AI让手机任务自动跑起来!我国高校最新研究,简化移动设备操作
教育动态:全国高校新增硕博研究生招生计划 #生活常识# #教育资讯#
MOE KLINNS Lab投稿
量子位 | 公众号 QbitAI
AI解放碳基生物双手,甚至能让你的手机自己玩自己!
你没听错——这其实就是移动任务自动化。
在AI飞速发展下,这逐渐成为一个新兴的热门研究领域。
移动任务自动化利用AI精准捕捉并解析人类意图,进而在移动设备(手机、平板电脑、车机终端)上高效执行多样化任务,为那些因认知局限、身体条件限制或身处特殊情境下的用户提供前所未有的便捷与支持。
帮助视障人群用户完成导航、阅读或网上购物辅助老年人使用手机,跨越数字鸿沟帮助车主在驾驶过程中完成发送短信或调节车内环境替用户完成日常生活中普遍存在的重复性任务
妈妈再也不嫌重复设置多个日历事项会心烦了。
最近,来自西安交通大学智能网络与网络安全教育部重点实验室(MOE KLINNS Lab)的蔡忠闽教授、宋云鹏副教授团队(团队主要研究方向为智能人机交互、混合增强智能、电力系统智能化等),基于团队最新AI研究成果,创新性提出了基于视觉的移动设备任务自动化方案VisionTasker。
这项研究不仅为普通用户提供了更智能的移动设备使用体验,也展现出了对特殊需求群体的关怀与赋能。

基于视觉的移动设备任务自动化方案
团队提出了VisionTasker,一个结合基于视觉的UI理解和LLM任务规划的两阶段框架,用于逐步实现移动任务自动化。
该方案有效消除了表示UI对视图层次结构的依赖,提高了对不同应用界面的适应性。
值得注意的是,利用VisionTasker无需大量数据训练大模型。

VisionTasker从用户以自然语言提出任务需求开始工作, Agent开始理解并执行指令。
具体实现如下:
1、用户界面理解
VisionTasker通过视觉的方法做UI理解来解析和解释用户界面。
首先Agent识别并分析用户界面上的元素及布局,如按钮、文本框、文字标签等。
然后,将这些识别到的视觉信息转换成自然语言描述,用于解释界面内容。
2、任务规划与执行
接下来,Agent利用大语言模型导航,根据用户的指令和界面描述信息做任务规划。
将用户任务拆解为可执行的步骤,如点击或滑动操作,以自动推进任务的完成。
3、持续迭代以上过程
每一步完成后,Agent都会根据最新界面和历史动作更新其对话和任务规划,确保每一步的决策都是基于当前上下文的。
这是个迭代的过程,将持续进行直到判断任务完成或达到预设的限制。
用户不仅能从交互中解放双手,还可以通过可见提示监控任务进度,并随时中断任务,保持对整个流程的控制。
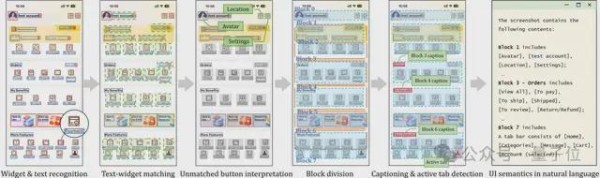
首先是识别界面中的小部件和文本,检测按钮、文本框等元素及其位置。
对于没有文本标签的按钮,利用 CLIP 模型基于视觉设计来推断其可能功能。
随后,系统根据 UI 布局的视觉信息进行区块划分,将界面分割成多个具有不同功能的区块,并对每个区块生成自然语言描述。
这个过程还包括文本与小部件的匹配,确保正确理解每个元素的功能。
最终,所有这些信息被转化为自然语言描述,为大语言模型提供清晰、语义丰富的界面信息,使其能够有效地进行任务规划和自动化操作。
实验评估
实验评估部分,该项目提供了对三种UI理解的比较分析,分别是:
GPT-4VVH(视图层级)VisionTasker方法

对比显示,VisionTasker在多个维度上比其他方法有显著优势。
此外,在处理跨语言应用时也表现出了良好的泛化能力。

△ 实验1中使用到的常见UI布局
表明VisionTasker的以视觉为基础的UI理解方法在理解和解释UI方面具有明显优势,尤其是在面对多样化和复杂的用户界面时尤为明显。
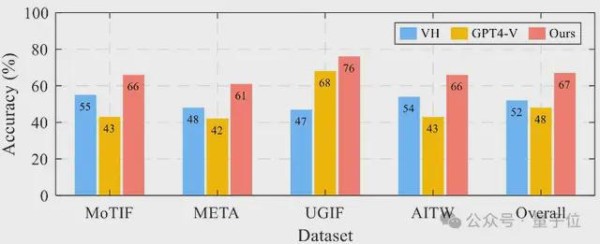
△跨四个数据集的单步预测准确性
文章还进行了单步预测实验,根据当前的任务状态和用户界面,预测接下来应该执行的动作或操作。
结果显示,VisionTasker在所有数据集上的平均准确率达到了67%,比基线方法提高了15%以上。
真实世界任务:VisionTasker vs 人类
实验过程中,研究人员设计了147个真实的多步骤任务来测试VisionTasker的表现,这些任务涵盖了国内常用的42个应用程序。
与此同时,团队还设置了人类对比测试,由12名人类评估者手动执行这些任务,然后VisionTasker的结果进行比较。
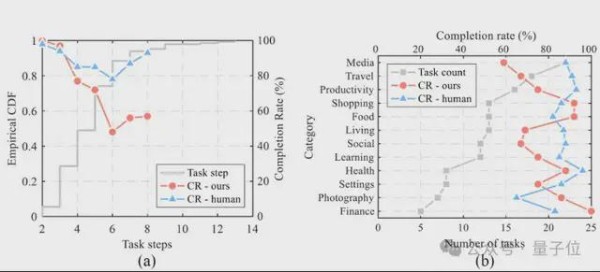
结果显示,VisionTasker在大多数任务中能达到与人类相当的完成率,并且在某些不熟悉的任务中表现优于人类。

△实际任务自动化实验的结果 “Ours-qwen”是指使用开源Qwen实现VisionTasker框架,”Ours”表示使用文心一言作为LLM
团队还评估了VisionTasker在不同条件下的表现,包括使用不同的大语言模型(LLM)和编程演示(PBD)机制。
VisionTasker 在大多数直观任务中达到了与人类相当的完成率,在熟悉任务中略低于人类但在不熟悉任务中优于人类。
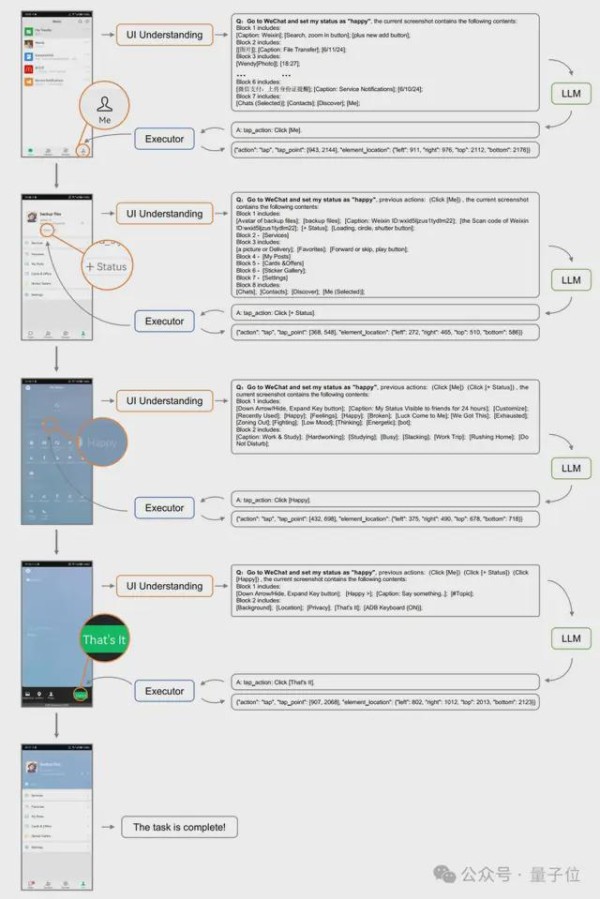
△VisionTasker逐步完成任务的展示
结论
作为一个基于视觉和大模型的移动任务自动化框架,VisionTasker克服了现阶段移动任务自动化对视图层级结构的依赖。
通过一系列对比实验,证明其在用户界面表现上超越了传统的编程演示和视图层级结构方法。
它在4个不同的数据集上都展示了高效的UI表示能力,表现出更广泛的应用性;并在Android手机上的147个真实世界任务中,特别是在复杂任务的处理上,表现了出超越人类的任务完成能力。
此外,通过集成编程演示(PBD)机制,VisionTasker在任务自动化方面有显著的性能提升。
目前,该工作已以正式论文的形式发表于2024年10月13-16日在美国匹兹堡举行的人机交互顶级会议UIST(The ACM Symposium on User Interface Software and Technology)。
UIST是人机交互领域专注于人机界面软件和技术创新的CCF A类顶级学术会议。

原文链接:https://dl.acm.org/doi/10.1145/3654777.3676386
项目链接:https://github.com/AkimotoAyako/VisionTasker
网址:AI让手机任务自动跑起来!我国高校最新研究,简化移动设备操作 https://www.yuejiaxmz.com/news/view/577481
相关内容
AI 让手机任务自动“跑”起来!我国高校最新研究,简化移动设备操作AI让手机任务自动“跑”起来!我国高校最新研究,简化移动设备操作
AI让手机任务自动“跑”起来!中国高校最新研究,简化移动设备操作
我国高校创新研究:AI技术实现手机任务自动化,简化操作体验
未来已来!AI如何让你的手机任务自动化?
AI驱动的手机任务自动化:解放双手、提升效率的未来科技
智能AI助手Claude变革日常任务管理,自动化未来触手可及
Vivo OriginOS 5:AI智能助手引领移动操作系统新潮流
任务自动化工具
新加坡国立大学研究:Claude智能体实现游戏与办公任务自动化,开启GUI智能时代
随便看看
最新动态分享
- 延边图书馆“换书大集”活动即日起征集图书!
- 旧书跳蚤市场活动方案.docx
- 书传万家 香飘乾安——乾安县图书馆第五届“换书大集”即将开市!
- 大学旧书置换活动策划
- 旧书置换活动.pptx
- 外国语学院举办“旧书置换,以书会友”活动
- 这个周末平潭图书馆举办以书换书活动
- 读书节系列活动:二年级换书活动体会
- 流动书香,分享悦读—换书大集活动圆满结束
- 换书活动方案.doc
热点动态分享
- 2690
- 2600
- 2239
- 2195
- 2139
- 1743
- 1637
- 1488
- 1300
- 1296

