全连接层优化秘籍:提升神经网络性能的实用技巧
使用Keras的批量归一化提升深层神经网络的泛化能力 #生活技巧# #学习技巧# #深度学习技巧#
目录
1. 全连接层概述 2. 全连接层优化理论 2.1 激活函数的选择与影响 2.2 权重初始化策略 2.3 正则化技术 3. 全连接层优化实践 3.1 超参数调优技巧 3.2 数据预处理与归一化 3.3 梯度下降算法的优化 4.1 Dropout与Batch Normalization 4.1.1 Dropout 4.1.2 Batch Normalization 4.2 稀疏连接与剪枝技术 4.2.1 稀疏连接 4.2.2 剪枝技术 5. 全连接层优化案例研究**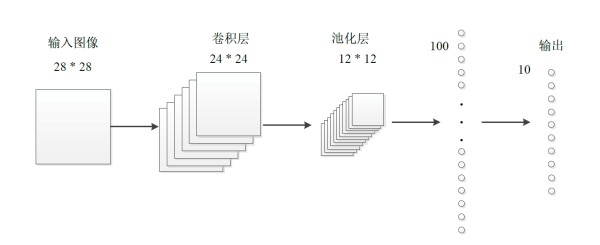
1. 全连接层概述
全连接层(Fully Connected Layer,FC Layer)是神经网络中一种重要的层,它将前一层的所有神经元与下一层的所有神经元完全连接。全连接层主要用于将特征映射转换为输出,并在神经网络中执行线性变换和非线性激活。
全连接层的工作原理是将前一层的输出作为输入,并通过一个权重矩阵和偏置向量进行线性变换。线性变换后的结果再通过一个非线性激活函数,例如 ReLU 或 sigmoid,进行非线性映射。非线性激活函数引入非线性,使神经网络能够学习复杂的关系和模式。
全连接层在神经网络中扮演着至关重要的角色,它将特征提取和分类联系起来。通过优化全连接层的参数和超参数,可以显著提升神经网络的性能和泛化能力。
2. 全连接层优化理论
2.1 激活函数的选择与影响
激活函数是神经网络中至关重要的组成部分,它决定了神经元输出的非线性行为。在全连接层中,激活函数的选择对网络性能有显著影响。
常见激活函数:
激活函数 表达式 特点 Sigmoid f(x) = 1 / (1 + e^(-x)) S形曲线,输出范围为 (0, 1) Tanh f(x) = (e^x - e^(-x)) / (e^x + e^(-x)) 双曲正切函数,输出范围为 (-1, 1) ReLU (Rectified Linear Unit) f(x) = max(0, x) 线性整流函数,输出范围为 [0, ∞) Leaky ReLU f(x) = max(0.01x, x) 类似 ReLU,但对于负输入有轻微斜率 ELU (Exponential Linear Unit) f(x) = x if x >= 0, α * (e^x - 1) if x < 0 平滑 ReLU,对于负输入有非零斜率选择原则:
**非线性:**激活函数必须是非线性的,以打破线性模型的局限性。 **梯度:**激活函数的导数应该容易计算,以方便反向传播训练。 **输出范围:**激活函数的输出范围应与网络结构和任务目标相匹配。2.2 权重初始化策略
权重初始化对于全连接层的性能至关重要。不当的初始化可能会导致网络训练困难或收敛到局部最优值。
常见权重初始化策略:
初始化策略 表达式 特点 随机均匀分布: w ~ U(-a, a) 权重从均匀分布中随机采样 随机正态分布: w ~ N(0, σ^2) 权重从正态分布中随机采样 Xavier 初始化: w ~ N(0, 2 / (n_in + n_out)) 权重根据输入和输出神经元的数量进行缩放 He 初始化: w ~ N(0, 2 / n_in) 权重根据输入神经元的数量进行缩放,适用于 ReLU 激活函数选择原则:
**打破对称性:**权重初始化应打破权重对称性,以防止神经元陷入对称状态。 **梯度流动:**初始化策略应确保权重具有适当的梯度,以促进网络训练。 **任务相关性:**对于特定任务,可能存在更适合的初始化策略。2.3 正则化技术
正则化技术旨在防止过拟合,即模型对训练数据拟合过度而无法泛化到新数据。
常见正则化技术:
正则化技术 表达式 特点 L1 正则化: R(w) = λ * ∑ w L2 正则化: R(w) = λ * ∑w^2 惩罚权重平方值 Dropout: 随机丢弃一部分神经元,防止过拟合 数据增强: 通过变换和合成生成更多训练数据,增加模型泛化能力选择原则:
**正则化强度:**正则化项的强度(λ)应通过超参数调优进行选择。 **正则化类型:**L1 正则化倾向于产生稀疏权重,而 L2 正则化倾向于产生平滑权重。 **任务相关性:**对于特定任务,可能存在更适合的正则化技术。3. 全连接层优化实践
3.1 超参数调优技巧
超参数调优是优化全连接层性能的关键步骤。这些超参数包括:
**学习率:**控制梯度下降算法中权重更新的步长。 **批大小:**一次训练中使用的数据样本数量。 **迭代次数:**训练模型的次数。代码块:
# 超参数设置learning_rate = 0.01batch_size = 64num_epochs = 100
逻辑分析:
learning_rate设置为0.01,表示权重更新的步长为0.01。 batch_size设置为64,表示一次训练使用64个数据样本。 num_epochs设置为100,表示训练模型100次。参数说明:
learning_rate:学习率,取值范围为0到1。 batch_size:批大小,取值范围为1到训练数据集大小。 num_epochs:迭代次数,取值范围为1到任意正整数。3.2 数据预处理与归一化
数据预处理和归一化可以提高全连接层的训练稳定性和性能。
**数据预处理:**包括数据清洗、缺失值处理和特征缩放。 **归一化:**将数据映射到特定范围,以消除不同特征之间的尺度差异。代码块:
# 数据预处理和归一化from sklearn.preprocessing import StandardScaler# 标准化数据scaler = StandardScaler()X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)
逻辑分析:
使用StandardScaler对训练数据和测试数据进行标准化。 标准化将数据映射到均值为0、标准差为1的范围内。 这有助于消除不同特征之间的尺度差异,提高训练稳定性。3.3 梯度下降算法的优化
梯度下降算法是训练全连接层的主要方法。以下是一些优化梯度下降的技巧:
**动量:**使用前一次梯度更新的加权平均值来更新权重。 **RMSprop:**使用过去梯度平方值的加权平均值来调整学习率。 **Adam:**结合动量和RMSprop的优化算法,具有快速收敛性和较小的振荡。代码块:
# 优化梯度下降算法from keras.optimizers import Adam# 使用Adam优化器optimizer = Adam(learning_rate=0.001)
逻辑分析:
使用Adam优化器,它结合了动量和RMSprop的优点。 learning_rate设置为0.001,表示优化器的初始学习率。 Adam优化器可以快速收敛并减少训练过程中的振荡。4.1 Dropout与Batch Normalization
4.1.1 Dropout
简介
Dropout是一种正则化技术,通过随机丢弃神经网络中的部分神经元来防止过拟合。在训练过程中,Dropout以一定概率(通常为0.5)将神经元的输出置为0,迫使网络学习更鲁棒的特征。
代码示例
import tensorflow as tf# 创建一个带有Dropout层的全连接层dropout_layer = tf.keras.layers.Dropout(rate=0.5)# 输入数据input_data = tf.random.normal((100, 100))# 经过Dropout层output_data = dropout_layer(input_data)
逻辑分析
Dropout层以0.5的概率随机将神经元的输出置为0。这迫使网络学习更鲁棒的特征,因为单个神经元的输出不再对网络的整体性能至关重要。
4.1.2 Batch Normalization
简介
Batch Normalization是一种正则化技术,通过将神经网络的激活值归一化为均值为0、方差为1的分布来提高训练稳定性和收敛速度。这有助于缓解梯度消失和爆炸问题,并允许使用更高的学习率。
代码示例
import tensorflow as tf# 创建一个带有Batch Normalization层的全连接层batch_norm_layer = tf.keras.layers.BatchNormalization()# 输入数据input_data = tf.random.normal((100, 100))# 经过Batch Normalization层output_data = batch_norm_layer(input_data)
逻辑分析
Batch Normalization层将神经网络的激活值归一化为均值为0、方差为1的分布。这有助于缓解梯度消失和爆炸问题,并允许使用更高的学习率。归一化过程如下:
output = (input - mean) / sqrt(variance + epsilon)
其中:
input:输入激活值 mean:输入激活值的均值 variance:输入激活值的方差 epsilon:一个很小的常数,以防止除以04.2 稀疏连接与剪枝技术
4.2.1 稀疏连接
简介
稀疏连接是一种优化技术,通过减少全连接层中连接的数量来提高计算效率和模型大小。稀疏连接只保留最重要的连接,而将其他连接置为0。
代码示例
import tensorflow as tf# 创建一个稀疏连接的全连接层sparse_layer = tf.keras.layers.Dense(100, use_bias=False, kernel_regularizer=tf.keras.regularizers.l1(0.01))# 输入数据input_data = tf.random.normal((100, 100))# 经过稀疏连接层output_data = sparse_layer(input_data)
逻辑分析
稀疏连接层使用L1正则化器,该正则器会惩罚权重矩阵中的非零元素。这导致许多权重被置为0,从而减少了连接的数量。
4.2.2 剪枝技术
简介
剪枝技术是一种优化技术,通过在训练过程中移除不重要的连接来进一步减少全连接层的连接数量。剪枝技术可以基于连接的权重、梯度或其他指标来确定哪些连接可以移除。
代码示例
import tensorflow as tf# 创建一个全连接层,并使用剪枝技术pruned_layer = tf.keras.layers.Dense(100, use_bias=False, kernel_constraint=tf.keras.constraints.MaxNorm(max_value=1.0))# 输入数据input_data = tf.random.normal((100, 100))# 经过剪枝层output_data = pruned_layer(input_data)
逻辑分析
剪枝层使用MaxNorm约束,该约束将权重矩阵中的所有元素限制在[-1, 1]的范围内。这导致一些权重被剪枝(置为0),从而减少了连接的数量。
5. 全连接层优化案例研究**
在实际应用中,全连接层优化技术在不同的任务中表现出不同的效果。以下是一些常见的案例研究:
5.1 图像分类任务中的优化技巧
**激活函数选择:**ReLU激活函数通常用于图像分类任务,因为它具有非线性特性和较快的收敛速度。 **权重初始化:**Xavier初始化或He初始化可以有效防止梯度消失或爆炸问题。 **正则化技术:**L2正则化或Dropout可以防止过拟合,提高泛化能力。 **超参数调优:**学习率、批次大小和训练轮数等超参数需要通过网格搜索或贝叶斯优化等方法进行调优。5.2 自然语言处理任务中的优化策略
**嵌入层:**使用预训练的词嵌入层可以捕获单词的语义信息。 **注意力机制:**Transformer模型中的自注意力机制可以捕捉句子中单词之间的关系。 **正则化技术:**L1正则化可以促进稀疏性,提高模型的可解释性。 **数据预处理:**分词、词干提取和文本归一化等预处理技术可以提高模型性能。5.3 时序预测任务中的优化方法
**循环神经网络(RNN):**LSTM或GRU等RNN可以处理序列数据中的时序依赖性。 **注意力机制:**注意力机制可以帮助模型专注于序列中重要的部分。 **正则化技术:**Dropout或L2正则化可以防止过拟合,提高模型的鲁棒性。 **数据增强:**使用滑动窗口、随机采样等数据增强技术可以丰富训练数据集。网址:全连接层优化秘籍:提升神经网络性能的实用技巧 https://www.yuejiaxmz.com/news/view/628082
相关内容
提升网速的小技巧(优化网络连接,让上网更顺畅)提高网络延迟的解决技巧(优化网络连接)
网络连接优化:提升网速的技巧与方法
卷积神经网络优化技巧:提升性能与降低复杂度1.背景介绍 卷积神经网络(Convolutional Neural Netw
提高网络速度的方法与技巧(优化网络连接)
YOLO神经网络源码优化:提升目标检测模型性能和效率的秘诀
WiFi优化完全指南:提高家庭网络连接的必备技巧
如何正确连接路由器并优化网络性能的方法
【Scrapy性能提升秘籍】:最大化爬虫效率与稳定性的技巧
提升家庭WiFi网速的技巧(优化网络设置)
随便看看
最新动态分享
- 基于遗传算法的智能电力系统优化——以IEEE30节点输电网为例
- 基于分时电价策略的家庭能量系统优化(Matlab代码实现)
- 电力管理系统有哪些功能?
- 粒子群算法优化电力系统PMU配置:基于MATLAB的IEEE30 39 57 118系统仿真验证
- 电能能耗监测管理系统,优化能源使用效率
- 【电行业工作者学习】电器系统应急功能的优化研究和实际应用
- 我国电力系统混合整数规划优化引擎项目取得进展
- 电力系统中的大数据分析平台:创新能源管理方法
- 【电力系统优化调度】计及源荷两侧不确定性的含风电电力系统低碳调度(Matlab代码实现)
- sumlink储能辅助火电机组二次调频控制策略及容量优化配置与仿真文件,sumlink储能辅助火电机组二次调频控制策略及容量优化配置的仿真研究
热点动态分享
- 3031
- 2895
- 2822
- 2532
- 2342
- 1912
- 1674
- 1522
- 1504
- 1335

