
引言
在人工智能和机器学习快速发展的今天,Markdown作为一种轻量级标记语言,正变得越来越重要。它以其简单、清晰和可扩展的特性,成为了文档管理、内容呈现和LLM(大语言模型)辅助工作的首选格式。
然而,如何高效地将复杂的文件内容转换为Markdown格式,仍然是一个挑战。为了解决这一问题,今天给大家详细介绍微软最新推出的开源神器——MarkItDown。这款强大的自动化工具能够将多种文件格式一键转换为干净、结构化的Markdown文本。本文将全面解析MarkItDown的核心功能、使用教程、技术原理以及实战应用案例。
MarkItDown核心功能一览
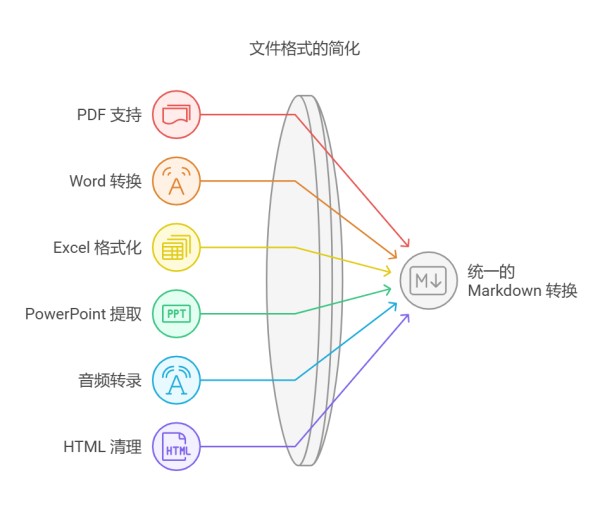
MarkItDown 是一款功能强大的文件到文本转换工具,支持多种文件格式的处理,能够将复杂的内容提取工作自动化。以下是其主要特点:
多格式支持
MarkItDown 可以处理以下文件类型:
自动化工作流
MarkItDown 通过自动化的方式减少人工干预,能够快速将多种格式的文件转换为统一的 Markdown 格式,极大地提高了工作效率。
高质量输出
与许多竞争对手相比,MarkItDown 提供了更加干净、结构化的输出,使其在文档处理和内容分析领域具有显著优势。
与大语言模型(LLM)的集成
MarkItDown 支持与 GPT-4 等大语言模型集成,可以生成丰富的描述性输出,例如对图片的分析和描述。
快速入门:MarkItDown安装教程
环境配置要求 Python 3.8或更高版本pip(Python包管理器) 一键安装命令使用pip快速安装:
pip install markitdown 1
开发者源码安装方式:
pip install -e . 1
MarkItDown使用教程:从入门到精通
命令行工具使用指南基础用法
markitdown path-to-file.pdf > document.md 1
通过这个简单命令,即可将PDF文件转换为Markdown格式。
指定输出文件
markitdown path-to-file.pdf -o output.md 1
使用管道传输内容
cat path-to-file.pdf | markitdown 1 Python API
基本用法
MarkitDown的Python API 使用起来非常简单,只需要导入 MarkItDown 类,然后调用 convert 方法即可,软件会自动根据文件类型选择合适的转换器。如下面代码所示,转换xlsx文件,直接给出文件路径就行:
from markitdown import MarkItDown md = MarkItDown() result = md.convert("test.xlsx") print(result.text_content) 12345
使用大语言模型生成描述性输出
我测试下来,对图片的OCR应该是还没有实现,所以只能选择调用大语言模型来生成描述性输出,微软出品,所以默认调用GPT-4模型。
from markitdown import MarkItDown from openai import OpenAI client = OpenAI(api_key="your-api-key") md = MarkItDown(llm_client=client, llm_model="gpt-4") result = md.convert("example.jpg") print(result.text_content) 1234567
MarkItDown技术实现深度解析
MarkItDown采用模块化设计,集成了多种高效的开源库,实现了强大的文件处理能力:
智能文件格式解析
PDF智能提取:采用pdfminer.six技术,精准提取PDF中的文本和结构化内容。Word文档转换:通过mammoth实现docx文件的完美转换。Excel表格处理:基于openpyxl的表格数据智能转换。PPT演示文稿:使用python-pptx提取幻灯片全部内容。HTML 与文本清理
使用 beautifulsoup4 解析 HTML 文档,提取结构化数据并清理多余的 HTML 标签。通过 markdownify 将 HTML 内容转换为 Markdown 格式,确保输出的简洁性和可读性。音频与视频处理
使用 pydub 处理音频文件格式(如 MP3、WAV),并通过 SpeechRecognition 库实现语音转文本功能。借助 youtube-transcript-api 提取 YouTube 视频的字幕内容,用于 Markdown 生成。文件类型检测
使用 puremagic 自动检测文件类型,确保输入文件的正确处理和兼容性。数据处理与验证
使用 pandas 提供高效的数据处理能力,特别适用于复杂的表格和数据文件。借助 pathvalidate 验证文件路径和文件名,确保输出文件的安全性和一致性。字符编码与兼容性
使用 charset-normalizer 自动处理文件的字符编码问题,确保多语言文本的正确提取。与 LLM 的集成
通过 openai 库与 GPT-4 等大语言模型交互,生成图片描述、语义分析和其他高级输出。网络请求支持
使用 requests 库下载远程文件或处理在线资源,为 Markdown 生成提供更多数据来源。可以看到,很多库都可以单独处理某种格式,而这个项目就是综合了以上技术和依赖库从而构建了 MarkItDown 的核心能力,使其能够高效地处理多种文件格式并生成高质量的 Markdown 输出。
MarkItDown实战应用指南
作为一款全能型文档转换工具,MarkItDown在各个领域都有出色表现:
自动化文档管理
轻松实现混合格式文件向Markdown的批量转换,完美支持版本控制。
智能内容索引与分析
提供干净的文本输出,为搜索引擎优化和文本分析提供支持。
内容处理管道
自动处理 ZIP 压缩包和其他混合格式数据,简化大规模数据处理流程。
无障碍工作流
转录音频,并从 HTML 页面提取结构化内容,为无障碍解决方案提供支持。
机器学习预处理
将多种文件格式转换为可读文本,用于与 LLM、摘要工具和情绪分析模型结合使用。
总结与展望
微软出品的MarkItDown不仅是一款功能强大的文件转换工具,更是提升工作效率的得力助手。通过自动化工作流、智能文本处理、元数据提取以及与大语言模型的深度集成,为现代文档处理和内容管理提供了革命性的解决方案。无论是文档管理、内容分析还是机器学习数据预处理,MarkItDown都能显著提升效率,是开发者和内容创作者的必备工具。

