国内外推荐算法研究述评
学术研究助手:百度学术书籍推荐 #生活乐趣# #阅读乐趣# #书籍推荐平台#
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录 一、前言二、推荐系统的应用领域(一)推荐系统的定义(二)推荐系统的研究现状1.优化提高推荐算法的效率2.大数据处理分析3.推荐算法领域延伸4.混合推荐算法 三、国内外推荐算法相关研究(一)基于内容的推荐算法(二)协同过滤推荐算法1.基于用户的协同过滤推荐算法2.基于物品的协同过滤推荐算法3.基于模型的协同过滤推荐算法(1)关联规则。(2)聚类。(3)贝叶斯分类器。(4)矩阵技术。 4.协同过滤推荐算法的优缺点总结 (三)基于深度学习的推荐算法1.基于深度学习的社交网络推荐系统2.基于深度学习的上下文感知推荐系统 (四)混合推荐算法 四、个性化推荐中的隐私问题(一)数据隐私的重要性及挑战1.用户私有敏感属性信息2.用户-物品交互历史信息3.所有用户提交给推荐系统的信息 (二) 隐私保护技术1.匿名化2.差分隐私3.联邦学习4.对抗学习 五、知识图谱在个性化推荐中的应用(一)知识图谱(二)知识图谱在推荐系统中的应用1.基于嵌入的推荐方法2.基于路径的推荐方法3.基于传播的推荐方法(1)用户或项目表示的细化(2)协同用户项目表示 六、结语一、前言
在当今信息技术迅速发展的社会,推荐系统已经成为人们使用互联网应用时经常接触的核心技术之一。作为一种旨在为用户推荐满足其需求的商品、新闻资讯、音视频等信息的技术系统,推荐系统已经广泛应用于电商、社交网络、门户网站等各种领域。
对用户提供个性化的推荐服务是推荐系统最重要的目标之一。随着用户对信息保护意识的不断提高,更多用户趋向于获取符合自己需求和兴趣的个性化推荐结果,而非传统模式的广告推送。可是,在这些系统中,推荐算法和用户数据处于最核心的位置,如若这些算法和数据泄露,将严重影响到用户隐私安全。因此,如何在保障用户隐私的情况下构建一个满足个性化需求的推荐系统,成为当前研究的重点和难点。
随着知识图谱和隐私保护技术等新兴技术的出现,提供了新的思路和措施来解决推荐系统中存在的问题。知识图谱通过结构化三元组的形式,有效地提取和表示用户和推荐项目的关系,从而提高推荐算法的准确性。但是,将知识图谱融合到推荐算法中会增加用户信息量,使攻击者获得更多背景知识,从而对用户隐私带来更大的风险1 。
而差分隐私技术(Differential Privacy,DP)可以有效地保护用户隐私,防止攻击者通过背景知识窃取用户敏感信息。它通过在查询结果中加入随机噪声来防止推测个体信息,并保证查询结果不会因为单个元素的变化而显著变化。这种保证数据集中个体信息的不可区分性能够实现数据隐私保护,因此是一种很有效的数据安全保护技术,特别是在数据挖掘任务中效果更佳。2
本文主要介绍了现有的各类常见的推荐算法,并分析各推荐算法的优劣之处,归纳了目前该领域内所面临着的主要问题,结合隐私保护和知识图谱技术,探讨的个性化推荐方案.在第2节描述了推荐系统目前的研究背景和研究意义。第3节详细介绍目前主要的推荐算法,第4节介绍隐私保护的研究进展,包括数据加密、数据匿名化、数据脱敏等隐私保护技术,并阐述这些技术在推荐系统中的应用场景和实现方式;第5节介绍知识图谱的基本概念和应用价值,并着重介绍知识图谱在推荐系统中的应用;第6节对全文进行总结。
二、推荐系统的应用领域
(一)推荐系统的定义
推荐系统是一种用于预测用户对物品或服务的兴趣、偏好和需求的技术,旨在通过分析用户的历史行为、购买记录、社交媒体等多种数据,为用户提供个性化的推荐服务。其核心在于推荐算法,该算法通过分析用户的数据,来尽可能准确地预测用户的兴趣,然后推荐符合用户需求的物品或服务。推荐系统可以应用于多个领域,如电子商务、社交媒体、在线新闻、音乐和视频服务等。其目的是从海量的信息数据中,为用户推荐最有价值和最感兴趣的物品或服务3,解决“信息超载”问题,提升用户满意度和体验。
(二)推荐系统的研究现状
近年以来,国内外很多研究机构均对各种推荐算法的体系结构以及服务模式与方法等都进行了大量的研究。研究者们将相关研究工作进行系统性地分析和总结,给出了最新的研究方向,具体如下:
1.优化提高推荐算法的效率为了克服各种推荐算法存在的局限性,研究人员提出了不同的优化方法来提高推荐算法的效率。例如,上下文感知系统存在推荐精度不高的问题,高等人提出了一种根据用户历史行为在上下文环境中建立用户偏好模型的优化算法,相较于传统的推荐系统更具鲁棒性4。 林等人在已有的两种多准则推荐算法的基础上提出了一种新的多准则推荐算法,以提高基于多准则评分的推荐算法的性能5。 黄提出了一种基于二分图划分联合聚类的协同过滤推荐算法,用于解决传统推荐算法存在的数据稀疏性6。 Hwang等人针对传统的协同过滤电影推荐算法准确度较低的问题,提出了一种发掘电影类型的推荐算法,以提高电影推荐的精确度。这些优化算法有效地解决了推荐算法存在的问题,提高了推荐结果的准确性和鲁棒性7。
同样,由于传统协同过滤电影推荐算法在冷启动、用户打分稀疏性、评分真实性等问题上存在不足。因此,文献8提出了一种基于改进的K集合(包含有全连通的K个顶点的图)的电影推荐算法。该方法首次通过对用户群体的社交网络进行分析来推荐电影,相比于协同过滤算法,精度更高。
随着信息量的爆发性增长,推荐系统不仅需要更精准地了解用户需求和兴趣,同时需要高效处理和分析大量数据。将推荐系统与大数据技术相结合,能够提高推荐系统的性能和精度。范等人对Spark数据处理计算引擎和推荐算法进行了深入研究,提出了基于Spark的三种推荐引擎9。 此外,李还提出了基于Hadoop的并行化协同过滤推荐算法,并用于实现电影推荐系统以供用户进行TopN推荐10。另外,Ayoub团队通过降维技术和监督学习来降低群组推荐系统的复杂性,并在Spark平台上实现了分布式群组推荐。这些技术的突破为推荐系统的进一步发展提供了重要的支持。
3.推荐算法领域延伸推荐算法已经广泛地应用于各个领域,但目前已有的推荐算法并不能解决每个领域的所有问题。为此,为了进一步提高推荐效果,单一的推荐系统需要改进为混合型推荐系统。混合推荐方法是为了优化单一推荐算法而被提出的,通过融合不同单一推荐算法的优点,从而取得更好的推荐效果。例如,Guo等人采用了级联型混合方法,首先对系统中未被用户评价过的物品进行评分估计,然后使用协同过滤算法得出推荐结果,从而改善了推荐算法中存在的“长尾”问题11。
陈等人提出了一个基于增加用户信任关系的扩散算法的新型混合推荐算法。该算法在资源扩散的过程中,通过一个可以调控的参数来控制被信任用户所获取的资源,从而提升用户所选项目的被推荐率。这种算法不仅提高了用户之间的相似性准确度,还能根据用户信任信息进行个性化推荐12。 傅等人综述了将一般的协同过滤推荐算法扩展为多特征推荐算法,并提出了一种混合图书推荐算法。研究表明,混合推荐算法的推荐准确度高于单一推荐算法。这些研究成果揭示了混合推荐算法的优越性,其将可以进一步应用于各个领域的推荐系统以提高推荐效果13。
将其他领域的相关技术与推荐系统相结合以解决现有推荐算法中存在的问题,已成为一个非常有意义的研究热点。为此,黄等人结合推荐算法和排序学习,分析如何整合海量用户和项目的特征,构建更符合用户兴趣爱好的用户模型,以提升推荐算法的准确度和性能。同时,Li等14 人提出了一种基于改进的频谱聚类和转移学习的推荐算法(RAISCTL),利用特征值差和正交特征向量来成功改善了频谱聚类,进而对聚类后的评分矩阵进行分解,并获取共享群组评分矩阵,从而实现评分预测和推荐功能。与协同过滤推荐相比,该算法显著提高了推荐准确度15。
综上所述,推荐算法随着时代的不断进步和用户需求的转变,也在不断更新和进步。因此,国内外学者和研究人员不断优化传统推荐算法的同时,也顺应时代潮流,将大数据、数据挖掘等技术与推荐系统相结合,以提升推荐系统的大数据处理和计算能力。
三、国内外推荐算法相关研究
(一)基于内容的推荐算法
基于内容的推荐算法是推荐系统中的基础算法,同时也是最早提出并广泛运用的推荐算法。基于内容的推荐算法向用户进行推荐时通常包括以下三步:
1)抽取该物品的一些特征用来表征这个物品;
2)根据用户的历史行为数据信息学习出用户感兴趣的物品的特征,即构造用户偏好文档;
3)比较步骤2)得出的用户偏好文档和待推荐物品的特征(推荐项目文档),确定出关联性最大的一组物品作为推荐列表并将其推荐给用户。上述步骤提到的用户偏好文档以及推荐项目文档使用关键字来表示项目的特征,所以根据TF-IDF(term frequency-inverse document frequency)为各个项目特征确定其权重16。
TF-IDF的基本思想是:关键字k在文档D中出现的次数越多,表示k对文档D的重要性越大,则越能通过k来表达文档D的语义。另外,关键字k在另外的文档里出现的频率越高,则说明k对区别文档的贡献越少。设文档集中所含有的文档数为N,文档集中含有关键字k_i的文档数为n_i,f_ij表示关键字k_i在文档d_j中出现的次数,k_i在文档d_j中的词频TF_ij定义为:

其中z表示在文档d_j中出现的关键字。k_i在文档集中出现的逆频IDF_i定义为:

采用k维向量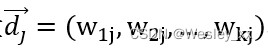 和
和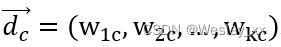 表示项目文档和用户c的配置文档,每个向量中的各个分量通过如下公式计算:
表示项目文档和用户c的配置文档,每个向量中的各个分量通过如下公式计算: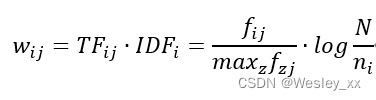
通过夹角余弦相似度获取项目文档和用户配置文档之间的相似度是最常见的方法,公式如下: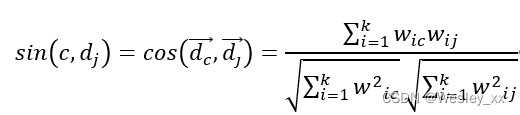
基于内容的推荐算法能很好地解决新物品的冷启动问题,同时也不会出现评分稀疏性的问题。但是该方法并不适用于多媒体资源,如图片、音乐、视频,因为基于内容的推荐算法要求内容能容易被抽取出有意义的特征,要求物品的内容特征具备良好的结构性,并且目标用户的偏好必须可以用内容的特征形式来表征。目前对于这些多媒体资源的内容特征提取还没有有效的解决方案。Shu等人在一项新的研究报告中提出,利用卷积神经网络(CNN)可以通过提取物品中的文本信息从而自动分析出物品的潜在要素并预测用户对该物品的评分,进而向用户推荐评分高的物品17。
而且该推荐方法还存在着新用户的冷启动问题,对于新加入推荐系统的用户,系统并不能立即获得用户的偏好模型。另外,在推荐结果多样性方面,由于被推荐物品的特征均与用户兴趣模型相吻合,所以得到的推荐结果都是与以前的物品基本相同的。对此,国内外多个专家学者均针对此问题提出了不同的解决方案,如文献18通过构建兴趣点的地理-社会关系模型、兴趣点聚类、兴趣点多样性选取与个性化排序从而得到兼顾多样性与个性化的兴趣点推荐列表。
先说基于内容的推荐算法的优点,首先,由于每个用户个体都是独立的,其用户属性(profile)都是根据用户对物品的喜好而获取的,因此与其他用户的行为无关。这一点与协同过滤推荐算法相反,协同过滤需要大量近邻用户的数据计算来进行推荐。基于内容的推荐算法的一个很大的优点就是无论其他用户对物品采取怎样的不恰当的措施,如在电商平台上通过多个账号将物品的排名刷得很高,也不会影响到用户个人的推荐。此外,基于内容的推荐算法具有良好的可解释性,如果需要向用户提供为何推荐这些项目给他的原因,仅需要告知用户这些项目具有某些属性,而这些属性跟用户的品味比较匹配等等。最后,能很好地解决物品的冷启动问题,只要一个新物品加入物品库,它就能立即根据其具有的属性被推荐,其被推荐的概率和旧物品是一致的。而协同过滤推荐算法对于新物品就有点束手无策,因为只有该物品被评过分或者喜欢过才有可能被推荐给用户。
而基于内容的推荐算法的缺点也很明显,首先,上文也提到,物品的特征提取较为困难,通常并不能轻易地从物品中提取出能准确刻画物品的特征,如推荐物品为图片、影音等非结构化物品时,这种物品的属性并不容易抽取。
最后一点,基于内容的推荐算法存在新用户的冷启动问题,新用户没有偏好历史,自然无法获取其用户属性(profile),所以也就无法为该用户提供推荐。
基于内容的推荐算法作为第一代个性化应用中最流行的推荐算法,由于它本身具有一些难以克服的缺陷,而且很多应用场景下也无法提供较高的推荐精度,现在大多数的推荐系统都是以其他推荐如协同过滤推荐算法为主,而以基于内容的推荐算法为辅来处理主算法在一定场景中的不精确性。
(二)协同过滤推荐算法
协同过滤推荐算法是当下各推荐平台运用最为广泛的推荐算法,自开始被应用以来就对推荐系统的发展具有长足的影响。协同过滤的核心思想是根据与目标用户的兴趣偏好相似的最近邻的偏好来进行推荐。通常,协同过滤推荐算法可划分为两种,一种是基于内存的协同过滤,包括基于用户(user-based)的协同过滤推荐算法和基于物品(item-based)的协同过滤推荐算法。基于内存的协同过滤方法通过用户—项目(user-item)评分信息,针对目标用户估计对某一项目的评分。如表一所示,空白项代表用户没有对该项目打分,”?”代表待预测的评分项。系统按照该表预测用户U_1对项目I_3的评分。评分等级为1到5的正整数,等级越高,代表用户对项目的偏好程度越高。另一种是基于模型(model-based)的协同过滤推荐算法,采用统计、机器学习等方法,通过目标用户的历史偏好搭建用户模型并据此进行推荐。
1.基于用户的协同过滤推荐算法基于用户的协同过滤推荐算法在1991年被首次提出,是最早出现的推荐方法。基本思想是通过海量的用户历史行为数据挖掘出他们对物品的偏好程度,并通过计算找到与目标用户历史兴趣偏好相似的邻居用户组。通过邻居用户组的历史偏好数据,估计目标用户对邻居用户所偏好的物品的评分,进而找出评分最高的物品并将其推荐给目标用户。
算法可分为两步,第一步根据相似度计算方法计算用户之间的相似度,得到相似度矩阵。第二步通过相应的算法来估算评分。算法为目标用户U_i (i=1,2,…,n)估计对给定项目I_j (j=1,2,…,n)的评分p_(i,j),该方法首先计算用户U_i和其他用户之间的相似度,取其他用户中为I_j评过分的用户构成集合U_i^* ,根据所有U_k∈U_i^*,对项目I_j的评分来估计U_i对I_j的评分。在此通过表1解释该方法计算p_1,3的步骤,根据余弦相似度方法计算用户之间的相似度可得:
s i m ( U 1 , U 2 ) = ( 5 × 3 + 4 × 1 ) / ( √ ( ( 5 2 + 3 2 ) ) √ ( ( 4 2 + 1 2 ) ) ) = 0.79 sim(U_1,U_2 )=(5×3+4×1)/(√((5^2+3^2)) √((4^2+1^2)))=0.79 sim(U1,U2)=(5×3+4×1)/(√((52+32))√((42+12)))=0.79
同理可得:
s i m ( U 1 , U 3 ) = 0 , s i m ( U 1 , U 4 ) = 1 , s i m ( U 1 , U 5 ) = 0.882 sim(U_1,U_3 )=0,sim(U_1,U_4 )=1,sim(U_1,U_5 )=0.882 sim(U1,U3)=0,sim(U1,U4)=1,sim(U1,U5)=0.882
进而计算:
p 1 , 3 = ( s i m ( U 1 , U 2 ) p 2 , 3 + s i m ( U 1 , U 3 ) p 3 , 3 + s i m ( U 1 , U 4 ) p 4 , 3 ) / ( s i m ( U 1 , U 2 ) + s i m ( U 1 , U 3 ) + s i m ( U 1 , U 4 ) ) = 2.53 p_1,3=(sim(U_1,U_2 ) p_2,3+sim(U_1,U_3 ) p_3,3+sim(U_1,U_4 ) p_4,3)/(sim(U_1,U_2 )+sim(U_1,U_3 )+sim(U_1,U_4 ) )=2.53 p1,3=(sim(U1,U2)p2,3+sim(U1,U3)p3,3+sim(U1,U4)p4,3)/(sim(U1,U2)+sim(U1,U3)+sim(U1,U4))=2.53
基于物品的推荐是当下业界应用最为广泛的算法,它是通过所有的用户对物品的评价,发现物品之间的相似度,从而基于用户的历史偏好数据将相类似的物品推荐给目标用户。
基于物品的协同过滤方法首先计算各个项目之间的相似程度,根据目标用户评过分的项目,预测对某一特定项目的评分。
基于内存的协同过滤通常在数据规模较小的场景下可以在线计算并实时推荐,而当数据量特别大时,此类推荐算法的计算能力和推荐效果会明显降低。而传统基于模型的推荐一般应用于离线计算,以建立模型的方式来描述用户对物品的打分行为,通过机器学习以及数据挖掘等技术从训练数据集中确定这个模型,进而根据模型估计未知的项目评分。
下面给出一个基本的评分模型19:
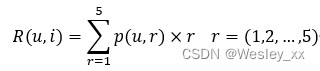
其中,R(u,i)代表用户u对项目i的打分预测,p(u,r)表示用户u打r分的概率。
基于模型的过滤技术是从数据集生成模型,并根据该模型向用户进行推荐20。 模型的学习过程可以使用数据挖掘或机器学习来完成,如奇异值分解技术、降维技术、聚类、决策树和关联规则挖掘等21。
关联规则推荐是实际应用较为广泛的一种推荐算法。关联规则即根据对物品的数据进行关联分析,发掘物品之间的相干性,进而将相关联的物品推荐给用户21。
(2)聚类。基于聚类的推荐是根据用户或者物品按照一定的距离量度方式来进行聚类,将他们分为若干个相似的群体(簇)。基于用户进行聚类首先是根据用户的特征找到若干个质心,然后将距离每个质心最近的,即和质心的特征最为相似的若干个用户分成不同的人群,再向同一个簇中的用户推荐评分较高的物品。常用的聚类算法有K-Means算法、密度聚类算法(DBSCAN)、FCM算法(模糊聚类算法)、谱聚类算法等22。
(3)贝叶斯分类器。贝叶斯分类器是数据挖掘领域中的一种经典方法,这种方法基于条件概率的定义和贝叶斯定理,它将每个属性和类标签视为随机变量。最常见的贝叶斯分类器是朴素贝叶斯分类器21。
(4)矩阵技术。矩阵分解(Matrix Factorization,MF)是基于模型的协同过滤算法的一种,原理是将一个矩阵分解为两个或多个矩阵的乘积,算法对用户项目矩阵分解,利用分解后的矩阵预测原始矩阵中的未打分项21。
4.协同过滤推荐算法的优缺点总结基于用户的协同过滤推荐算法的最大优点是对推荐对象的结构没有特殊的要求,能够处理非结构化对象,如图片、音乐、电影等。再者,基于用户的协同过滤具有可以推荐新内容的优点,能发掘在内容上截然不同的信息,用户对被推荐物品的内容信息也是事先无法预见的。这同时也是协同过滤推荐算法和基于内容的推荐的一个很大的区别。
另外,随着时间的推移,用户历史数据增多,推荐结果更加准确,更加多样化,推荐性能不断提高。而基于用户的协同过滤仍存在着一些问题需要解决,最有代表性的问题有用户评分的稀疏问题(Sparsity)和可扩展性问题(Scalability)23。另外,系统在刚开始时由于历史数据较少,存在推荐质量不高的问题。最后,算法和基于内容的推荐算法一样,存在着新用户的冷启动问题,对于新加入的用户,没有历史数据,因为无法获取和他具有类似兴趣的邻居用户组,无法进行推荐。
(三)基于深度学习的推荐算法
近几年,深度学习的发展对人们来说是有目共睹的,在图片识别、物体识别、物体分类,包括视频的识别和分类方面都有着长足的发展。另外,在NLP(Natural Language Processing)自然语言处理领域也得到了非常广泛的应用,包括机器翻译、图像处理等。深度学习具有很多优秀的特性,比如深度学习具有较为出色的表征能力,而且不需要做特征工程,可以处理复杂的非结构化数据等等。深度学习的基本思想是通过结合底层特征从数据中挖掘特征,形成更密集的高层语义的抽象,从而解决了传统机器学习中手动设计特征的问题24。对于图像和语音等包含大量未标记数据的情况,深度学习模型可以从大量未标记的训练数据中学习更有效的特征进行识别。
深度学习已经使推荐体系结构发生了巨大的变革,对推荐系统性能的提高有着愈加明显的帮助。基于深度学习的推荐系统(DLRS)克服了传统推荐模型的缺陷,提高了推荐质量,近年来得到了广泛的关注。
传统的推荐系统通常忽视用户间的社会关系,而社交推荐是每天都会发生的事情,总是向周围的人寻求推荐25。因此,为了改进推荐系统,提供更加个性化的推荐结果,需要在用户之间融合社交网络信息。
在基于社交网络的推荐系统中,最重要的是根据对用户之间社会关系的影响建模来提高推荐系统的质量。在社交网络中,所有的项目都具有位置属性,用户行为在时间和空间上具有顺序模式。对这种时空序列模式进行建模有利于提高兴趣点推荐的准确性。近年来,基于用户信任关系可以用来增强传统推荐系统的直觉,提出了几种基于信任的推荐方法。这些方法利用推断出的隐式或观察到的显式信任信息对现有的推荐系统进行全方面的改进。信任感知推荐系统是推荐系统研究的重要一步。然而,为了实现“社会推荐”的目标,这些方法还存在一些固有的局限性和不足之处,需要加以解决。
上下文感知推荐系统(Context-aware recommender systems,CARS)把上下文信息引入到推荐系统中,已成为推荐系统领域的热门话题之一。
深度学习方法可以在许多复杂的推荐场景中有效地将上下文信息集成到推荐系统中26,并通过深度学习方法得到上下文信息的潜在表示。对此,上下文感知推荐可以有效集成到各种粗糙的数据中,以缓解上下文感知推荐系统中的数据稀疏性27。
序列信息在用户行为建模中起着重要作用,各种序列推荐方法被提出且基于马尔可夫假设的方法得到了广泛的应用。近年来,基于递归神经网络(RNN)的方法已经成功地应用于多个序列建模任务中。
目前,针对基于深度学习的上下文感知推荐系统的应用,一些研究者提出了一种新的模型,即上下文感知递归神经网络(CA-RNN)。CA-RNN不再使用传统RNN模型中的常数输入矩阵和转换矩阵,而是采用自适应上下文特定输入矩阵和自适应上下文特定转换矩阵。
(四)混合推荐算法
混合推荐算法是为解决单一推荐算法所存在的问题而提出的。如协同过滤推荐算法、基于内容的推荐算法和基于上下文感知推荐算法等均存在各自的局限性,而混合推荐算法可以将单个或多个推荐算法通过某种方法进行融合以达到取长补短的推荐效果。如协同过滤推荐算法的目标是将用户和项目间的关系转化为评分预测问题,然后根据用户对项目的评分信息进行过滤或排序,进而得出推荐列表。基于内容的推荐可以很好地解决系统的冷启动问题,且不受评分稀疏性的影响,从而有着良好的用户体验,因此受到较为广泛的关注28。然而,基于内容的推荐系统只有当用户历史偏好数据信息与物品内容信息相符合时才向用户推荐,而且为用户推荐的内容会与用户之前感兴趣的物品过于相似,从而会产生过拟合问题。混合推荐可以单独应用协同过滤推荐算法、基于模型的推荐算法和基于模型的推荐算法,也可将两者及以上的推荐算法所产生的结果进行融合以改善单独算法的局限性。在此举例使用协同过滤推荐算法和基于内容的推荐算法进行混合推荐的4种方案。
1)两种算法独立进行计算并将推荐结果进行合并;
2)将基于内容的推荐算法融入协同过滤推荐算法;
3)将协同过滤推荐算法融入基于内容的推荐算法;
4)两者混合到同一个框架中形成一种新的推荐算法。
以第二种混合方案为例,协同过滤推荐算法大多只关注用户的评分,因此如果一个物品没有被用户评分,它将不会被推荐,这是新项目的冷启动问题。基于内容的推荐算法是基于用户的历史偏好信息结合项目的特征从而为用户推荐与用户历史兴趣相似度高的物品,可以有效地解决该问题。实验结果表示,混合推荐算法比单一的推荐算法具有更高的性能。
四、个性化推荐中的隐私问题
(一)数据隐私的重要性及挑战
在实现个性化推荐的过程中,所使用到的用户信息、上下文信息往往会涉及用户隐私.这些信息的使用可能会造成用户隐私泄露的问题.近年来,有许多国家制定了相应的法律保护公民的隐私安全.例如文献29中提到的通用数据保护条例GDPR(general data protection regulation),GDPR规定用户个人设备上产生的数据只能在个人设备上使用,不能将数据上传到云端或服务器.在许多推荐场景中不可避免地须要用户和服务器之间交换数据,这就须要某些技术来对所交换的数据进行处理保护用户隐私.须要指出的是,不同文献中对用户隐私保护所涵盖的范围会有所不同,本研究针对所要保护的隐私信息的类型,将已有的推荐领域中的隐私保护研究工作分为以下三类:
a.保护用户的私有敏感属性信息;
b.保护用户与物品的交互历史信息;
c.保护所有用户所提交给推荐系统的信息.
用户的私有敏感属性信息指用户的性别、年龄、职业等能被用于推断用户真实身份的信息.有些攻击者使用自己的攻击模型从用户的历史行为信息或推荐列表等信息中挖掘出用户的私有敏感属性信息.在文献30中,为使推荐模型具有保护用户私有敏感属性信息的能力,作者设计了一种对抗学习框架,将推荐模型与用户私有敏感属性信息分类模型相结合,使得保证较高推荐准确性的情况下,降低用户私有敏感属性信息泄露的可能性.在文献31中,使用差分隐私对用户敏感属性信息添加扰动,在保证信息可用性的前提下达到隐私保护的效果.
2.用户-物品交互历史信息尽管部分推荐算法并未将用户的私有敏感属性信息用于推荐任务,但也有研究人员认为用户-物品交互历史信息同样属于用户隐私信息,例如用户对物品的点击、评分等行为记录.文献32将用户社交矩阵与用户-物品矩阵结合,解决冷启动问题.文献33仅基于用户对物品的评分矩阵实现推荐任务,并将局部敏感哈希与基于位置的推荐算法相融合,实现对用户-物品评分信息的保护.文献34提出了基于联邦图神经网络的推荐模型,该模型基于用户-物品交互信息构建多个局部子图,并采用联邦学习的方法实现用户个人交互信息的本地保护.在新闻推荐任务中,文献35将联邦学习框架与推荐模型相结合,基于用户浏览新闻的历史记录信息分析用户兴趣,实现隐私保护下的个性化新闻推荐.
3.所有用户提交给推荐系统的信息此外,还有部分研究工作将上述两类用于推荐的信息全部定义为用户隐私信息,并设计算法加以保护.文献29基于GDPR法规要求提出了Deep‐Rec模型保证用户所产生的信息不再上传到服务器,仅在用户本地设备上实现推荐任务.文献36提出了匿名随机游走算法,对用户提供的信息进行匿名化处理并构建匿名化的用户社交网络图模型,通过在图模型上的随机游走实现匿名化的推荐,从而保护用户隐私信息.
(二) 隐私保护技术
针对不同类型的用户隐私保护信息,多种隐私保护技术被提出并应用于推荐系统中.本节将对近年来的相关研究进行梳理,分别从匿名化、差分隐私、联邦学习、对抗学习四类主流的隐私保护技术展开介绍.同时对这四类隐私保护技术的适用场景和优缺点进行了概述,如表1所示.
1.匿名化对数据进行匿名化是最简单直接的隐私保护方法,匿名的目的是让得到数据的一方不知道这个数据的来源,以此来保护用户隐私.匿名化的方法可分为假名化和分组聚合.
2.差分隐私差分攻击作为一种针对基于分组加密的隐私保护的攻击手段,其核心策略是根据两次攻击查询获取到的成组信息之间的差分值来推断某一用户的隐私信息.
为防止此类攻击,差分隐私技术被提出,该技术旨在令两个相邻数据集的查询结果尽可能的接近,使得无法通过两次查询的差分值推断出用户隐私信息.其中相邻数据集被定义为只有其中一项有差别的两个数据集.现有的差分隐私工作可以根据数据被进行加密的顺序分为中心化差分隐私和本地化差分隐私37.
联邦学习是一种分布式机器学习框架,一般由多个客户端和一个中央服务器组成.各个客户端在中央服务器的协调下共同训练模型,以保持训练数据的去中心化和分散性.在联邦学习中,用户的隐私数据仅用来训练自己的局部模型,无须上传到服务器,以此实现对用户隐私数据的保护.本研究把每个参与共同建模的客户端称为参与方,根据参与方之间数据分布的不同可以把联邦学习分为横向联邦学习和纵向联邦学习.
4.对抗学习实体表示学习现如今已成为推荐系统采用的主流方法.如果不对学习到的实体表示进行处理,攻击者将能基于用户表示逆向推断出用户的敏感信息,导致用户隐私的泄露.针对这一问题,对抗学习会对往输入数据中添加一些对抗扰动,被扰动后形成的对抗样本会使得逆向预测的准确度大大降低.现有推荐系统中关于对抗学习的研究主要集中于生成对抗网络(GAN)38.
五、知识图谱在个性化推荐中的应用
(一)知识图谱
知识图谱(knowledge graph,KG)最初是Google用于增强其搜索引擎功能的知识库39。本质上,知识图谱是一种揭示实体之间关系的语义网络,可以对现实世界的事物及其相互关系进行形式化地描述[40]。三元组是知识图谱的一种通用表示方式,可以定义为G=(E,R,S)。其中E={e_1,e_2,…}表示知识图谱中所有实体的集合;R={r_1,r_2,…}表示知识图谱中所有关系的集合;S={(h,r,t)}表示三元组的集合,单个三元组由头实体h、关系r和尾实体t构成。例如(Beijing,capital_of,China)表示北京是中国的首都这一事实。知识图谱是一种具有多种类型节点和边的异构图,所以知识图谱中的三元组不仅可以用于理解知识实体之间的关系,也可以存储知识实体的属性。
知识图谱中包含的实体之间丰富的语义关联,可为推荐算法提供了潜在的辅助信息来源。引入知识图谱可以让推荐算法有以下特点:
(1)精确性。知识图谱为实体引入了更多的语义关系,可以深层次地发现用户兴趣。
(2)多样性。知识图谱提供了实体间不同的关系连接模式,有利于挖掘高阶的连接关系。
(3)可解释性。知识图谱可以连接用户的历史行为信息和推荐结果,给出推荐的原因,从而增强用户对推荐结果的接受度。
(二)知识图谱在推荐系统中的应用
1.基于嵌入的推荐方法基于嵌入的方法使用知识图谱中的信息来丰富用户或项目的表示,通过知识图谱嵌入将知识图谱中的实体和关系表征为低维向量,保留了知识图谱原有的结构。知识图谱嵌入的方法主要是基于平移距离模型进行特征表示的。平移距离模型利用基于距离的评分函数,通过两个实体之间的距离对事实的合理性进行度量。主要包括TransE40 、TransH41 、TransR42 、TransD43 和TranSparse44等。
Wang等45 提出了一种将知识图谱表示引入到新闻推荐中的深度知识感知网络DKN。该模型利用KimCNN46 从新闻标题中提取实体,并进行实体链接,通过TransD将从原始知识图谱中提取的实体的关系链接子图构建特征向量,还使用实体的近邻实体提取实体的上下文信息。最后使用多通道和单词实体对齐的知识感知卷积神经网络KCNN,将单词语义和实体信息结合起来,生成知识感知的嵌入向量。此外,该模型设计了一个注意力模块捕捉用户对新闻的动态偏好,得到历史记录对用户的影响权重。最后,通过全连接层得到用户点击候选新闻的概率。Huang等47提出了一个带有键值对记忆网络(KV-MN)的循环神经网络模型KSR,其中GRU网络用于捕获序列化的用户偏好,而键值对记忆网络利用TransE学习知识库信息捕获属性级的偏好,通过这种方式可以捕获细粒度的用户偏好。该模型解决了循环神经网络捕获属性级或特征级用户偏好能力有限和可解释性差的问题。
以上方法仅使用项目及其属性信息构成的项目图集成到推荐方法中,当将用户和项目的交互数据与知识图谱一起构建用户项目图时,需进一步考虑用户项目图中边的关系来计算偏好分数。Zhang等48提出了CFKG模型,构建了一个包括用户行为和项目信息的用户项目知识图谱。
基于路径的方法通过构建用户项目图并利用图中实体的连接关系,学习用户到项目的路径之间的连接相似性进行推荐。这种方法主要的挑战是如何设计合理的路径以及如何为实体间的连接关系建模。一些推荐方法将知识图谱视为一个异构信息网络,然后利用图中的元结构,直接计算路径的连接相似性来进行推荐。
基于元结构的相似性可以作为用户和项目表示的约束,也可以用于预测用户对交互历史中相似用户或相似项目的兴趣。Yu等49 提出的Hete-MF方法提取不同的元路径并计算每个路径中的项目相似度,将正则化与矩阵分解方法相结合,获得更好的推荐。Luo等50提出的Hete-CF同时将用户间相似度、实体间相似度和用户与实体间的相似度一起正则化,提高了推荐效果。为了克服元路径表示能力有限的问题,Zhao等51用元图替换元路径提出了FMG方法捕获图中更丰富的语义,然后使用矩阵分解为每个元图中用户和项目学习隐向量。
为了充分利用知识图谱中的信息进行更好地推荐,基于传播的推荐方法整合了实体和关系的语义表示以及连接信息。基于传播的推荐方法是基于嵌入传播的思想,聚合知识图谱中多跳邻居节点的嵌入来深化实体表示。然后,获得用户和项目的丰富表示,并预测用户的偏好。
(1)用户或项目表示的细化Wang等52提出的RippleNet模型引入偏好传播的概念,不断自动地发现用户的潜在的层级兴趣。该模型抽取用户节点相连的N-hop实体节点,并利用这些邻居实体节点的嵌入表示更新用户的嵌入表示,最后通过用户向量和项目向量的内积去预测推荐结果。
类似于RippleNet模型的偏好传播机制,Tang等53 提出AKUPM模型,它根据用户的点击历史来建模用户。AKUPM首先通过TransR得到用户历史行为信息中关联实体的嵌入表示,在每个传播过程中,该模型通过自注意力层学习实体之间的关系,并学习实体在涉及不同的关系时表现出不同的特征。最后,再通过注意力机制聚合不同阶数的邻域嵌入以获得最终的用户表示。Li等54 提出的RCoLM模型以AKUPM为主干,联合训练知识图谱补全任务和推荐任务,捕捉到两项任务的互补信息,以促进两项任务的相互增强。该类模型虽然通过偏好传播的方式提高了推荐效果,但是存在忽视关系重要性、带来计算负担和冗余的问题。Wang等55提出的KGCN模型结合知识图谱和图卷积神经网络,能很好地捕捉局部邻域信息和考虑邻居节点权重以实现推荐。
然而,KGCN容易过度拟合,因为用户交互数据是整个模型的唯一数据来源。因此,在KGCN的基础上,Wang等56又提出KGCN-LS模型,增加了标签平滑度正则项,来对损失函数进行约束。标签平滑度机制在计算用户关系分数时构造交互标签。标签传播模块和偏好传播模块联合训练,进一步提高了推荐结果。这些方法以用户或项目的知识图谱为基础,同时利用实体嵌入和高阶连接信息,但在传播过程中只有用户或项目的表示得到了更新优化。
RippleNet模型及其扩展侧重于在项目知识图谱上使用嵌入传播机制,在基于用户项目知识图谱中嵌入传播机制的探索中,Wang等57提出KGAT模型,引入协同知识图谱的方法,将用户和项目知识编码为一个统一的关系图G,通过嵌入传播直接对用户和项目之间的高阶关系建模。该模型首先应用TransR获得实体的嵌入表示,递归地传播来自实体邻居节点的嵌入,增强当前节点的嵌入。
为了进一步考虑项目侧邻居和用户侧邻居之间的交互作用,Qu等58 提出KNI模型,因为用户和项目共享交互模式,使得用户嵌入和项目嵌入的细化过程不分离。Zhao等59 提出的IntentGC模型利用图中丰富的用户相关行为获得更好的推荐。为了提高效率,该模型将用户项目图拆分为用户图和项目图,还设计了一个更快的图卷积网络来更新实体的高阶表示。为了解决在传播过程中引入不相关邻居的问题,Sha等60 提出的HAKG模型通过在用户项目对的子图中传播信息来学习用户和候选项目的增强表示。该模式首先使用TransR对图中的实体嵌入进行预训练,然后使用距离感知抽样策略保留最短K条路径构建用户项目对的高阶子图,接下来,该模型在子图中通过基于注意的图神经网络使用关系感知传播来自邻居的信息,以最终表示该用户项目对。HAKG在子图的构造中过滤掉了图中相关性较低的实体,便于挖掘高阶用户项关系进行推荐,同时减少了计算开销。上述方法主要关注于如何有效地编码知识图谱中知识的关联关系,Wang等61 提出的CKAN协同知识感知注意网络模型通过协同信息与知识关联组合一起细化用户和项目的表示,突出了用户项目交互中潜在的重要的协同信号。
此外,为了在提供精确推荐的同时生成类人语义的解释,Lyu等62 提出的KEGNN模型将外部知识库中的语义知识用于用户、项目和用户项目交互三方的表示学习,并利用知识增强的语义嵌入来初始化所构建用户行为图中的实体和关系。KEGNN设计了一个用户行为学习和推理模块,并利用GRU生成器和复制模式生成文本解释,生成的解释说明了用户对评级商品的选择和购买原因。通过协同表示用户和项目能在更大程度上探索高阶连接模式,但缺点是会带来不相关的实体,这可能会误导用户在聚合过程中的兴趣。基于传播的推荐方法受益于知识图谱的语义表示和路径关联,利用嵌入传播的思想来增强知识图谱中具有多跳邻居节点的用户或项目的表示。基于传播的推荐方法的传播过程可以被视为在知识图谱中发现用户的偏好模式,这些方法结合了基于嵌入的方法和基于路径的方法的优势,兼具准确性和可解释性。
六、结语
目前,基于内容的推荐算法、协同过滤推荐、基于模型的推荐、基于深度学习的推荐等几种比较常用的推荐算法已广泛地运用于包括电商、多媒体等在内的各个方面。现存的推荐系统在大幅度提升用户体验的同时,仍存在着许多问题和局限性,一方面,现有的推荐模型很难兼顾隐私性与推荐准确性,而且隐私保护的推荐算法所解决的任务较为单一.另一方面,在精确性、多样性和可解释性效果呈现当中,也有着极大的提高空间。本研究对国内外推荐算法进行分类整理,在此基础上综述了匿名化、差分隐私、联邦学习和对抗学习四种隐私保护技术,并对不同技术的适用场景、优缺点、研究现状等进行了归纳和总结.进一步探讨推荐系统中的隐私保护问题,并引入知识图谱的推荐算法提高了推荐算法的精确性、多样性和可解释性,拥有传统推荐算法所不具备的优势,希望能促进该领域的发展。
王利娥,李小聪,刘红翼.融合知识图谱和差分隐私的新闻推荐方法[J].计算机应用,2022,42(5): 1339-1346. ↩︎
李效光,李晖,李凤华,等差分隐私综述[J].信息安全学报,2018,3(5): 92-104. ↩︎
吴月萍,郑建国.协同过滤推荐算法[J].计算机工程与设计,2011,32(9): 3019-3021+3098. ↩︎
高全力.上下文感知推荐系统关键问题研究[D].西安:西北大学,2017: 1-12. ↩︎
林栢全,肖菁.基于矩阵分解与随机森林的多准则推荐算法[J].华南师范大学学报(自然科学版),2019,51(2): 117-122. ↩︎
黄乐乐,马慧芳,李宁,等.基于二分图划分联合聚类的协同过滤推荐算法[J].计算机工程与科学,2019(11): 19. ↩︎
HWANG T G,PARK C S,HONG J H,et al.An algorithm for movie classification and reco-mmendation using genre correlation [J].Multimed-ia Tools and Applications,2016,75(20):12843-12858. ↩︎
VILAKONE P,PARK D S,XINCHANG K,et al.An Efficient movie recommendation algorithm based on improved k-clique [J].Human-centric Computing and Information Sciences,2018,8(1):38. ↩︎
范继涛.基于Spark平台的推荐系统研究与应用[D].大连:大连海事大学,2018:1-13. ↩︎
李灿.基于Hadoop的并行化协同过滤推荐算法研究[D].杨凌:西北农林科技大学,2016:1-3 ↩︎
GUO Y, DENG G. Hybrid recommendation al-gorithm of item cold-start in collaborative filtering system [J].Computer Engineering,2008,34(23):11-13. ↩︎
陈玲姣,蔡世民,张千明,等.基于信任关系的资源分配推荐算法改进研究[J].电子科技大学学报,2019,48(3):449-455. ↩︎
傅汉霖,顾小宇.图书推荐算法综述[J].计算机时代,2016(12):21-23. ↩︎
黄震华,张佳雯,田春岐,等.基于排序学习的推荐算法研究综述[J].Journal of Software,2016,3:691-713. ↩︎
LI X, WANG Z, HUR, et al. Recommendationalgorithm based on improved spectral clusteringand transfer learning [J].Pattern Analysis and Applications,2019,22(2): 633-647. ↩︎
杨博,赵鹏飞.推荐算法综述.Review of the Art of Recommendation Algorithms [J].山西大学学报(自然科学版),2011,34(3):337-350. ↩︎
SHU J,SHEN X,LIU H,et al. A content-based recommendation algorithm for learning resources[J]. Multimedia Systems,2018,24(2): 163-173. ↩︎
孟祥福,张霄雁,唐延欢,等.基于地理社会关系的多样性与个性化兴趣点推荐[J].计算机学报,2019(11):15. ↩︎
BREESE J S,HECKERMAN D,KADIE C. Empirical analysis of predictive algorithms for collaborative filtering[J]. arXiv preprint arXiv: 1301.7363,2013:43-52. ↩︎
王俊淑,张国明,胡斌.基于深度学习的推荐算法研究综述[J].南京师范大学学报(工程技术版),2018(4): 33-43. ↩︎
ISINKAYE F O,FOLAJIMi Y O,OJOKOH B A. Recommendation systems:Principles,methods and evaluation[J].Egyptian Informatics Journal, 2015,16(3): 261-273. ↩︎ ↩︎ ↩︎ ↩︎
SU X,KHOSHGOFTAAR T M. A survey of collaborative filtering techniques[J]. Advances in artificial intelligence,2009,2009: 1-19. ↩︎
张亮,赵娜.改进的协同过滤推荐算法[J].计算机系统应用,2016(7):147-150. ↩︎
PENG Y,ZHU W,ZHAO Y,et al. Crossmedia analysis and reasoning: advances and directions[J]. Frontiers of Information Technology & Electronic Engineering,2017,18(1): 44-57. ↩︎
ZHENG Y,TANG B,DING W,et al. A neural autoregressive approach to collaborative filtering[C]// International conference on arXiv preprint arXiv: 1605.09477,machine Learning,PMLR,2016:764-773. ↩︎
LAROCHELLE H,MURRAY I.The neural auto-regressive distribution estimator[C]//Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics,2011:29-37. ↩︎
MA H,ZHOU D,LIU C,et al. Recommender systems with social regularization[C]//Proc-eedings of the fourth ACM international confe-rence on Web search and data mining,2011: 287-296. ↩︎
张宜浩,朱小飞,徐传运,等.基于用户评论的深度情感分析和多视图协同融合的混合推荐方法[J].计算机学报,2019,42(6):1316-1333. ↩︎
HAN J L,MA Y,MEI Q Z,et al.DeepRec:on-de‐ vice deep learning for privacy-preserving sequential rec‐ ommendation in mobile commerce[C]//Proc of the Web Conference 2021.Ljubljana:ACM,2021:900-911. ↩︎ ↩︎
BEIGI G,MOSALLANEZHAD A,GUO R C,et al.Privacy-aware recommendation with private attribute protection using adversarial learning[C]// Proc of the 13th International Conference onWeb Search and Data Mining. Houston:Assoc-iation for Computing Machinery,2020:34-42. ↩︎
XIAO Y, XIAO L, LU X Z, et al. Deep-reinforce‐ ment-learning-based user profile perturbation for privacy aware recommendation[J].IEEE Internet of Things Jour‐ nal,2021,8(6):4560-4568. ↩︎
WANG F, ZHONG W Y, XU X L, et al. Privacy aware cold-start recommendation based on collaborative filtering and enhanced trust[C]//Proc of 2020 IEEE 7th International Conference on Data Science and Advanced Analytics.Sydney:IEEE,2020:655-662. ↩︎
LIN W M, ZHANG X Y, QI L Y, et al. Location aware service recommendations with privacy-preservation in the internet of things[J]. IEEE Transactions on Computational Social Systems,2021,8(1):227-235. ↩︎
WU C H,WU F Z,CAO Y,et al.FedGNN: federated graph neural network for privacy preserving recommendation[C]// Proc of ACM SIGKDD Conference on Knowledge Discovery and Data Mining.New York:ACM,2021:1-9. ↩︎
YI J W,WU F Z,WU C H,et al.Efficient-FedRec: efficient federated learning frameworkfor privacy preserving news recommendation[C]// Proc of the 2021 Conference on Empirical Methods in Natural Language Processing. Punta Cana: Association for Computational Linguistics,2021:2814-2824. ↩︎
WAINAKH A,GRUBE T,DAUBERT J, et al. Efficient privacy-preserving recommendations based on so‐ cial graphs[C]// Proc of RecSys’ 19.New York:ACM, 2021:78-86. ↩︎
HOU D K,ZHANG J,MA J M,et al.App-lication of differential privacy for collaborative filtering based rec‐ ommendation system: a su-rvey[C]// Proc of 2021 12th International Symposium on Parallel Architectures Algo‐ rithms and Programming (PAAP).Xi, an:IEEE,2021: 97-101. ↩︎
DELDJOO Y,NOIA T D,MERRA F A. Adver-sarial machine learning in recommender system(AML-Rec‐ Sys) [C]//Proc of the 13th Internat-ional Conference on Web Search and Data Mining.Houston:Association for Computing Machinery,2020:869-872. ↩︎
SINGHAL A. Introducing the knowledge graph:Things,not strings[J].Official Google Blog,2012,5:16. ↩︎
BORDES A,USUNIER N,GARCIA-DURÁN A,et al. Translating embeddings for modeling multi- relational data[C]//Advances in Neural Information Processing Systems,2013. ↩︎
WANG Z,ZHANG J,FENG J,et al. Knowl-edge graph embedding by translating on hyp-erplanes[C]// Proceedings of the National Confer-ence on Artificial Intelligence, 2014:1112-1119. ↩︎
LIN Y,LIU Z, SUN M, et al. Learning entity and relation embeddings for knowledge graph completion[C]//Proceedings of the 29th AAAI Conference on Artificial Intelligence,2015. ↩︎
JI G,HE S,XU L,et al. Knowledge graph embedding via dynamic mapping matrix[C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language,Asian Federation of Natural Language Processing,2015:687-696. ↩︎
JI G,LIU K,HE S,et al. Knowledge graph completion with adaptive sparse transfer matrix[C]///Proceedings of the 30th AAAI Conference on Artificial Intelligence, 2016:985-991. ↩︎
WANG H,ZHANG F,XIE X,et al. DKN:Deep knowledge aware network for news reco-mmendation[C]//Proceedings of the World WideWeb Conference,2018:1835-1844. ↩︎
KIM Y. Convolutional neural networks for sentence classification[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing,2014 ↩︎
HUANG J,ZHAO W X,DOU H,et al. Imp-roving sequential recommendation with knowledge- enhanced memory networks[C]//Proceedings of the 41st International ACM SIGIR Conference on Research and Development in Information Retrieval,2018:505-514. ↩︎
ZHANG F,YUAN N J,LIAN D,et al. Col-laborative knowledge base embedding for reco-mmender systems[C]// Proceedings of the ACMSIGKDD International Conference on Knowled-ge Discovery and Data Mining,2016:353-362. ↩︎
YU X,REN X,GU Q,et al. Collaborative filtering with entity similarity regularization in heterogeneous information networks[C]// Proce-edings of IJCAI-HINA,2013. ↩︎
LUO C,PANG W,WANG Z,et al. Hete-CF:Social-based collaborative filtering recommenda-tion using heterogeneous relations[C]// Proceed-ings of the IEEE International Conference on Data Mining,2014:917-922. ↩︎
ZHAO H,YAO Q,LI J,et al. Meta-graph based recommendation fusion over heterogeneous information networks[C]// Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2017:635-644. ↩︎
WANG H,ZHANG F,WANG J,et al. Ripp-leNet:Propagating user preferences on the kn-owledge graph for recommender systems[C]// Proceedings of the International Conference on Information and Knowledge Management,2018:417-426. ↩︎
TANG X,WANG T,YANG H,et al. AKUPM: Attention enhanced knowledge-aware user pref-erence model for recommendation[C]// Proceed-ings of the ACM SIGKDD International Conf-erence on Knowledge Discovery and Data Mi-ning,2019:1891-1899. ↩︎
LI Q,TANG X,WANG T,et al. Unifying taskor-iented knowledge graph learning and recomme-ndation[J].IEEE Access,2019,7:115816-115828. ↩︎
WANG H,ZHAO M,XIE X,et al. Knowledge graph convolutional networks for recommender systems[C]// Proceedings of the World Wide Web Conference,2019: 3307-3313. ↩︎
WANG H,LESKOVEC J,ZHANG F,et al. Knowledge aware graph neural networks with label smoothness regularization for recommender systems[C]//Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2019:968-977. ↩︎
WANG X, HE X, CAO Y, et al. KGAT: Kno-wledge graph attention network for recommendation[C]//Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2019:950-958. ↩︎
QU Y,BAI T,ZHANG W,et al. An end-to-end neighborhood based interaction model for knowledge- enhanced recommendation[C]//Proceedings of the 1st International Workshop on Deep Learning Practice for High Dimensional Sparse Data,2019:1-9. ↩︎
ZHAO J,ZHOU Z,NING W,et al. IntentGC:A scalable graph convolution framework fusing heterogeneous information for recommendation[C]//Proceedings of the ACM SIGKDD Interna-tional Conference on Knowledge Discovery and Data Mining,2019:2347-2357. ↩︎
SHA X, SUN Z, ZHANG J. Hierarchical atent-ive knowledge graph embedding for personali-zed recommendation[J]. Electronic Commerce Research and Applications,2021, 48:101071. ↩︎
WANG Z,LIN G,TAN H et al. CKAN:Co-llaborative knowledge- aware attentive network for recommender systems[C]//Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval,2020:219-228. ↩︎
LYU Z,WU Y,LAI J,et al. Knowledge enhanced graph neural networks for explainable recommendation[J].IEEE Transactions on Knowledge and Data Engineering,2022(1). ↩︎
网址:国内外推荐算法研究述评 https://www.yuejiaxmz.com/news/view/564414
相关内容
推荐算法综述旅行服务平台个性化推荐算法研究
个性化推荐算法概述与展望
个性化推荐算法优化技术研究与应用推广方案.doc
国内自我调控学习研究述评(1998~2023)
国内外关于人的精神生活的研究述评
美食推荐系统研究或设计的国内外现状和发展趋势
基于协同过滤算法的美食推荐系统研究与实现
基于用户评价的个性化饮食推荐方法研究
基于页面聚类的个性化推荐算法研究
随便看看
最新动态分享
- 卧室家具选什么木好呢,卧室家具用什么木材好
- 清洁家具有哪些小妙招
- 教你一秒变达人 家具保养保洁攻略
- 家具清洁养护的7个正确姿势
- 家里怎么清洗干净家具
- 还在为家具清理发愁,这篇攻略可以帮你大忙
- 家具保养技能
- 小妙招保养攻略,让家具陪伴你往后的每一个新年
- 10个家居清洁技巧
- 新家具如何妥善打理?打理过程有哪些技巧?
热点动态分享
- 460
- 296
- 278
- 223
- 221
- 184
- 163
- 145
- 120
- 109

