数据预处理与分析技巧
数据清洗和预处理技巧:提高数据分析质量 #生活技巧# #学习技巧# #学术研究方法#
0.
数据准备包括 加载 清理 转换 重塑
pd和python标准库可以提供这个方法
往下要处理的包括缺失数据 重复数据 字符串操作 其他分析数据转换 多种方法合并 重塑数据集
1.
数据缺失
pd对象的所有描述性统计都默认不包括缺失的数据
1.1
先说这个缺失数据的检测
NaN 被称为哨兵值 就是用来表示缺失数据的
data=pd.Series([,,'NaN',])
data.isnull() 就会出现这个T或F 然后证明他们到底是不是空的
NaN None 都可以作为缺失值NA(not available)

1.2
再说说怎么过滤掉缺失数据
from numpy import nan as NA
data=pd.Series([1,NA,2,NA,3])
data.dropna()
会输出第0 2 4 行是 1 2 3
这个dropna可以过滤存在缺失数据的轴标签
可以通过参数设定阈值
这个data.dropna()==data[data.notnull()]
当data=pd.DataFrame{[ ]}的时候
df=data.dropna()
df会显示为去掉所有含NA的行
df=data.dropna(how='all')
df会显示为去掉那些所有值都是NA的行
df=data.dropna(axis=1,how='all')
df会显示为去掉那些所有值都是NA的列
df=data.dropna(thresh=2)
这是保留至少有2个非NA的行
然后额外说一个iloc和loc
df.iloc[4,1]=NA
就是把第5行 表头为1的列改成NA
df.loc[4,1]=NA
就是把索引为4的那行 表头为1的那列的值改成NA
1.3
填充缺失的数据 fillna
df.fillna(0)
就把NA填成0了
df.fillna({1:44,2:55})
就把表头是1的na值变成44 2的变成55 参数变成了一个字典
_=df.fillna(0,inplace=True)
前边的底杠 右边的inplace=T 都是为了对现有对象直接修改
df.fillna(method='ffill',limit=2)
无效数据追着上边有效数据走,就从上边往下带两个

2.
之前是属于数据的重排,之后是数据转换
2.1
df.duplicated() 去重
会返回一个Series 这个左边是01234 右边是T或者F 说明前边是否出现过一模一样的行
df.duplicated( ['列名','另一个列名'],keep='last')
这是说 去重这两列 然后倒着去重 从最后一个开始 如果这两列有一样的 就不显示
2.2
有一个Series s:(01234,z) 右侧值z是一个字典的键k z也是一个df的一列内容
如果要把z对应的k的v 插入到df中 一一对应
df['插入的列名']=s.map(字典kv)
map是一个实现元素及转换和其他数据清理工作的便捷方式
2.3
data.replace(不想要的值,替换值)
data.replace([不想要的值1,不想要的值2],替换值)
data.replace({不想要的值1:替换值1,不想要的值2:替换值2})
2.4
轴索引的重命名
df有index(即轴索引)和column(即表头)
有一个新的index的映射 ind=lambda x: x[:4].upper()
df.index.map(ind)就是新的索引
然后df.index=df.index.map(ind)就可以替换了
2.5
上述是改原来的版本
如果需要出来一个新的版本
df.rename(index=str.title,column=str.upper)
df.rename(index={要改的:改成的},column={要改的:改成的})
如果加入参数inplace=True 就是直接修改
3.
离散化和面元bin划分
3.1
设置一个bins=[1,3,7,9]
这个提供了1到3,4到7,8到9三个区间
原来有一个列表a=[3,5,4,7,8,2,8,6,9,2,1,6,6]
b=pd.cut(a,bins)
cut函数就是用来划分面元的
会得到一个Categorical对象
以及一个列表,里边是[ ( 1,3 ] , ( 4, 7 ], ..... , ( 4, 7 ] ,( 4, 7 ] ]
以及一个codes属性
b.codes
返回array( [ 0,1,.............,1,1 ] )
b.categories
返回这个b的相关情况
pd.value_counts(cats)
返回各个区间的计数
这个pd.value_counts(cats) 就是 pd.cut结果的面元计数
在cut时候 可以选择right=False 这样就不是左开右闭 是左闭右开
可以传递一个列表或者数组当做labels标签 设置自己的面元名称 可以不再显示左开右闭这种
group_names=['s','m','l']
pd.cut(a,bins,labels=group_names)
3.2
如果cut时候设置的是面元的数量而不是边界,那么就会根据数组的最大最小值计算等长面元
pd.cut(a,4,precision=2)
这是切a,切4份,小数点后边两位
pd.qcut(a,4)
把a切成四份 不是等长 但是数量相近
pd.qcut(a,[0 , 0.2 , 0.5 ,1 ])这叫分位数 就是 每份有多少
100个数第一梯队20个 然后30 50
3.3
检测和过滤和变换异常值 outlier


describe()函数 出来平均值标准差等等内容

看第二列哪个数绝对值大于3
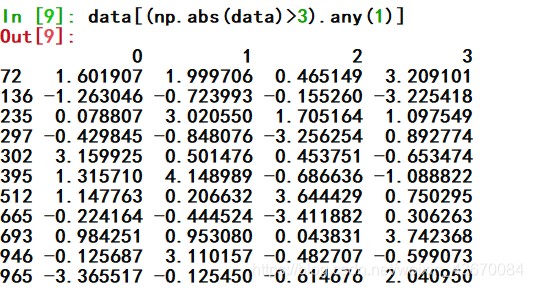
看有绝对值大于3的行

sign将区间限制在正负3以内

看看index=72的行什么样了

根据正负 可以生成1和-1
3.4
排列和随机采样
利用np.random.permutation可以对Series或者df的列进行随机重新排序

然后就可以基于iloc索引或者take函数使用该数组


可以选取子集
df.sample(n=3)
这就显现前三行
然后可以加一个参数 replace=True 可以产生能替换的样本 还可以重复
4.
将分类变量编程哑变量或者指标矩阵
哑变量又称虚拟变量 假如一个因素导致另一个因素变化 这就不需要哑变量
如果有一个因素导致多个变化,那么这之间的关系 用一个系数说不明白 就需要多个系数
这中间就要用到哑变量 他就由0 和1 表示
df=pd.DataFrame({ })
pd.get_dummies(df['key'])
就能生成这样一个各个位置 key是哪个的的df 有值的就是1 没有就是 0
如果给df加前缀prefix
就可以用get_dummies的prefix参数
dummies=pd.get_dummies(df['key'],prefix='keyOOOO')
df_with_dummy=df[['data1'].join(dummies)]
df_with_dummy就是索引不变 然后data1在第一个 后边是各个都有keyOOOO前缀的
网址:数据预处理与分析技巧 https://www.yuejiaxmz.com/news/view/828060
相关内容
大数据处理与分析数据分析案例:医疗数据分析与预测
Python数据分析——Pandas数据预处理
掌握Excel技巧,提升数据处理与分析效率的关键
智能监控系统的数据处理与分析
WPS表单数据汇总技巧:高效整理与分析
EXCEL函数及数据分析技巧整理备用
大数据智能分析理论与方法
提升AI文件阅读效率与数据分析能力的五个技巧
数据分析技能提升指南
随便看看
最新动态分享
- 食品添加剂使用新国标实施
- 生活中的化学
- 到底啥是“瘦肉精”?如何规避“瘦肉精”风险?
- 管理情绪的6个习惯:让生活更美好
- 情绪疏导:如何建立良好的情绪管理机制?
- 如何有效管理情绪,让生活更美好?
- 如何进行情绪管理?
- 怎样控制自己的情绪,控制情绪的八大方法
- 人生需要有效的进行情绪管理
- 情绪管理的5个妙招,你值得拥有
热点动态分享
- 2204
- 2151
- 1951
- 1868
- 1486
- 1465
- 1454
- 1248
- 1137
- 1112

