机器学习模型优化策略
深度学习模型的超参数调优策略 #生活技巧# #学习技巧# #深度学习技巧#
机器学习模型改进策略 正交化涵义理解设置单一实数评估指标怎么设置单一实数评估指标 选取合理的数据集选取同一分布的开发集和测试集选取尽量多的样本作为训练集 正交化应用与人类的表现对比可避免偏差算法超越人类表现 改进策略正交化涵义理解
正交化多用在线代表示里,指将一组线性无关系向量转化为正交系向量,使得在在某一维度上做的调整不对其他维度产生影响,可以从一个简单的直角坐标系去理解:
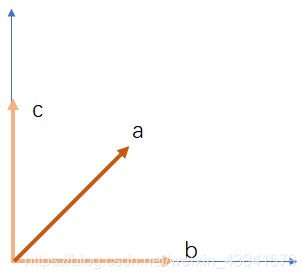
如果想要根据需要调整x,y坐标的值,直接调整向量a时,我们先获取一个x方向的期望值,但想获得y方向的期望值时,我们继续调整a,这时x方向的值就会跟着改变,这样我们就要反复的调整;但如果只用b去控制x的调整,用c去控制y的调整,两个之间不相互影响,那么我们就可以很方便的执行一些调整,因为他们之间相互独立没有影响。
设置单一实数评估指标
比如在训练阶段,我们有一个固定的开发集,我们使用了不同的方法训练出了多个分类器,我们要判断哪个分类器是最优分类器的时候,有一系列指标可供选择,比如precision,recall,不同的分类器在这两个指标上各有优劣,这时我们就要设定一个单一的指标来选择分类器,如F1;还有一些情况是通过一些指标的平均值在选择分类器。
怎么设置单一实数评估指标
比如我们做一个分类器训练的时候,我们想要最大化准确率,并且单个样本的训练时间要低于0.5s,这时候我们有两个指标要满足,那么我们可以这样解决问题:
设定优化指标为:maxmize(accuracy)
设定条件满指标为:traintime<0.5s
其他有需要考量的指标时,都统一列为条件满足指标,即分类器再满足指标上的性能只要达到设定的条件就可以。
选取合理的数据集
在训练机器学习模型时,一般设立三个数据集,训练集,开发集,测试集
开发集一般也叫做训练样本的留出验证集,测试集为真实应用场景中的数据
选取同一分布的开发集和测试集
首先谈一下开发集和测试集的选取,我们训练模型的优化过程指使得分类器在开发集上不断逼近上文所说的单一实数评估指标,可理解为一个靶心。当模型训练好之后,就要应用在测试集上做预测,试想,如果开发集和测试集是来自两个不同分布的数据集,就类似于另一个一个位置的靶心,那我们的模型在测试集上并不会表现很好。
所以在选择开发集和测试集的时候,要保证开发集和测试集是满足模型真实应用场景的同一数据分布。

选取尽量多的样本作为训练集
通常分割数据集时用7:3这样的方式将样本分为训练集和测试集,但是现在随着数据获取方式的增多我们可以获取大量的样本,而测试集只是应用于模型的验证评估,所以可以设置0.98:0.01:0.01这样的模式进行数据集划分,只设置一定量的样本作为验证用,把比较多的样本用于训练。
正交化应用
在机器学习过程中,上面提到的指标和样本集的选择就类似于一个正交化的过程,两者的选取并不互相影响最终的结果,通常我们可以通过下面步骤进行模型的训练
第1步:设定评估指标
第2步:选取开发集、测试集
那么什么时候改变评估指标,什么时候改变开发集就要根据实际的应用场景。
与人类的表现对比
在机器学习算法的发展历程中,常用来对比的标准是算法的表现是否能超过人类,在算法的衡量标准中,有个指标叫做贝叶斯误差,通常指算法达到最优时的误差,而人类的表现一般也比较接近贝叶斯误差,因此,在判断一个算法模型的优劣时,通常与人类的判断结果进行对比,判断算法在哪些方面有欠缺,以此,发现算法可以优化的方向。
可避免偏差
如果存在一种情况,两个分类器在不同样本上得到了相同的结果,比如说
训练集误差:8%
测试集误差10%
这时我们要朝哪个方向优化就可以参考上面提到的与人类的表现对比,如果人类在分类器A应用的数据上的识别表现误差为1%,那么我们认为分类器A存在高偏差,因为还没有接近于以人类表现近似的贝叶斯误差,这时我们可以向减小偏差的方向优化;如果人类在分类器B应用的数据上的识别表现误差为7.5%,那么我们认为分类器B存在高方差,因为训练集上的误差已经接近于贝叶斯误差,这时我们可以向减小方差的方向优化。
算法超越人类表现
上面有提到判断算法的性能常以人类的表现为标准进行判断,目标是使算法尽可能接近人类的表现,在一些结构化数据领域,比如金融风控,智能推荐,点击率预测等,算法往往能获得大量的数据,使训练后的最终性能超过人类的表现;但在一些感知领域,如语音识别,计算机视觉,计算机能超过人类的表现还是很困难的。
改进策略
上面提到了一些概念,比如正交化,挑选评估指标,选取训练集/开发集/测试集,以及与人类的表现对比,现在看一下具体的改进方法
第1步 选取单一实数评估指标
第2步 选取开发集/测试集/训练集
第3步 根据贝叶斯误差,训练误差,验证误差,评估可避免偏差和方差
假定我们的评估指标和训练集都已选定,如果我们判断模型的可避免偏差较大,需要改进,那就可以尝试使用:
使用更复杂的模型
训练更长的时间
使用Adam等优化方法
调整网络架构/超参数
如果我们判断模型的方差较大,需要改进,那就可以尝试使用:
增加数据样本/数据增强
正则化目标函数
调整网络架构/超参数
网址:机器学习模型优化策略 https://www.yuejiaxmz.com/news/view/830292
相关内容
特征选择与特征优化的策略:如何提高机器学习模型性能深度学习模型的24种优化策略
机器学习: LightGBM模型(优化版)——高效且强大的树形模型
强化学习中策略网络模型设计与优化技巧
深度学习模型中神经网络结构的优化策略
ChatGPT强化学习大杀器——近端策略优化(PPO)
联邦学习效率优化:同步与异步更新策略与模型集成方法
机器/深度学习模型最优化问题详解及优化算法汇总
分布式机器学习系统:设计原理、优化策略与实践经验
优化学习的策略.ppt
随便看看
最新动态分享
- SPSAUCE
- 小号斜直沥水垫 硅胶垫子 厨房垫 餐垫多功能隔水垫 桌面垫批发,价格,库存
- Joseph Joseph 英国Joseph Joseph 水槽可调节沥水垫/水槽防滑垫/创意厨具 85037 105元(需买2件,共210元)
- 沥水垫十大品牌排行榜
- Morphy Richards 摩飞 MR1032 硅胶厨具套装 7件套 99元
- 厨房沥水垫图片
- 硅藻泥厨房沥水垫推荐
- 厨房绿植装饰(美好生活从这里开始)
- 轻松养出美丽玫瑰吊兰,全面解析养殖方法与技巧
- 厨房水槽材质大揭秘,选对材质,让烹饪生活更美好
热点动态分享
- 2230
- 2203
- 1970
- 1888
- 1511
- 1481
- 1465
- 1250
- 1140
- 1114

