How Much Did It Rain? Ⅱ 使用机器学习进行预测(一)
购物时,询问价格可以用‘多少钱’(How much is it?) #生活知识# #旅游生活# #旅游语言学习#
How Much Did It Rain? Ⅱ 使用机器学习进行预测(一) 比赛信息基本介绍数据介绍 数据基本特点读取数据数据缺失情况Label分布 "How Much Did It Rain?Ⅱ"是在Kaggle上的15年的一次比赛,但是现在已经结束了。
针对机器学习实践,在这里对这个比赛的降雨量预测从数据处理分析到建模与预测展开详细的过程分析。
比赛信息
Kaggle上的比赛介绍链接为: How Much Did It Rain?Ⅱ,可以在Kaggle上下载相关的数据集。
在Kaggle上有详细的关于本次比赛的背景以及数据等具体介绍,这里会着重 ML 对比赛介绍等进行分析。
基本介绍
在气象雷达用于广泛的降雨量的预测在实际情况中并不完全吻合的背景下,提出了极化雷达,雷达发出竖直与水平方向的无线电脉冲,从而推断降雨的大小与类型:雨滴随着大小的增加而变平,而冰晶则倾向于垂直拉长
我们的数据是雷达获取的快照相关值我们的目的是预测每小时的雨量计总数比赛提示:训练数据集中的许多仪表值都是不可信的(例如,仪表可能会堵塞)!!这很重要,说明数据处理一定需要进行异常值分析,但其实没有提示,在拿到一个陌生数据时,缺失值、异常值分析处理肯定是必不可少的。
百度了一下关于雨量等级的划分:(这里是1d的,但我们预测的为1h的)
等级降雨量小雨1d降雨量小于10mm中雨1d降雨量10~25mm大雨1d降雨量25~50mm暴雨1d降雨量50~100mm大暴雨1d降雨量100~250mm特大暴雨1d降雨量在250mm以上大暴雨的情况已经算是比较少了,但其降雨量1h为4~10mm之间,在对降雨量有一定认识的情况下,再去看我们数据里的1h的降雨量,能对其数值有一定理解。
数据介绍
从Kaggle上下载的文件有四类:train.zip、test.zip、sample_solution.zip 、sample_dask.py,这里我们只用到train.zip,因为test.zip中没有标签,我们也无法得知预测出来的效果如何。
解压train.zip得到一个train.csv文件,数据量很大,有一千三百多万组数据,有二十三列 feature 和一列 label 。
查看数据可以看到数据的features的特征名,在分析数据前,我们可以查找资料分析各个数据对预测降雨量的影响以及一些定义。下面是train.csv中的标签,其中Expected为Label。
Index(['Id', 'minutes_past', 'radardist_km', 'Ref', 'Ref_5x5_10th', 'Ref_5x5_50th', 'Ref_5x5_90th', 'RefComposite', 'RefComposite_5x5_10th', 'RefComposite_5x5_50th', 'RefComposite_5x5_90th', 'RhoHV', 'RhoHV_5x5_10th', 'RhoHV_5x5_50th', 'RhoHV_5x5_90th', 'Zdr', 'Zdr_5x5_10th', 'Zdr_5x5_50th', 'Zdr_5x5_90th', 'Kdp', 'Kdp_5x5_10th', 'Kdp_5x5_50th', 'Kdp_5x5_90th', 'Expected'], dtype='object') 1234567
这里附上对特征标签查找的文献定义以及自己的理解并且将Kaggle上对部分标签值的解释的定义配在特征名的注释里:
Id : 每一个小时会从观测点得到一个1h降雨量的值,在这一个小时里面,可能会获取好几次雷达获取的数据信息,因此对同一个小时内获取的数据赋予相同的Id值;minutes_past: 每一个小时内获取的几次数据信息以0-60min算时间,获取数据的时间;radardist_km: 雷达获取的降雨的各类数据,雷达有很多个,而降雨量观测点只有一个,这个代表该雷达距离观测点的距离;Ref: 雷达反射率,只取决于云、雨滴谱的情况,反映了气象目标内部降水粒子的尺度和数密度,常用来表示气象目标的强度,雷达反射率因子Z只取决于气象目标本身而与雷达参数和距离无关;Ref_5x5_10th: 10th percentileRef_5x5_50th: 50th percentileRef_5x5_90th: 90th percentileRefComposite: 仪表上方垂直列中的最大反射率,没有查到特别相关的解释,但应该与反射率因子相近RefComposite_5x5_10thRefComposite_5x5_50thRefComposite_5x5_90thRhoHV: 极化测量信息相关系数取决于雷达散射体积内降雨目标物的纵横比的波动,当降雨目标物出现振动或者旋转,水平和垂直极化波后向散射信号强度之比会出现波动,相关系数同样会变小。因此,相关系数的测量信息揭示了降雨目标物非规则形状和非均匀分布的具体情况RhoHV_5x5_10thRhoHV_5x5_50thRhoHV_5x5_90thZdr: 小雨的气象粒子形状多为圆球状,统计上的差分反射率因子应为0,一般来说,雷达的仰角是固定的,降水与查分反射率的关系呈现正相关,但是不为线性相关,也具有比较大的波动性;Zdr_5x5_10thZdr_5x5_50thZdr_5x5_90thKdp: 这里没有找到对特定微分相位的一些解释,但是查阅到对差分相位的解释,同样是对相位特征的分析,可以以差分相位进行参考:在椭圆目标物比如大直径雨滴的情况下,水平极化波的相移要大于垂直极化波的相位变化率。于是,单位距离的水平极化波传播相移大于垂直极化波的传播相移。水平和垂直极化波的振幅之间的差异称为雷达传播相位变化;Kdp_5x5_10thKdp_5x5_50thKdp_5x5_90thExpected: 观测点获取的该小时的降雨量(mm)对5x5_10,5x5_50,5x5_90的解释:由于收集在不同空间其反射率等参数值是不一样的,所以采用的是5×5(应该是km)空间中,所采取到的参数数据排序后的第十个百分位、第五十个百分位(类似于中位数)、第九十个百分位
总结一下: Ref、RefComposite关于粒子的大小与密度; RHoHV、Zdr、kdp关于粒子的形状与分布
数据基本特点
了解了数据的各类信息后,我们需要写代码读取train.csv的数据,了解其基本情况:数据特征值类型、缺失值情况、Label分布。
读取数据
由于数据是.csv类型,这里采用pandas库的pandas.read_csv接口进行读写,读取后以DataFrame格式保存(pandas具体教程在这: Pandas读取CSV详细介绍),可以采用.info()查看DataFrame基本信息和.head(num)查看前num行数据。
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv) train = pd.read_csv("../input/how-much-did-it-rain-ii/train.zip") x_train = train.iloc[:,1:-1] #Id不计入 object_columns_num = x_train.dtypes[x_train.dtypes != 'object'].value_counts().sum() print(f"数据有{x_train.shape[1]}列特征值") print(f"其中有{object_columns_num}个object特征,{x_train.shape[1]-object_columns_num}个非object数据") print(f"训练集有{train.shape[0]}行") 12345678
output:
数据有22列特征值 其中有22个object特征,0个非object数据 训练集有13765201行 123
数据量极大、所有特征值都是连续值(这里没有将Id算入)
数据缺失情况
数据的缺失情况是一定要查看的,无论在处理什么数据,缺失值基本都会对训练效果有影响(但 RF 具有很强的处理缺失值的能力)。
pd库中对DataFrame有专门的查看缺失值的函数,可以直接使用
Null_num = x_train.isnull().sum() Null_percent = x_train.isnull().sum()/x_train.shape[0]*100 Null_condition = pd.concat([pd.DataFrame(Null_num),pd.DataFrame(Null_percent)],axis=1) Null_condition.columns = ['Null_num','Null_percent'] print(Null_condition) 12345
output:
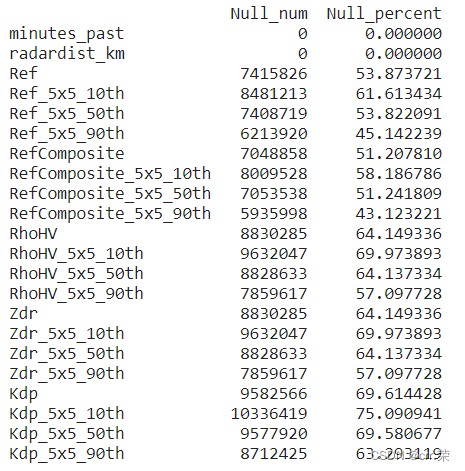
缺失情况十分严重,数据可用性很低!!!(数据又大又差)
Label分布
图形统计分析,将缺失值处理后的数据长度生成一组序列作为横坐标,其Label作为纵坐标,绘制散点图观测其标签值分布;
import matplotlib.pyplot as plt plt.scatter([i for i in range(len(y))],train.iloc[:,23]) plt.show() 123
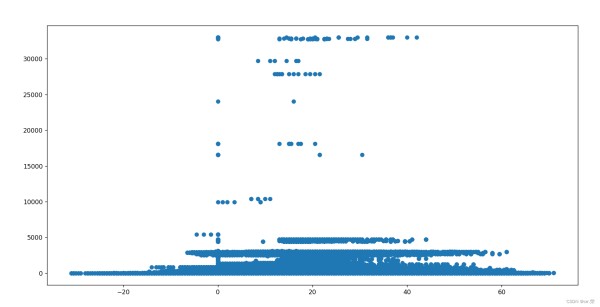
异常情况也比较严重!!!特别是竟然还有30000mm的1h降水量,太离谱la
使用seaborn库中的绘图函数绘制Label的直方图和QQ图:QQ图详解参考这里,我绘制了labels和log(labels)的图,方便查看其分布(若自身不为正态分布,对其取log,很有可能偏向正态分布)
# 因为数据中相同Id的预测值是相同的,所以要先删除Expected的相同值 y = train.iloc[:,23].drop_duplicates(keep='first') fig = plt.figure(figsize=(20,10)) plt.subplot2grid((2,2),(0,0)) sns.distplot(y,color='y',fit=norm) plt.subplot2grid((2,2),(0,1)) sns.distplot(np.log(y),color='y',fit=norm) plt.subplot2grid((2,2),(1,0)) res = probplot(y,plot=plt) plt.subplot2grid((2,2),(1,1)) res = probplot(np.log(y),plot=plt) plt.show() 12345678910111213
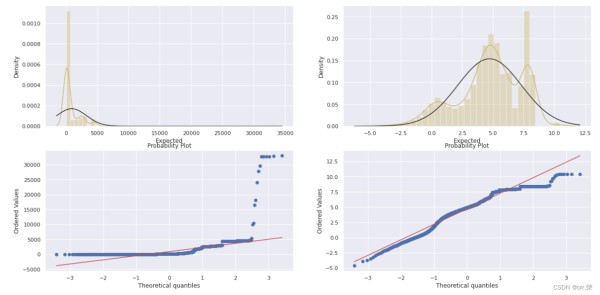
Label及Log(Label)的分布都满足正态分布,为了减少计算量,这里不对Label取对数处理。
网址:How Much Did It Rain? Ⅱ 使用机器学习进行预测(一) https://www.yuejiaxmz.com/news/view/246592
相关内容
出国英语必备口语900句 生活交际基本对话家庭生活英语作文(精选27篇)
关于提高学习效率的英语作文(通用5篇)
写科技改变生活的英语作文(精选8篇)
我生活中的变化英语作文(通用36篇)
How to prepare and invest for retirement
My Weekend 我的周末英语作文(通用20篇)
绿色生活保护环境的英语作文范文(精选20篇)
复试口语模板之大学生活与经历
大学生如何管理时间英语作文
随便看看
最新动态分享
- 才知道健身房这么脏,看完评论区,以后去健身房要小心点了
- 健身房管理规定
- 清洗健身器材 营造整洁环境
- 清洁健身器材共享文明健康
- 公共场所健身器微生物污染严重 应加强卫生监管
- 负责健身房及更衣室,()的清洁卫生工作,保持环境的整洁和空气的清新。
- 轻松代肝:实现二次元手游日常任务自动化的全攻略
- 摩托罗拉Moto AI新功能亮相:点咖啡、叫网约车一键搞定
- 使用Lua脚本自动化你的日常任务
- 人工智能的崭新角色:提升日常工作的效率与体验
热点动态分享
- 452
- 291
- 273
- 217
- 202
- 178
- 158
- 141
- 117
- 106

