1,A1,R2,⋯,ST计算一次试验中状态s处的折扣回报返回值为: G t ( s ) = R t + 1 + γ R t + 2 + ⋯ + γ T − 1 R T G_t\left(s\right)=R_{t+1}+\gamma R_{t+2}+\cdots +\gamma^{T-1}R_T Gt(s)=Rt+1+γRt+2+⋯+γT−1RT
那么对于蒙特卡罗法来说,如果要求某一个状态的状态价值,只需要求出所有的完整序列中该状态出现时候的折扣回报值再取平均即可近似求解。
不过,利用蒙特卡罗方法求状态s处的值函数时,又可以分为第一次访问蒙特卡罗方法和每次访问蒙特卡罗方法。
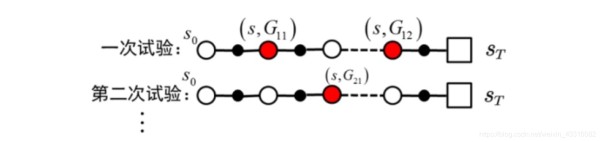
图1.1
第一次访问蒙特卡罗方法是指,在计算状态s处值函数时,只利用每次试验中第一次访问到状态s时的返回值。如图1.1中第一次试验所示,计算状态s处的均值时只利用 G 11 G_{11} G11 。因此第一次访问蒙特卡罗方法的计算公式为:
v ( s ) = G 11 ( s ) + G 21 ( s ) + ⋯ N ( s ) v(s)=\frac{G_{11}(s)+G_{21}(s)+\cdots}{N(s)} v(s)=N(s)G11(s)+G21(s)+⋯
每次访问蒙特卡罗方法是指,在计算状态s处的值函数时,利用所有访问到状态s时的回报返回值,即:
v ( s ) = G 11 ( s ) + G 12 ( s ) + ⋯ + G 21 ( s ) + ⋯ N ( s ) v(s)=\frac{G_{11}(s)+G_{12}(s)+\cdots+G_{21}(s)+\cdots}{N(s)} v(s)=N(s)G11(s)+G12(s)+⋯+G21(s)+⋯
第二种方法比第一种的计算量要大一些,但是在完整的经历样本序列少的场景下会比第一种方法适用。
在上面的求解公式里,我们有一个求平均的过程,意味着要保存所有该状态的回报值之和最后取平均。这样浪费了太多的存储空间。一个较好的方法是在迭代过程计算回报均值,即每次保存上一轮迭代得到的回报均值与次数,当计算当前轮的回报时,即可计算当前轮回报均值和次数。递增计算均值的方法为:
v k ( s ) = 1 k ∑ j = 1 k G j ( s ) = 1 k ( G k ( s ) + ∑ j = 1 k − 1 G j ( s ) ) = 1 k ( G k ( s ) + ( k − 1 ) v k − 1 ( s ) ) = v k − 1 ( s ) + 1 k ( G k ( s ) − v k − 1 ( s ) ) vk(s)amp;=1kk∑j=1Gj(s)amp;=1k(Gk(s)+k−1∑j=1Gj(s))amp;=1k(Gk(s)+(k−1)vk−1(s))=amp;vk−1(s)+1k(Gk(s)−vk−1(s))
vk(s)==k1j=1∑kGj(s)=k1(Gk(s)+j=1∑k−1Gj(s))=k1(Gk(s)+(k−1)vk−1(s))vk−1(s)+k1(Gk(s)−vk−1(s))
这样上面的状态价值公式就可以改写成:
N ( S t ) = N ( S t ) + 1 N\left(S_{t}\right)=N\left(S_{t}\right)+1 N(St)=N(St)+1
V ( S t ) = V ( S t ) + 1 N ( S t ) ( G t − V ( S t ) ) V\left(S_{t}\right)=V\left(S_{t}\right)+\frac{1}{N\left(S_{t}\right)}\left(G_{t}-V\left(S_{t}\right)\right) V(St)=V(St)+N(St)1(Gt−V(St))
其中 G t = R t + 1 + γ R t + 2 + ⋯ + γ T − 1 R T G_{t}=R_{t+1}+\gamma R_{t+2}+\cdots+\gamma^{T-1} R_{T} Gt=Rt+1+γRt+2+⋯+γT−1RT
这样我们无论数据量是多还是少,算法需要的内存基本是固定的 。
有时候,尤其是海量数据做分布式迭代的时候,我们可能无法准确计算当前的次数 N ( S t ) N\left(S_{t}\right) N(St),这时我们可以用一个系数 α α α来代替,即:
V ( S t ) = V ( S t ) + α ( G t − V ( S t ) ) V\left(S_{t}\right)=V\left(S_{t}\right)+\alpha\left(G_{t}-V\left(S_{t}\right)\right) V(St)=V(St)+α(Gt−V(St))
对于动作值函数 Q ( S t , A t ) Q\left(S_{t}, A_{t}\right) Q(St,At),也是类似的,比如对上面最后一个式子,动作值函数版本为:
Q ( S t , A t ) = Q ( S t , A t ) + α ( G t − Q ( S t , A t ) ) Q\left(S_{t}, A_{t}\right)=Q\left(S_{t}, A_{t}\right)+\alpha\left(G_{t}-Q\left(S_{t}, A_{t}\right)\right) Q(St,At)=Q(St,At)+α(Gt−Q(St,At))
策略改进
回忆下动态规划价值迭代的的思路, 每轮迭代先做策略评估,计算出价值 v k ( s ) v_{k}(s) vk(s),然后基于一定的方法(比如贪婪法)更新当前策略 π π π。最后得到最优价值函数 v ∗ v^{*} v∗和最优策略 π ∗ \pi^{*} π∗。
和动态规划比,蒙特卡罗法不同之处体现在三点:一是策略评估的方法不同;二是蒙特卡罗法一般是优化最优动作价值函数 q ∗ q^{*} q∗,而不是状态价值函数 v ∗ v^{*} v∗;三是动态规划一般基于贪婪法更新策略,而蒙特卡罗法一般采用 ϵ ϵ ϵ−贪婪法更新。
π ( a ∣ s ) ← { 1 − ε + ε ∣ A ( s ) ∣ if a = arg max a Q ( s , a ) ε ∣ A ( s ) ∣ if a ≠ arg max a Q ( s , a ) \pi(a | s) \leftarrow \left\{1−ε+ε|A(s)| if a=argmaxaQ(s,a)ε|A(s)| if a≠argmaxaQ(s,a)
\right. π(a∣s)←{1−ε+∣A(s)∣ε if a=argmaxaQ(s,a)∣A(s)∣ε if a̸=argmaxaQ(s,a)
在实际问题中,为了使算法收敛,一般 ϵ ϵ ϵ会随着算法的迭代过程逐渐减小,并趋于0。这样在迭代前期,我们鼓励探索,而在后期,由于我们有了足够的探索量,开始趋于保守,以贪婪为主,使算法可以稳定收敛。这样我们可以得到一张和动态规划类似的图:
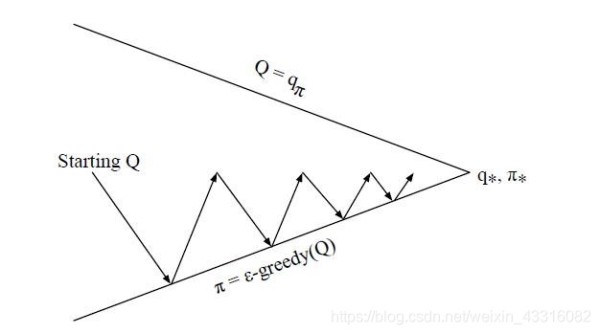
根据探索策略(行动策略)和评估的策略是否是同一个策略,蒙特卡罗方法又分为on-policy和off-policy。
若行动策略和评估及改善的策略是同一个策略,我们称之为on-policy,可翻译为同策略。
若行动策略和评估及改善的策略是不同的策略,我们称之为off-policy,可翻译为异策略。
同策略是指产生数据的策略与评估和要改善的策略是同一个策略。比如,要产生数据的策略和评估及要改进的策略都是 ε − s o f t \varepsilon -soft ε−soft策略。
异策略是指产生数据的策略与评估和改善的策略不是同一个策略。我们用 π \pi π表示用来评估和改进的策略,用 μ \mu μ表示产生样本数据的策略。
蒙特卡罗法算法流程
这里我们给出同策略蒙特卡罗强化学习方法。
输入:状态集 S S S, 动作集 A A A, 即时奖励 R R R,衰减因子 γ γ γ, 探索率 ϵ ϵ ϵ
输出:最优的动作价值函数 q ∗ q^{*} q∗和最优策略 π ∗ \pi^{*} π∗
G t = R t + 1 + γ R t + 2 + ⋯ + γ T − 1 R T G_{t}=R_{t+1}+\gamma R_{t+2}+\cdots+\gamma^{T-1} R_{T} Gt=Rt+1+γRt+2+⋯+γT−1RT
N ( S t , A t ) = N ( S t , A t ) + 1 N\left(S_{t}, A_{t}\right)=N\left(S_{t}, A_{t}\right)+1 N(St,At)=N(St,At)+1
Q ( S t , A t ) = Q ( S t , A t ) + 1 N ( S t , A t ) ( G t − Q ( S t , A t ) ) Q\left(S_{t}, A_{t}\right)=Q\left(S_{t}, A_{t}\right)+\frac{1}{N\left(S_{t}, A_{t}\right)}\left(G_{t}-Q\left(S_{t}, A_{t}\right)\right) Q(St,At)=Q(St,At)+N(St,At)1(Gt−Q(St,At))基于新计算出的动作价值,更新当前的 ϵ − ϵ− ϵ−贪婪策略:
π ( a ∣ s ) ← { 1 − ε + ε ∣ A ( s ) ∣ if a = arg max a Q ( s , a ) ε ∣ A ( s ) ∣ if a ≠ arg max a Q ( s , a ) \pi(a | s) \leftarrow \left\{1−ε+ε|A(s)| if a=argmaxaQ(s,a)ε|A(s)| if a≠argmaxaQ(s,a)\right. π(a∣s)←{1−ε+∣A(s)∣ε if a=argmaxaQ(s,a)∣A(s)∣ε if a̸=argmaxaQ(s,a)如果所有的 Q ( s , a ) Q(s,a) Q(s,a)收敛,则对应的所有 Q ( s , a ) Q(s,a) Q(s,a)即为最优的动作价值函数 q ∗ q^{*} q∗。对应的策略 π ( a ∣ s ) π(a|s) π(a∣s)即为最优策略 π ∗ \pi^{*} π∗。否则转到第二步。
蒙特卡罗法求解强化学习问题小结
蒙特卡罗法是我们第二个讲到的求解强化问题的方法,也是第一个不基于模型的强化问题求解方法。它可以避免动态规划求解过于复杂,同时还可以不事先知道环境转化模型,因此可以用于海量数据和复杂模型。但是它也有自己的缺点,这就是它每次采样都需要一个完整的状态序列。如果我们没有完整的状态序列,或者很难拿到较多的完整的状态序列,这时候蒙特卡罗法就不太好用了, 也就是说,我们还需要寻找其他的更灵活的不基于模型的强化问题求解方法。
下一篇我们讨论基于时间差分的强化学习方法。
参考文献:
[1]https://www.cnblogs.com/pinard/p/9492980.html
[2]https://zhuanlan.zhihu.com/p/25743759
网址:强化学习(3) 蒙特卡罗方法 https://www.yuejiaxmz.com/news/view/465691
相关内容
数学建模之蒙特卡罗方法强化学习1——基本概念、MDP、价值迭代、策略迭代、蒙特卡洛
强化学习中的策略迭代算法优化研究
3个学习方法分享给同学们08
高效的学习方法一费曼学习法
这3个高效的学习方法送给同学们07
3个高效的学习方法分享给大家08
3个高效的学习方法送给大家08
独特的蒙古族草原美食
强化理论学习 坚持创新方法
随便看看
最新动态分享
- 科学春练避误区 循序渐进强体魄
- 【山东科协每日科普】掌握这些原则,科学健身减少运动伤害
- 科普 | 运动、健身与健康之间的科学关系
- 科学健身十大原则
- 健康中国 科学先行——专家谈科学健身
- 爱健身更要科学健身
- 2025春季健身热潮即将来袭,你准备好了吗?如何科学运动以防受伤?
- 健身+健康丨科学运动、避免损伤,乐享健康生活
- 生命在于运动,运动需要科学。今天,全国各地健身热潮涌动,体育运动逐渐成为一种日常生
- 科学参与健身 安全保障先行
热点动态分享
- 2819
- 2689
- 2597
- 2349
- 2205
- 1835
- 1651
- 1499
- 1392
- 1312

